 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Question Answering over Knowledge Graphs with Transformer and Graph Attention Networks
Apr 04, 2021
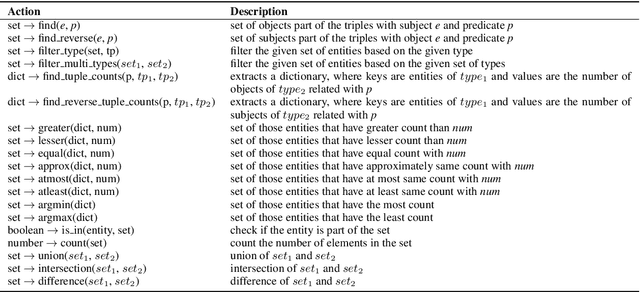
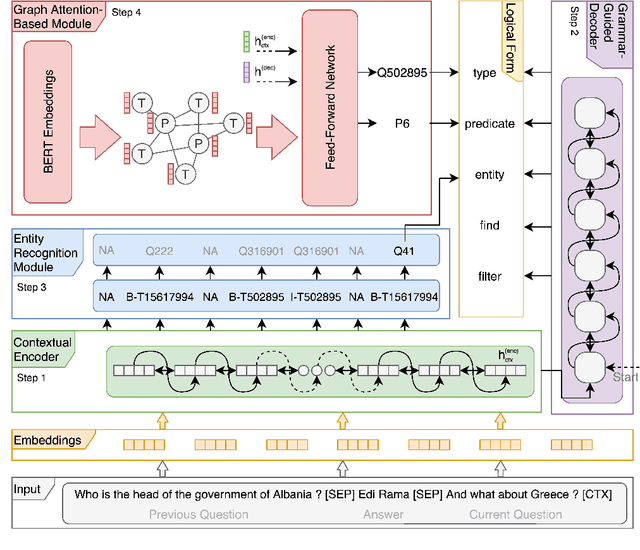
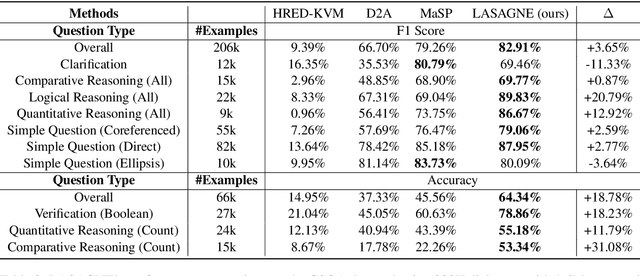
This paper addresses the task of (complex) conversational question answering over a knowledge graph. For this task, we propose LASAGNE (muLti-task semAntic parSing with trAnsformer and Graph atteNtion nEtworks). It is the first approach, which employs a transformer architecture extended with Graph Attention Networks for multi-task neural semantic parsing. LASAGNE uses a transformer model for generating the base logical forms, while the Graph Attention model is used to exploit correlations between (entity) types and predicates to produce node representations. LASAGNE also includes a novel entity recognition module which detects, links, and ranks all relevant entities in the question context. We evaluate LASAGNE on a standard dataset for complex sequential question answering, on which it outperforms existing baseline averages on all question types. Specifically, we show that LASAGNE improves the F1-score on eight out of ten question types; in some cases, the increase in F1-score is more than 20% compared to the state of the art.
Context Transformer with Stacked Pointer Networks for Conversational Question Answering over Knowledge Graphs
Mar 13, 2021
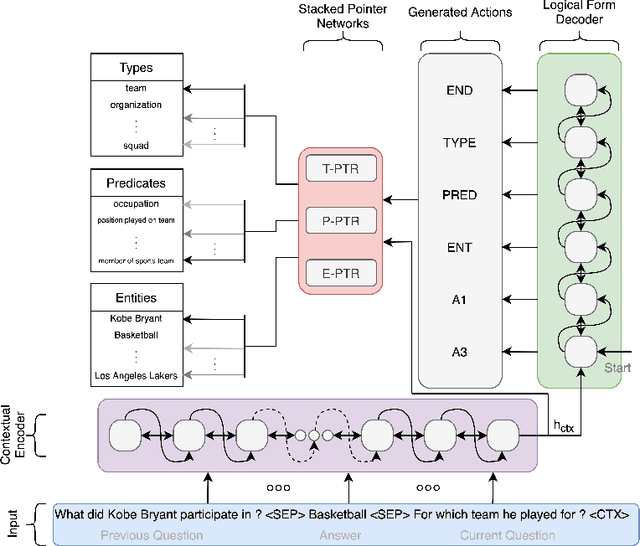
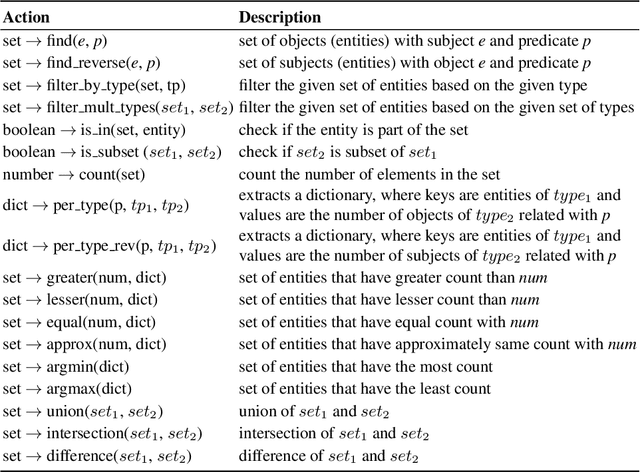
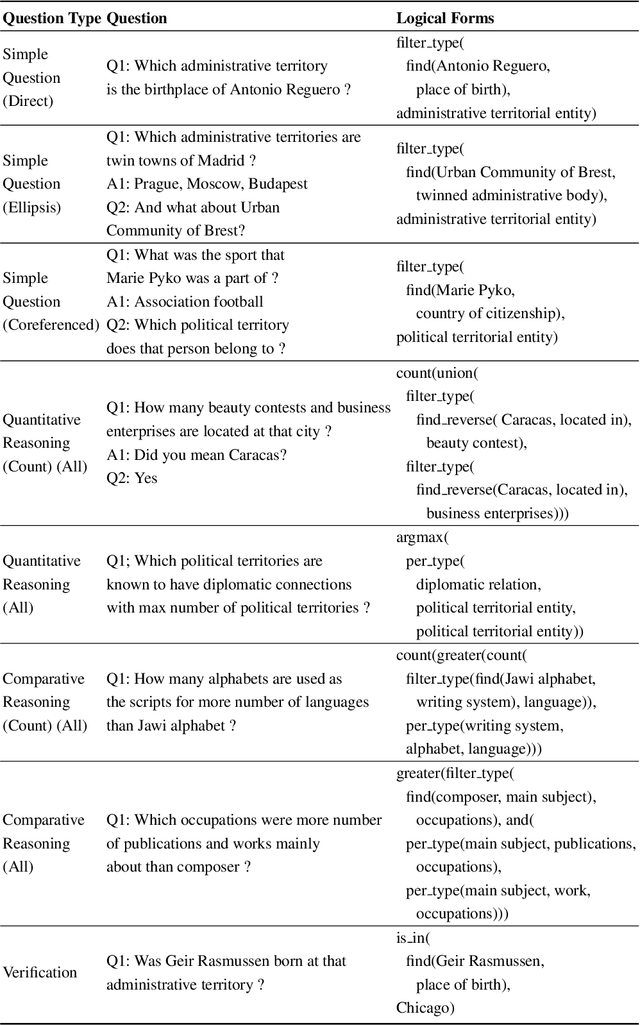
Neural semantic parsing approaches have been widely used for Question Answering (QA) systems over knowledge graphs. Such methods provide the flexibility to handle QA datasets with complex queries and a large number of entities. In this work, we propose a novel framework named CARTON, which performs multi-task semantic parsing for handling the problem of conversational question answering over a large-scale knowledge graph. Our framework consists of a stack of pointer networks as an extension of a context transformer model for parsing the input question and the dialog history. The framework generates a sequence of actions that can be executed on the knowledge graph. We evaluate CARTON on a standard dataset for complex sequential question answering on which CARTON outperforms all baselines. Specifically, we observe performance improvements in F1-score on eight out of ten question types compared to the previous state of the art. For logical reasoning questions, an improvement of 11 absolute points is reached.
Direct Mappings between RDF and Property Graph Databases
Dec 04, 2019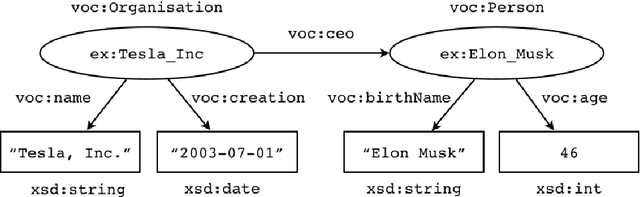
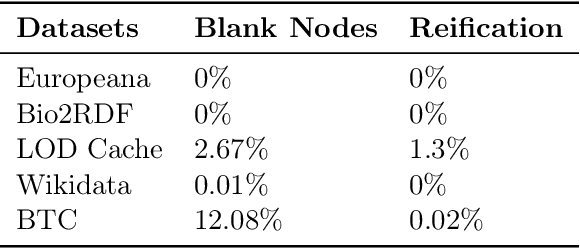
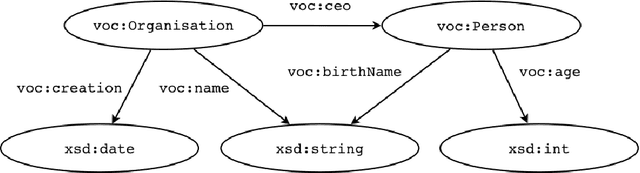
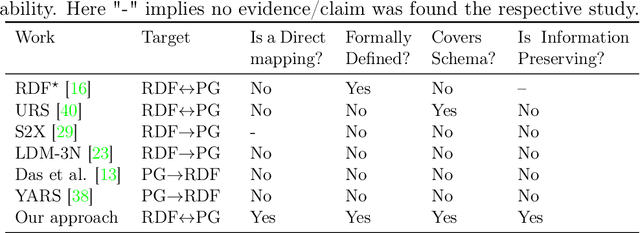
Resource Description Framework (RDF) triplestores and Property Graph (PG) database systems are two approaches for data management that are based on modeling, storing and querying graph-like data. Given the heterogeneity between these systems, it becomes necessary to develop methods to allow interoperability among them. While there exist some approaches to exchange data and schema between RDF and PG databases, they lack compatibility and even a solid formal foundation. In this paper, we study the semantic interoperability between RDF and PG databases. Specifically, we present two direct mappings (schema-dependent and schema-independent) for transforming an RDF database into a PG database. We show that the proposed mappings possess the fundamental properties of semantics preservation and information preservation. The existence of both mappings allows us to conclude that the PG data model subsumes the expressiveness or information capacity of the RDF data model.
The Query Translation Landscape: a Survey
Oct 07, 2019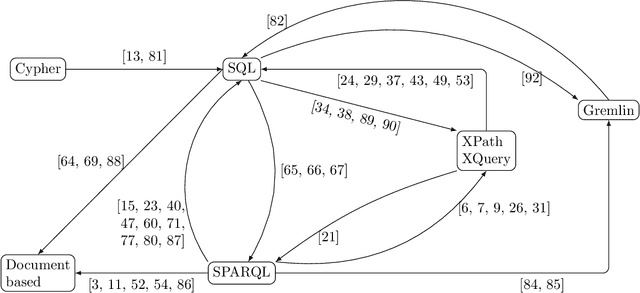
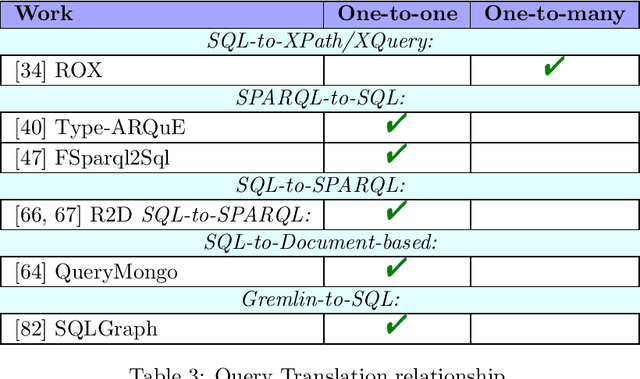
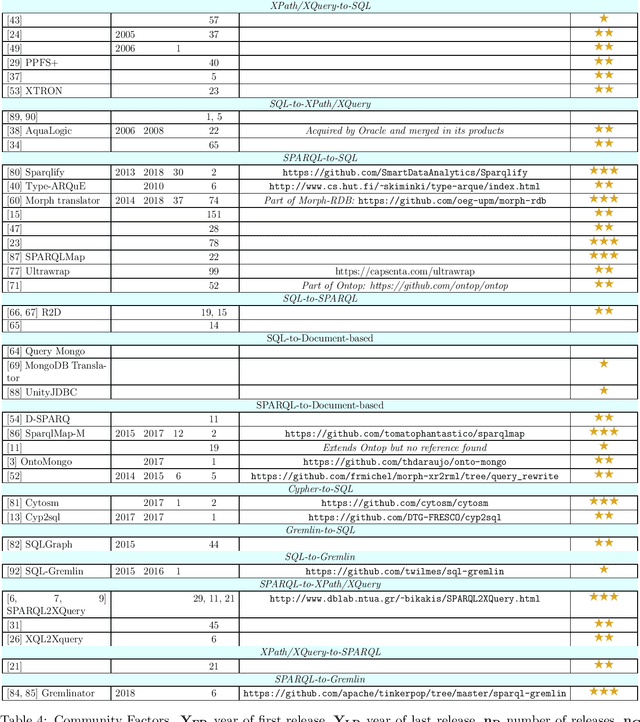
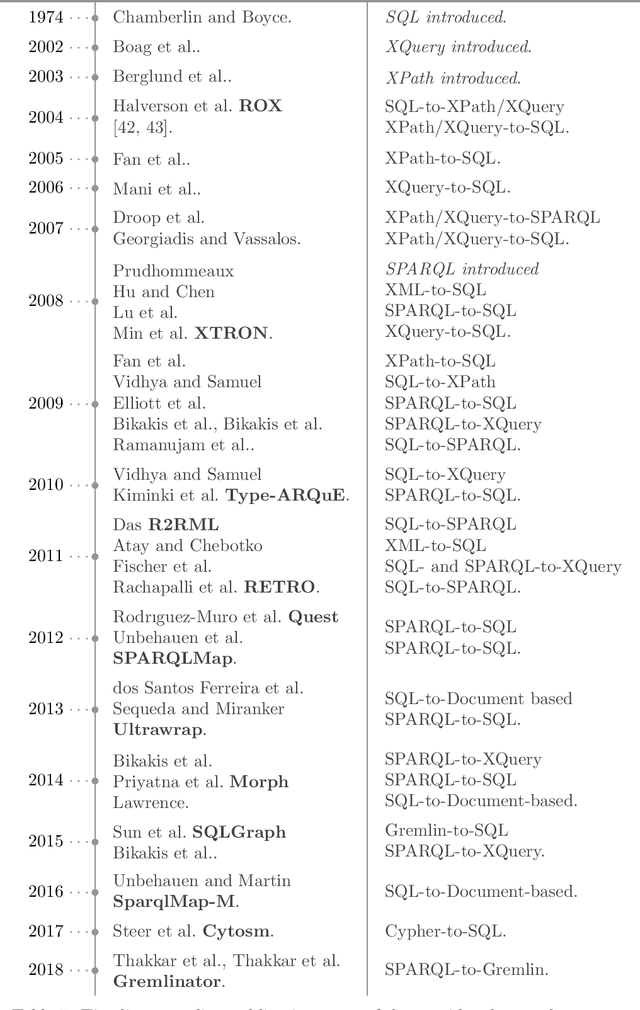
Whereas the availability of data has seen a manyfold increase in past years, its value can be only shown if the data variety is effectively tackled ---one of the prominent Big Data challenges. The lack of data interoperability limits the potential of its collective use for novel applications. Achieving interoperability through the full transformation and integration of diverse data structures remains an ideal that is hard, if not impossible, to achieve. Instead, methods that can simultaneously interpret different types of data available in different data structures and formats have been explored. On the other hand, many query languages have been designed to enable users to interact with the data, from relational, to object-oriented, to hierarchical, to the multitude emerging NoSQL languages. Therefore, the interoperability issue could be solved not by enforcing physical data transformation, but by looking at techniques that are able to query heterogeneous sources using one uniform language. Both industry and research communities have been keen to develop such techniques, which require the translation of a chosen 'universal' query language to the various data model specific query languages that make the underlying data accessible. In this article, we survey more than forty query translation methods and tools for popular query languages, and classify them according to eight criteria. In particular, we study which query language is a most suitable candidate for that 'universal' query language. Further, the results enable us to discover the weakly addressed and unexplored translation paths, to discover gaps and to learn lessons that can benefit future research in the area.
Approaches for Sentiment Analysis on Twitter: A State-of-Art study
Dec 03, 2015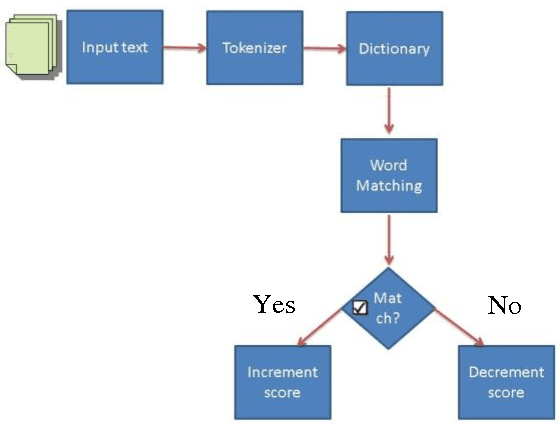

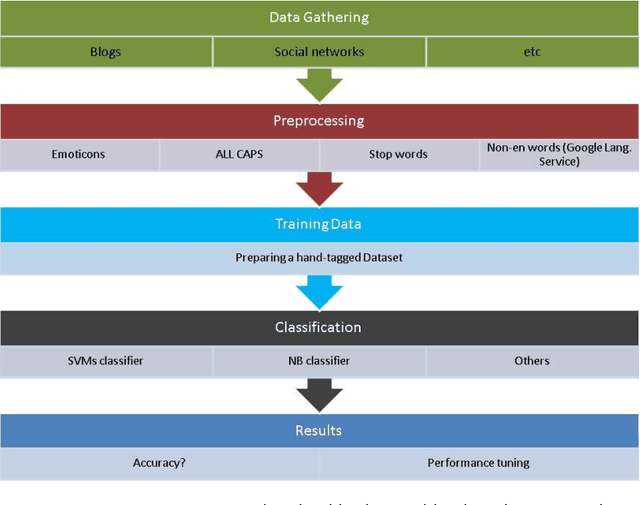

Microbloging is an extremely prevalent broadcast medium amidst the Internet fraternity these days. People share their opinions and sentiments about variety of subjects like products, news, institutions, etc., every day on microbloging websites. Sentiment analysis plays a key role in prediction systems, opinion mining systems, etc. Twitter, one of the microbloging platforms allows a limit of 140 characters to its users. This restriction stimulates users to be very concise about their opinion and twitter an ocean of sentiments to analyze. Twitter also provides developer friendly streaming API for data retrieval purpose allowing the analyst to search real time tweets from various users. In this paper, we discuss the state-of-art of the works which are focused on Twitter, the online social network platform, for sentiment analysis. We survey various lexical, machine learning and hybrid approaches for sentiment analysis on Twitter.