 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Query Translation Landscape: a Survey
Oct 07, 2019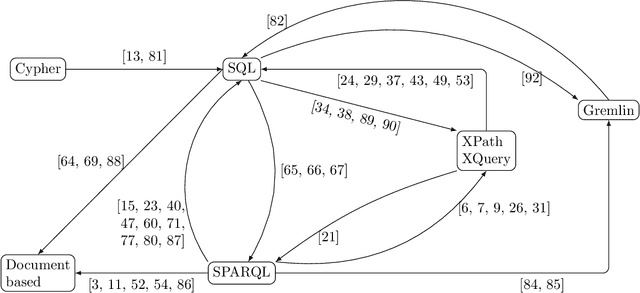
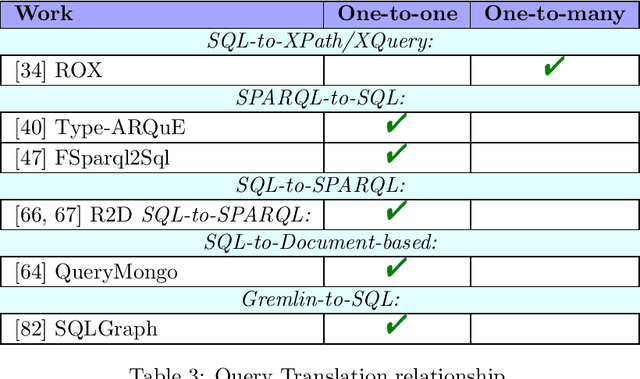
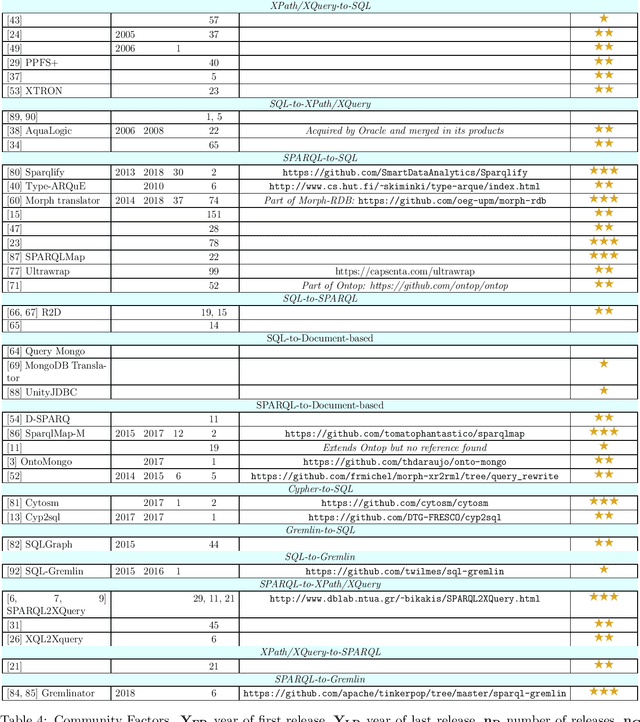
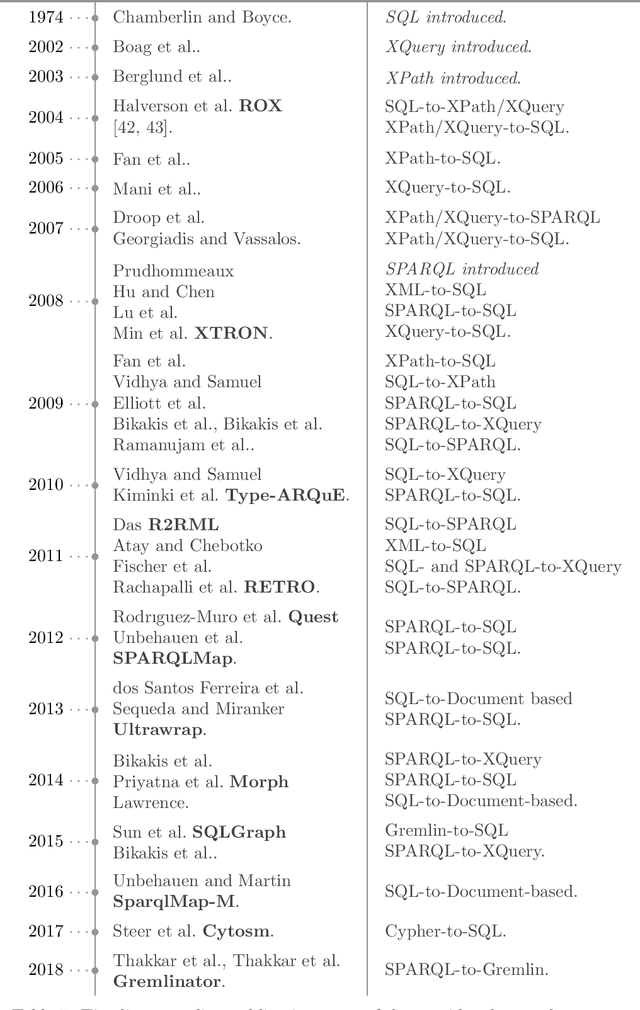
Whereas the availability of data has seen a manyfold increase in past years, its value can be only shown if the data variety is effectively tackled ---one of the prominent Big Data challenges. The lack of data interoperability limits the potential of its collective use for novel applications. Achieving interoperability through the full transformation and integration of diverse data structures remains an ideal that is hard, if not impossible, to achieve. Instead, methods that can simultaneously interpret different types of data available in different data structures and formats have been explored. On the other hand, many query languages have been designed to enable users to interact with the data, from relational, to object-oriented, to hierarchical, to the multitude emerging NoSQL languages. Therefore, the interoperability issue could be solved not by enforcing physical data transformation, but by looking at techniques that are able to query heterogeneous sources using one uniform language. Both industry and research communities have been keen to develop such techniques, which require the translation of a chosen 'universal' query language to the various data model specific query languages that make the underlying data accessible. In this article, we survey more than forty query translation methods and tools for popular query languages, and classify them according to eight criteria. In particular, we study which query language is a most suitable candidate for that 'universal' query language. Further, the results enable us to discover the weakly addressed and unexplored translation paths, to discover gaps and to learn lessons that can benefit future research in the area.