 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Empathy: How AI Chatbots Shape Conversation Perception
Nov 19, 2024



As AI chatbots become more human-like by incorporating empathy, understanding user-centered perceptions of chatbot empathy and its impact on conversation quality remains essential yet under-explored. This study examines how chatbot identity and perceived empathy influence users' overall conversation experience. Analyzing 155 conversations from two datasets, we found that while GPT-based chatbots were rated significantly higher in conversational quality, they were consistently perceived as less empathetic than human conversational partners. Empathy ratings from GPT-4o annotations aligned with users' ratings, reinforcing the perception of lower empathy in chatbots. In contrast, 3 out of 5 empathy models trained on human-human conversations detected no significant differences in empathy language between chatbots and humans. Our findings underscore the critical role of perceived empathy in shaping conversation quality, revealing that achieving high-quality human-AI interactions requires more than simply embedding empathetic language; it necessitates addressing the nuanced ways users interpret and experience empathy in conversations with chatbots.
Explicit and Implicit Large Language Model Personas Generate Opinions but Fail to Replicate Deeper Perceptions and Biases
Jun 20, 2024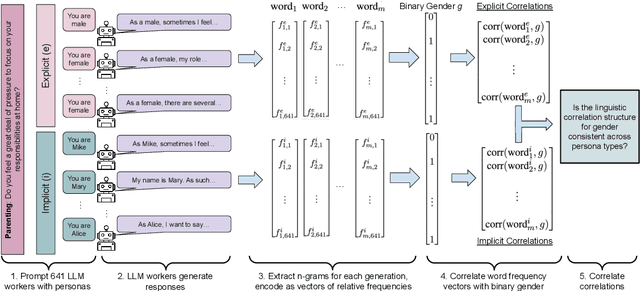



Large language models (LLMs) are increasingly being used in human-centered social scientific tasks, such as data annotation, synthetic data creation, and engaging in dialog. However, these tasks are highly subjective and dependent on human factors, such as one's environment, attitudes, beliefs, and lived experiences. Thus, employing LLMs (which do not have such human factors) in these tasks may result in a lack of variation in data, failing to reflect the diversity of human experiences. In this paper, we examine the role of prompting LLMs with human-like personas and asking the models to answer as if they were a specific human. This is done explicitly, with exact demographics, political beliefs, and lived experiences, or implicitly via names prevalent in specific populations. The LLM personas are then evaluated via (1) subjective annotation task (e.g., detecting toxicity) and (2) a belief generation task, where both tasks are known to vary across human factors. We examine the impact of explicit vs. implicit personas and investigate which human factors LLMs recognize and respond to. Results show that LLM personas show mixed results when reproducing known human biases, but generate generally fail to demonstrate implicit biases. We conclude that LLMs lack the intrinsic cognitive mechanisms of human thought, while capturing the statistical patterns of how people speak, which may restrict their effectiveness in complex social science applications.
Using LLMs to Aid Annotation and Collection of Clinically-Enriched Data in Bipolar Disorder and Schizophrenia
Jun 18, 2024
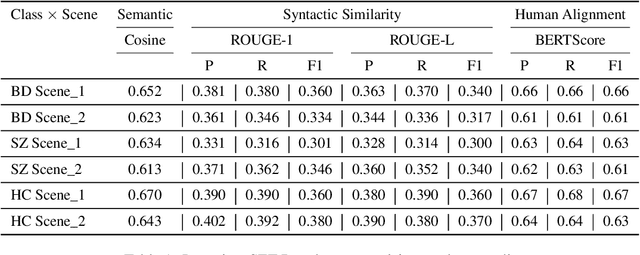
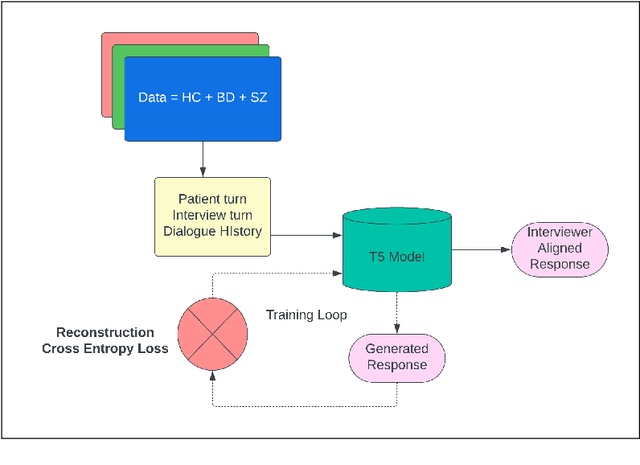
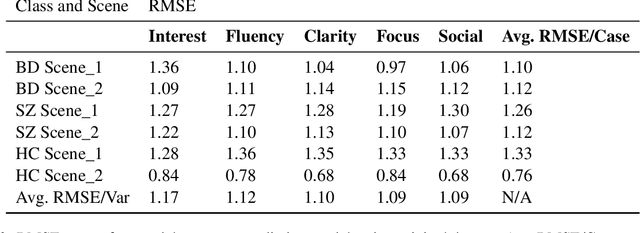
NLP in mental health has been primarily social media focused. Real world practitioners also have high case loads and often domain specific variables, of which modern LLMs lack context. We take a dataset made by recruiting 644 participants, including individuals diagnosed with Bipolar Disorder (BD), Schizophrenia (SZ), and Healthy Controls (HC). Participants undertook tasks derived from a standardized mental health instrument, and the resulting data were transcribed and annotated by experts across five clinical variables. This paper demonstrates the application of contemporary language models in sequence-to-sequence tasks to enhance mental health research. Specifically, we illustrate how these models can facilitate the deployment of mental health instruments, data collection, and data annotation with high accuracy and scalability. We show that small models are capable of annotation for domain-specific clinical variables, data collection for mental-health instruments, and perform better then commercial large models.
Vernacular? I Barely Know Her: Challenges with Style Control and Stereotyping
Jun 18, 2024



Large Language Models (LLMs) are increasingly being used in educational and learning applications. Research has demonstrated that controlling for style, to fit the needs of the learner, fosters increased understanding, promotes inclusion, and helps with knowledge distillation. To understand the capabilities and limitations of contemporary LLMs in style control, we evaluated five state-of-the-art models: GPT-3.5, GPT-4, GPT-4o, Llama-3, and Mistral-instruct- 7B across two style control tasks. We observed significant inconsistencies in the first task, with model performances averaging between 5th and 8th grade reading levels for tasks intended for first-graders, and standard deviations up to 27.6. For our second task, we observed a statistically significant improvement in performance from 0.02 to 0.26. However, we find that even without stereotypes in reference texts, LLMs often generated culturally insensitive content during their tasks. We provide a thorough analysis and discussion of the results.
Lived Experience Matters: Automatic Detection of Stigma toward People Who Use Substances on Social Media
Feb 04, 2023

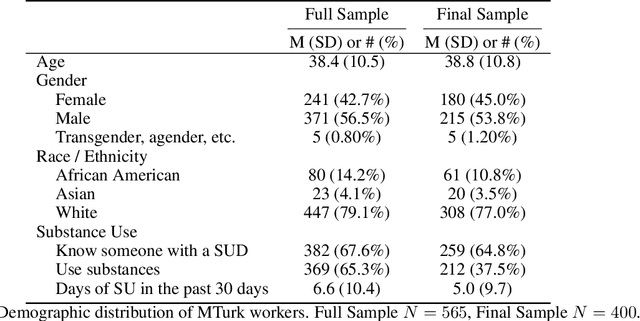
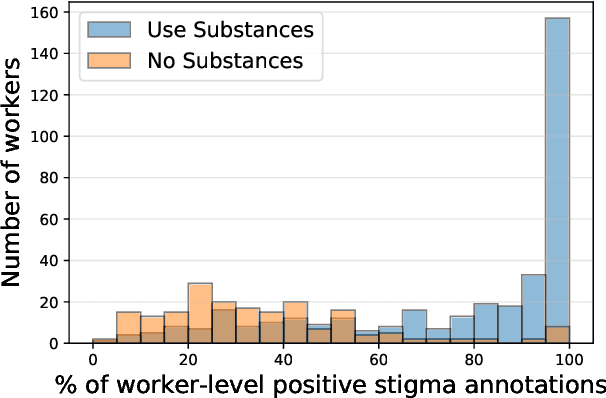
Stigma toward people who use substances (PWUS) is a leading barrier to seeking treatment. Further, those in treatment are more likely to drop out if they experience higher levels of stigmatization. While related concepts of hate speech and toxicity, including those targeted toward vulnerable populations, have been the focus of automatic content moderation research, stigma and, in particular, people who use substances have not. This paper explores stigma toward PWUS using a data set of roughly 5,000 public Reddit posts. We performed a crowd-sourced annotation task where workers are asked to annotate each post for the presence of stigma toward PWUS and answer a series of questions related to their experiences with substance use. Results show that workers who use substances or know someone with a substance use disorder are more likely to rate a post as stigmatizing. Building on this, we use a supervised machine learning framework that centers workers with lived substance use experience to label each Reddit post as stigmatizing. Modeling person-level demographics in addition to comment-level language results in a classification accuracy (as measured by AUC) of 0.69 -- a 17% increase over modeling language alone. Finally, we explore the linguist cues which distinguish stigmatizing content: PWUS substances and those who don't agree that language around othering ("people", "they") and terms like "addict" are stigmatizing, while PWUS (as opposed to those who do not) find discussions around specific substances more stigmatizing. Our findings offer insights into the nature of perceived stigma in substance use. Additionally, these results further establish the subjective nature of such machine learning tasks, highlighting the need for understanding their social contexts.
Cross-Platform Difference in Facebook and Text Messages Language Use: Illustrated by Depression Diagnosis
Feb 09, 2022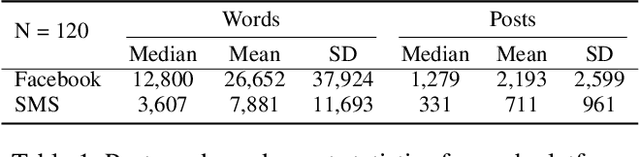
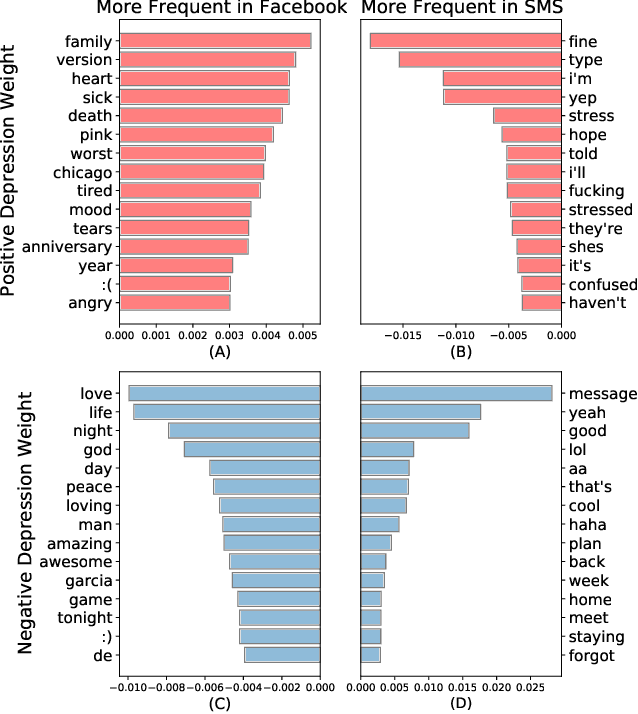
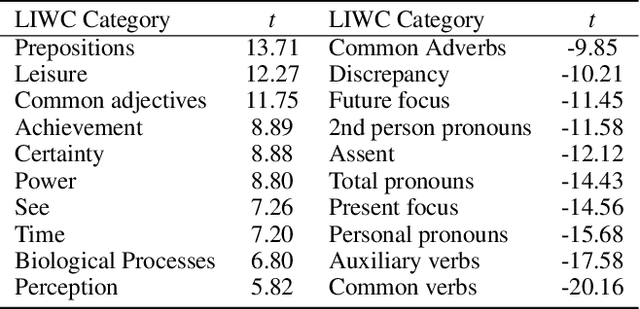

How does language differ across one's Facebook status updates vs. one's text messages (SMS)? In this study, we show how Facebook and SMS use differs in psycho-linguistic characteristics and how these differences drive downstream analyses with an illustration of depression diagnosis. We use a sample of consenting participants who shared Facebook status updates, SMS data, and answered a standard psychological depression screener. We quantify domain differences using psychologically driven lexical methods and find that language on Facebook involves more personal concerns, experiences, and content features while the language in SMS contains more informal and style features. Next, we estimate depression from both text domains, using a depression model trained on Facebook data, and find a drop in accuracy when predicting self-reported depression assessments from the SMS-based depression estimates. Finally, we evaluate a simple domain adaption correction based on words driving the cross-platform differences and applied it to the SMS-derived depression estimates, resulting in significant improvement in prediction. Our work shows the Facebook vs. SMS difference in language use and suggests the necessity of cross-domain adaption for text-based predictions.
Twitter Corpus of the #BlackLivesMatter Movement And Counter Protests: 2013 to 2020
Sep 28, 2020
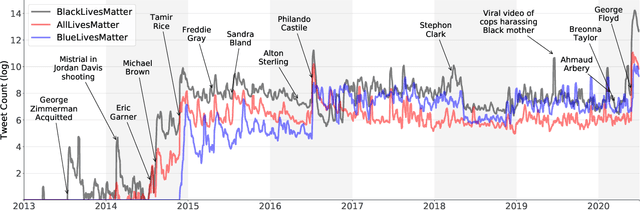
Black Lives Matter (BLM) is a grassroots movement protesting violence towards Black individuals and communities with a focus on police brutality. The movement has gained significant media and political attention following the killings of Ahmaud Arbery, Breonna Taylor, and George Floyd and the shooting of Jacob Blake in 2020. Due to its decentralized nature, the #BlackLivesMatter social media hashtag has come to both represent the movement and been used as a call to action. Similar hashtags have appeared to counter the BLM movement, such as #AllLivesMatter and #BlueLivesMatter. We introduce a data set of 41.8 million tweets from 10 million users which contain one of the following keywords: BlackLivesMatter, AllLivesMatter and BlueLivesMatter. This data set contains all currently available tweets from the beginning of the BLM movement in 2013 to June 2020. We summarize the data set and show temporal trends in use of both the BlackLivesMatter keyword and keywords associated with counter movements. In the past, similarly themed, though much smaller in scope, BLM data sets have been used for studying discourse in protest and counter protest movements, predicting retweets, examining the role of social media in protest movements and exploring narrative agency. This paper open-sources a large-scale data set to facilitate research in the areas of computational social science, communications, political science, natural language processing, and machine learning.