 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLived Experience Matters: Automatic Detection of Stigma toward People Who Use Substances on Social Media
Feb 04, 2023

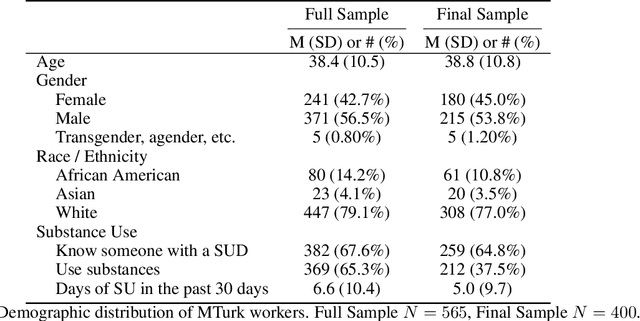
Stigma toward people who use substances (PWUS) is a leading barrier to seeking treatment. Further, those in treatment are more likely to drop out if they experience higher levels of stigmatization. While related concepts of hate speech and toxicity, including those targeted toward vulnerable populations, have been the focus of automatic content moderation research, stigma and, in particular, people who use substances have not. This paper explores stigma toward PWUS using a data set of roughly 5,000 public Reddit posts. We performed a crowd-sourced annotation task where workers are asked to annotate each post for the presence of stigma toward PWUS and answer a series of questions related to their experiences with substance use. Results show that workers who use substances or know someone with a substance use disorder are more likely to rate a post as stigmatizing. Building on this, we use a supervised machine learning framework that centers workers with lived substance use experience to label each Reddit post as stigmatizing. Modeling person-level demographics in addition to comment-level language results in a classification accuracy (as measured by AUC) of 0.69 -- a 17% increase over modeling language alone. Finally, we explore the linguist cues which distinguish stigmatizing content: PWUS substances and those who don't agree that language around othering ("people", "they") and terms like "addict" are stigmatizing, while PWUS (as opposed to those who do not) find discussions around specific substances more stigmatizing. Our findings offer insights into the nature of perceived stigma in substance use. Additionally, these results further establish the subjective nature of such machine learning tasks, highlighting the need for understanding their social contexts.
Cross-Platform Difference in Facebook and Text Messages Language Use: Illustrated by Depression Diagnosis
Feb 09, 2022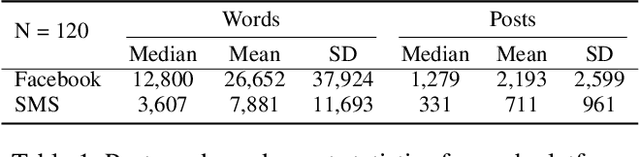
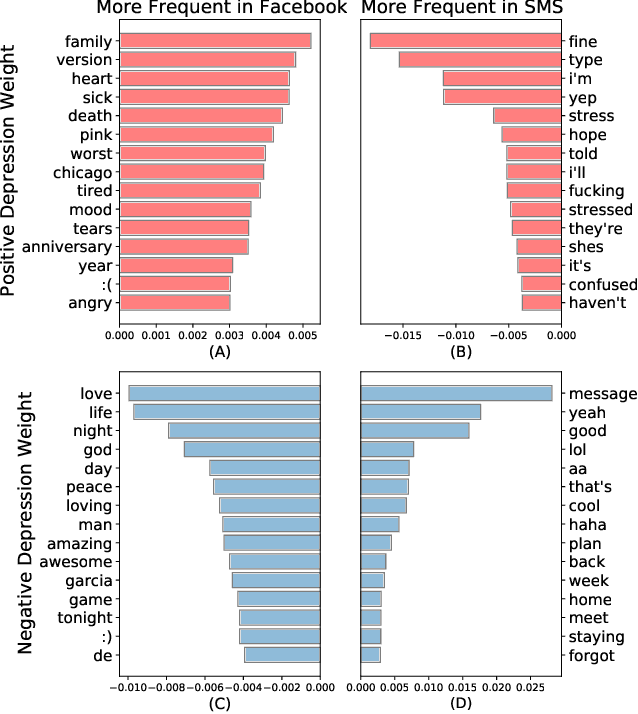
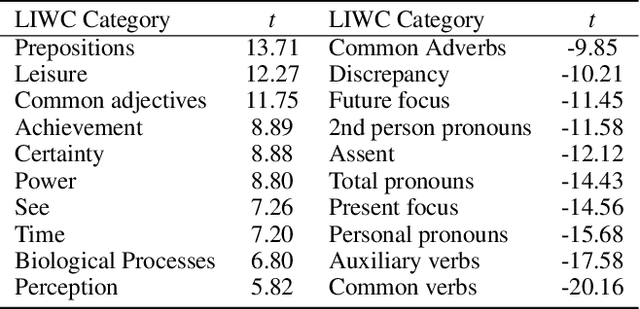

How does language differ across one's Facebook status updates vs. one's text messages (SMS)? In this study, we show how Facebook and SMS use differs in psycho-linguistic characteristics and how these differences drive downstream analyses with an illustration of depression diagnosis. We use a sample of consenting participants who shared Facebook status updates, SMS data, and answered a standard psychological depression screener. We quantify domain differences using psychologically driven lexical methods and find that language on Facebook involves more personal concerns, experiences, and content features while the language in SMS contains more informal and style features. Next, we estimate depression from both text domains, using a depression model trained on Facebook data, and find a drop in accuracy when predicting self-reported depression assessments from the SMS-based depression estimates. Finally, we evaluate a simple domain adaption correction based on words driving the cross-platform differences and applied it to the SMS-derived depression estimates, resulting in significant improvement in prediction. Our work shows the Facebook vs. SMS difference in language use and suggests the necessity of cross-domain adaption for text-based predictions.