 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing LLMs to Aid Annotation and Collection of Clinically-Enriched Data in Bipolar Disorder and Schizophrenia
Jun 18, 2024
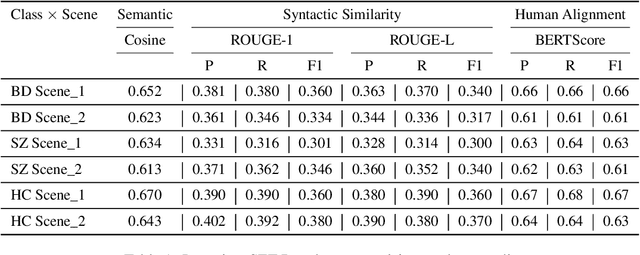
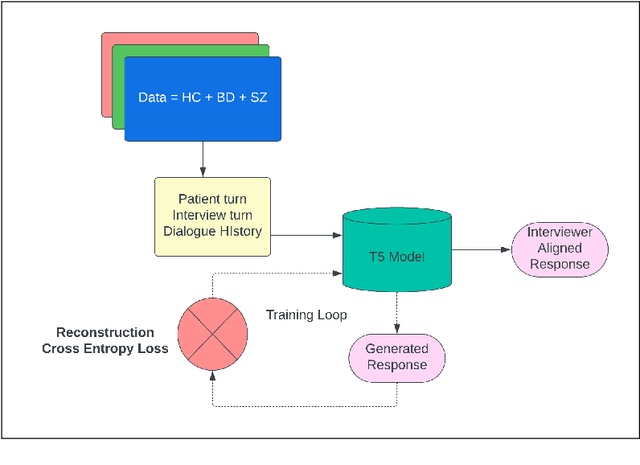
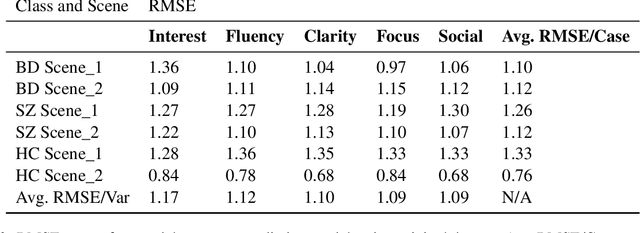
NLP in mental health has been primarily social media focused. Real world practitioners also have high case loads and often domain specific variables, of which modern LLMs lack context. We take a dataset made by recruiting 644 participants, including individuals diagnosed with Bipolar Disorder (BD), Schizophrenia (SZ), and Healthy Controls (HC). Participants undertook tasks derived from a standardized mental health instrument, and the resulting data were transcribed and annotated by experts across five clinical variables. This paper demonstrates the application of contemporary language models in sequence-to-sequence tasks to enhance mental health research. Specifically, we illustrate how these models can facilitate the deployment of mental health instruments, data collection, and data annotation with high accuracy and scalability. We show that small models are capable of annotation for domain-specific clinical variables, data collection for mental-health instruments, and perform better then commercial large models.
CORI: CJKV Benchmark with Romanization Integration -- A step towards Cross-lingual Transfer Beyond Textual Scripts
Apr 19, 2024Naively assuming English as a source language may hinder cross-lingual transfer for many languages by failing to consider the importance of language contact. Some languages are more well-connected than others, and target languages can benefit from transferring from closely related languages; for many languages, the set of closely related languages does not include English. In this work, we study the impact of source language for cross-lingual transfer, demonstrating the importance of selecting source languages that have high contact with the target language. We also construct a novel benchmark dataset for close contact Chinese-Japanese-Korean-Vietnamese (CJKV) languages to further encourage in-depth studies of language contact. To comprehensively capture contact between these languages, we propose to integrate Romanized transcription beyond textual scripts via Contrastive Learning objectives, leading to enhanced cross-lingual representations and effective zero-shot cross-lingual transfer.
Dialogue with Robots: Proposals for Broadening Participation and Research in the SLIVAR Community
Apr 01, 2024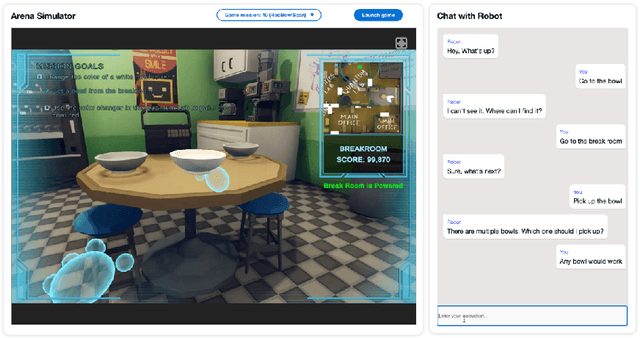
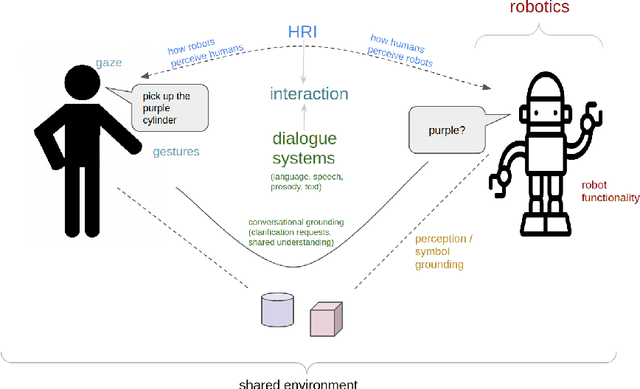
The ability to interact with machines using natural human language is becoming not just commonplace, but expected. The next step is not just text interfaces, but speech interfaces and not just with computers, but with all machines including robots. In this paper, we chronicle the recent history of this growing field of spoken dialogue with robots and offer the community three proposals, the first focused on education, the second on benchmarks, and the third on the modeling of language when it comes to spoken interaction with robots. The three proposals should act as white papers for any researcher to take and build upon.
Investigating Reproducibility at Interspeech Conferences: A Longitudinal and Comparative Perspective
Jun 07, 2023

Reproducibility is a key aspect for scientific advancement across disciplines, and reducing barriers for open science is a focus area for the theme of Interspeech 2023. Availability of source code is one of the indicators that facilitates reproducibility. However, less is known about the rates of reproducibility at Interspeech conferences in comparison to other conferences in the field. In order to fill this gap, we have surveyed 27,717 papers at seven conferences across speech and language processing disciplines. We find that despite having a close number of accepted papers to the other conferences, Interspeech has up to 40% less source code availability. In addition to reporting the difficulties we have encountered during our research, we also provide recommendations and possible directions to increase reproducibility for further studies.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023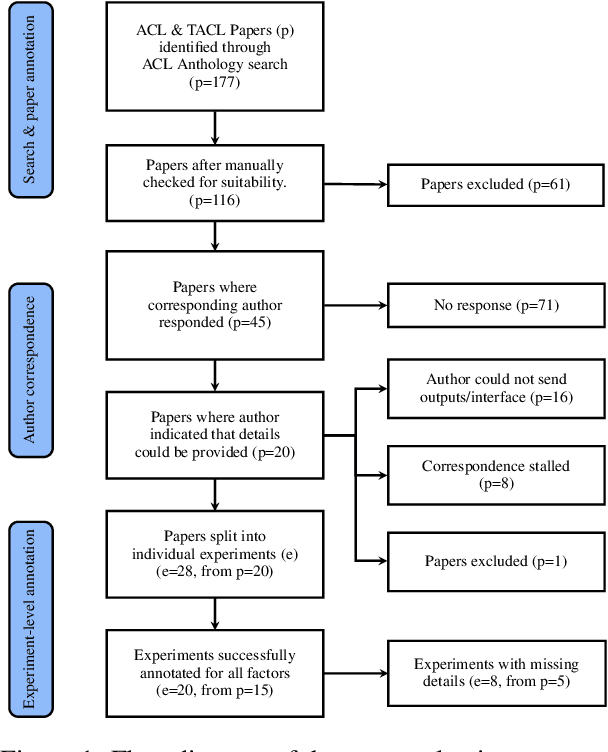
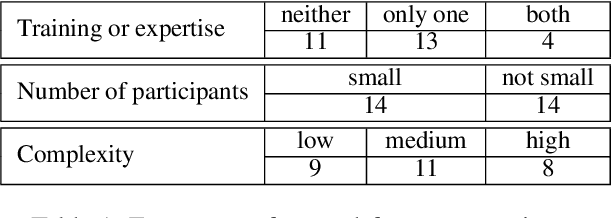


We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
Tracking Turbulence Through Financial News During COVID-19
Sep 09, 2021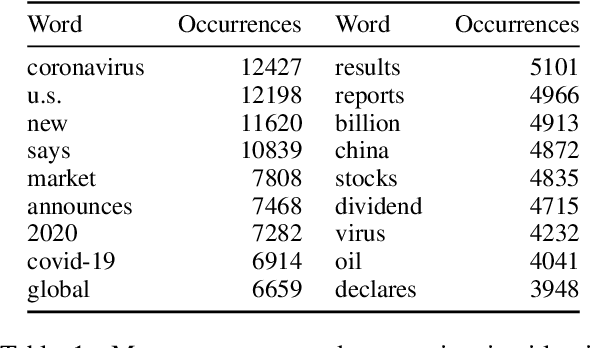
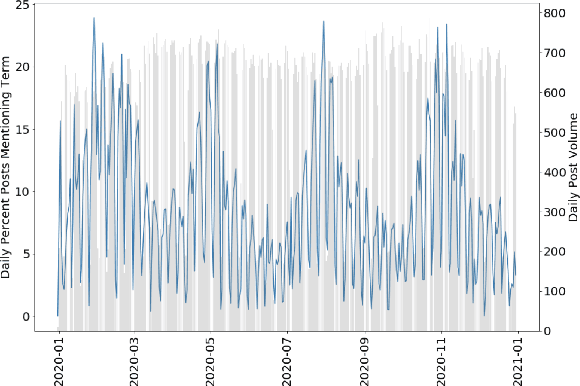

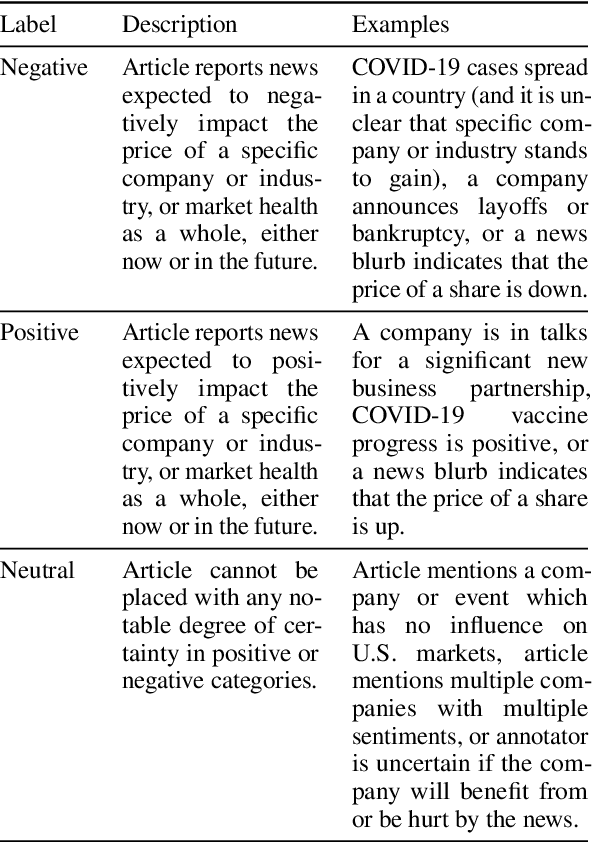
Grave human toll notwithstanding, the COVID-19 pandemic created uniquely unstable conditions in financial markets. In this work we uncover and discuss relationships involving sentiment in financial publications during the 2020 pandemic-motivated U.S. financial crash. First, we introduce a set of expert annotations of financial sentiment for articles from major American financial news publishers. After an exploratory data analysis, we then describe a CNN-based architecture to address the task of predicting financial sentiment in this anomalous, tumultuous setting. Our best performing model achieves a maximum weighted F1 score of 0.746, establishing a strong performance benchmark. Using predictions from our top performing model, we close by conducting a statistical correlation study with real stock market data, finding interesting and strong relationships between financial news and the S\&P 500 index, trading volume, market volatility, and different single-factor ETFs.
Latent Neural Differential Equations for Video Generation
Nov 07, 2020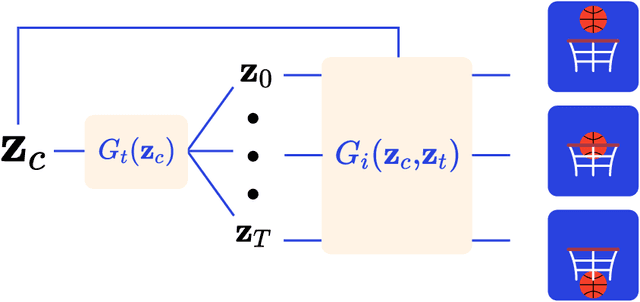
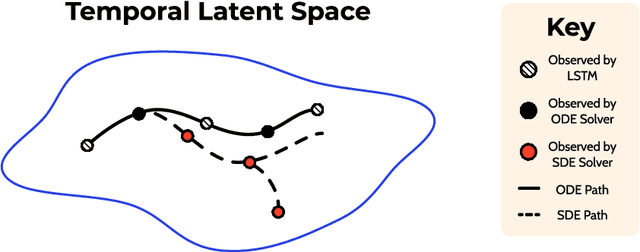
Generative Adversarial Networks have recently shown promise for video generation, building off of the success of image generation while also addressing a new challenge: time. Although time was analyzed in some early work, the literature has not adequately grown with temporal modeling developments. We propose studying the effects of Neural Differential Equations to model the temporal dynamics of video generation. The paradigm of Neural Differential Equations presents many theoretical strengths including the first continuous representation of time within video generation. In order to address the effects of Neural Differential Equations, we will investigate how changes in temporal models affect generated video quality.
Enriching Neural Models with Targeted Features for Dementia Detection
Jun 13, 2019
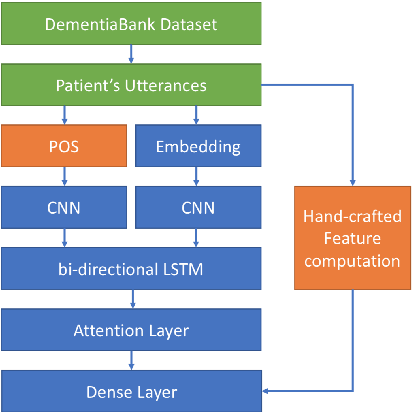


Alzheimer's disease (AD) is an irreversible brain disease that can dramatically reduce quality of life, most commonly manifesting in older adults and eventually leading to the need for full-time care. Early detection is fundamental to slowing its progression; however, diagnosis can be expensive, time-consuming, and invasive. In this work we develop a neural model based on a CNN-LSTM architecture that learns to detect AD and related dementias using targeted and implicitly-learned features from conversational transcripts. Our approach establishes the new state of the art on the DementiaBank dataset, achieving an F1 score of 0.929 when classifying participants into AD and control groups.
AI Meets Austen: Towards Human-Robot Discussions of Literary Metaphor
Apr 07, 2019
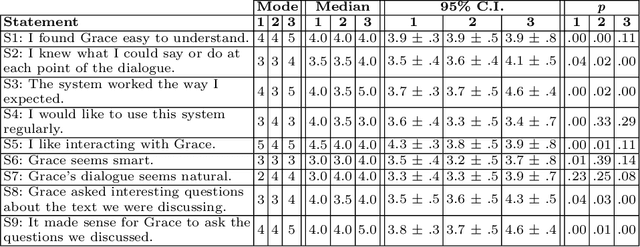

Artificial intelligence is revolutionizing formal education, fueled by innovations in learning assessment, content generation, and instructional delivery. Informal, lifelong learning settings have been the subject of less attention. We provide a proof-of-concept for an embodied book discussion companion, designed to stimulate conversations with readers about particularly creative metaphors in fiction literature. We collect ratings from 26 participants, each of whom discuss Jane Austen's "Pride and Prejudice" with the robot across one or more sessions, and find that participants rate their interactions highly. This suggests that companion robots could be an interesting entryway for the promotion of lifelong learning and cognitive exercise in future applications.
The Steep Road to Happily Ever After: An Analysis of Current Visual Storytelling Models
Apr 06, 2019
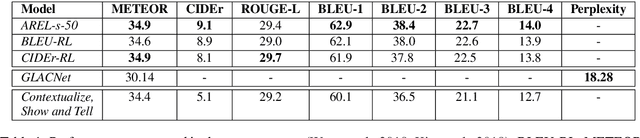

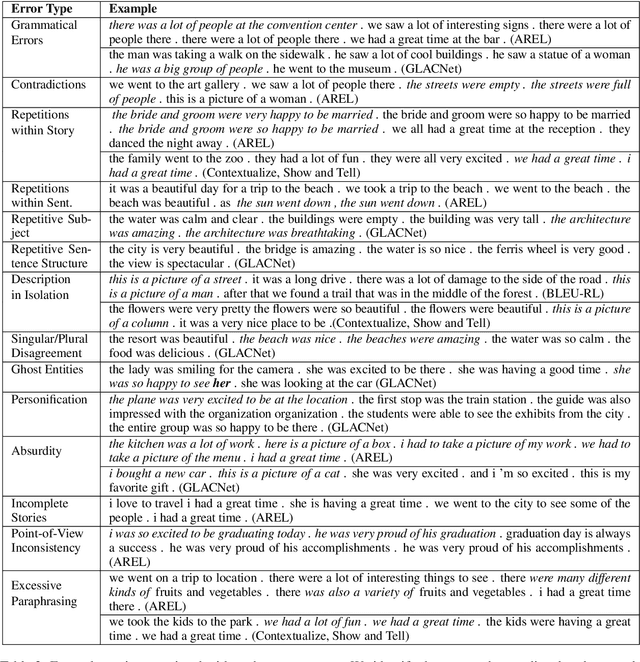
Visual storytelling is an intriguing and complex task that only recently entered the research arena. In this work, we survey relevant work to date, and conduct a thorough error analysis of three very recent approaches to visual storytelling. We categorize and provide examples of common types of errors, and identify key shortcomings in current work. Finally, we make recommendations for addressing these limitations in the future.