 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Humanization for Therapeutic Antibodies
Dec 09, 2024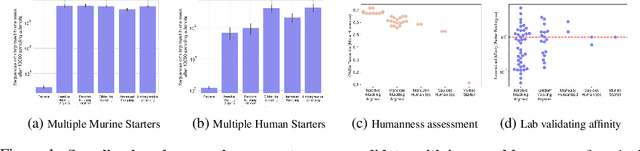
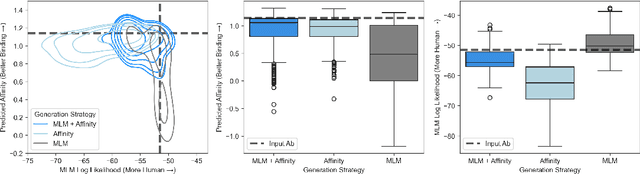
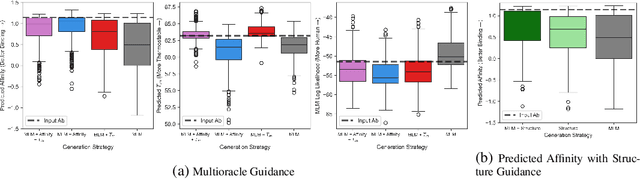
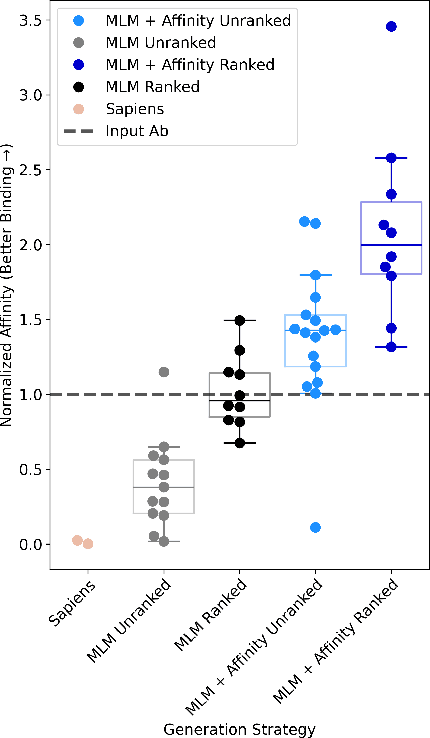
Antibody therapies have been employed to address some of today's most challenging diseases, but must meet many criteria during drug development before reaching a patient. Humanization is a sequence optimization strategy that addresses one critical risk called immunogenicity - a patient's immune response to the drug - by making an antibody more "human-like" in the absence of a predictive lab-based test for immunogenicity. However, existing humanization strategies generally yield very few humanized candidates, which may have degraded biophysical properties or decreased drug efficacy. Here, we re-frame humanization as a conditional generative modeling task, where humanizing mutations are sampled from a language model trained on human antibody data. We describe a sampling process that incorporates models of therapeutic attributes, such as antigen binding affinity, to obtain candidate sequences that have both reduced immunogenicity risk and maintained or improved therapeutic properties, allowing this algorithm to be readily embedded into an iterative antibody optimization campaign. We demonstrate in silico and in lab validation that in real therapeutic programs our generative humanization method produces diverse sets of antibodies that are both (1) highly-human and (2) have favorable therapeutic properties, such as improved binding to target antigens.
Reproducible scaling laws for contrastive language-image learning
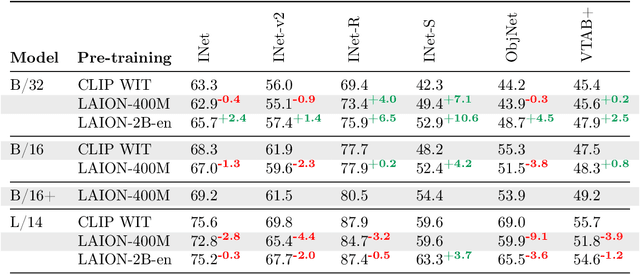
Dec 14, 2022Scaling up neural networks has led to remarkable performance across a wide range of tasks. Moreover, performance often follows reliable scaling laws as a function of training set size, model size, and compute, which offers valuable guidance as large-scale experiments are becoming increasingly expensive. However, previous work on scaling laws has primarily used private data \& models or focused on uni-modal language or vision learning. To address these limitations, we investigate scaling laws for contrastive language-image pre-training (CLIP) with the public LAION dataset and the open-source OpenCLIP repository. Our large-scale experiments involve models trained on up to two billion image-text pairs and identify power law scaling for multiple downstream tasks including zero-shot classification, retrieval, linear probing, and end-to-end fine-tuning. We find that the training distribution plays a key role in scaling laws as the OpenAI and OpenCLIP models exhibit different scaling behavior despite identical model architectures and similar training recipes. We open-source our evaluation workflow and all models, including the largest public CLIP models, to ensure reproducibility and make scaling laws research more accessible. Source code and instructions to reproduce this study will be available at https://github.com/LAION-AI/scaling-laws-openclip
LAION-5B: An open large-scale dataset for training next generation image-text models
Oct 16, 2022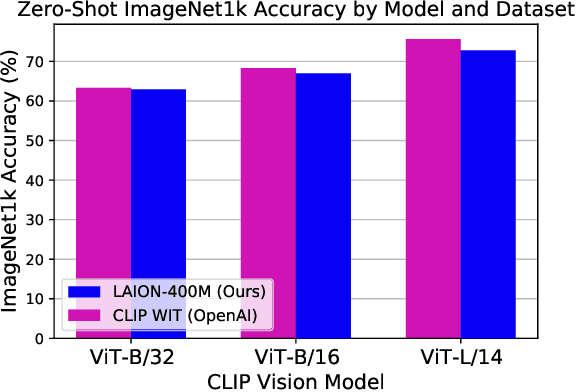
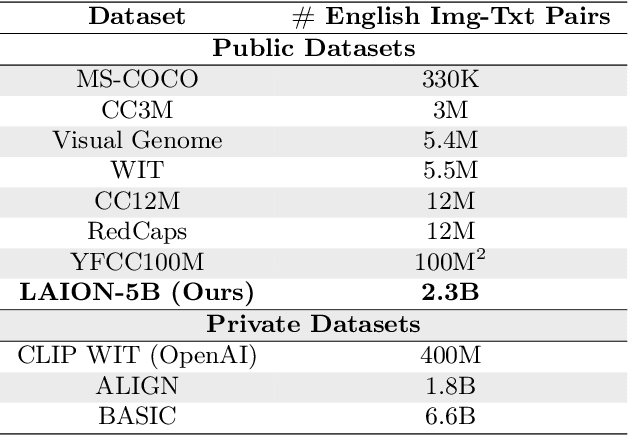
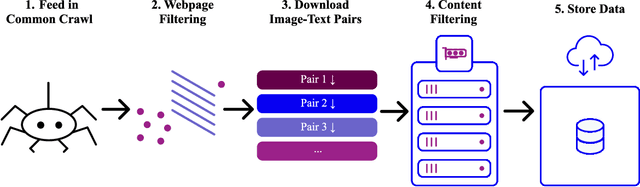
Groundbreaking language-vision architectures like CLIP and DALL-E proved the utility of training on large amounts of noisy image-text data, without relying on expensive accurate labels used in standard vision unimodal supervised learning. The resulting models showed capabilities of strong text-guided image generation and transfer to downstream tasks, while performing remarkably at zero-shot classification with noteworthy out-of-distribution robustness. Since then, large-scale language-vision models like ALIGN, BASIC, GLIDE, Flamingo and Imagen made further improvements. Studying the training and capabilities of such models requires datasets containing billions of image-text pairs. Until now, no datasets of this size have been made openly available for the broader research community. To address this problem and democratize research on large-scale multi-modal models, we present LAION-5B - a dataset consisting of 5.85 billion CLIP-filtered image-text pairs, of which 2.32B contain English language. We show successful replication and fine-tuning of foundational models like CLIP, GLIDE and Stable Diffusion using the dataset, and discuss further experiments enabled with an openly available dataset of this scale. Additionally we provide several nearest neighbor indices, an improved web-interface for dataset exploration and subset generation, and detection scores for watermark, NSFW, and toxic content detection. Announcement page https://laion.ai/laion-5b-a-new-era-of-open-large-scale-multi-modal-datasets/
Latent Neural Differential Equations for Video Generation
Nov 07, 2020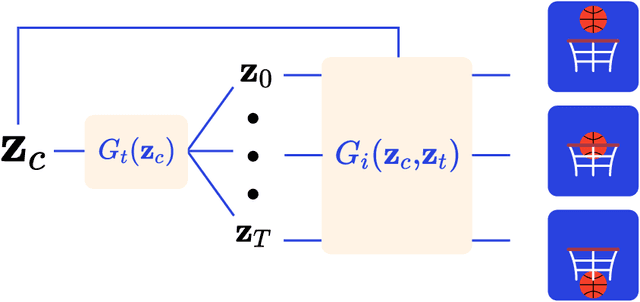
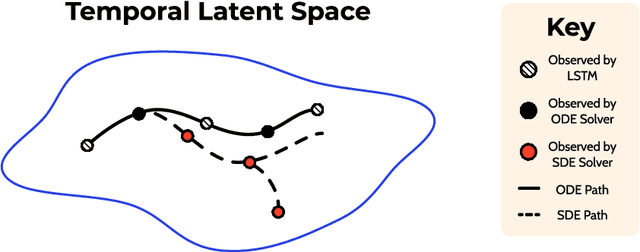
Generative Adversarial Networks have recently shown promise for video generation, building off of the success of image generation while also addressing a new challenge: time. Although time was analyzed in some early work, the literature has not adequately grown with temporal modeling developments. We propose studying the effects of Neural Differential Equations to model the temporal dynamics of video generation. The paradigm of Neural Differential Equations presents many theoretical strengths including the first continuous representation of time within video generation. In order to address the effects of Neural Differential Equations, we will investigate how changes in temporal models affect generated video quality.