 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Human Rights Violations on Social Media during Russia-Ukraine War
Jun 06, 2023The present-day Russia-Ukraine military conflict has exposed the pivotal role of social media in enabling the transparent and unbridled sharing of information directly from the frontlines. In conflict zones where freedom of expression is constrained and information warfare is pervasive, social media has emerged as an indispensable lifeline. Anonymous social media platforms, as publicly available sources for disseminating war-related information, have the potential to serve as effective instruments for monitoring and documenting Human Rights Violations (HRV). Our research focuses on the analysis of data from Telegram, the leading social media platform for reading independent news in post-Soviet regions. We gathered a dataset of posts sampled from 95 public Telegram channels that cover politics and war news, which we have utilized to identify potential occurrences of HRV. Employing a mBERT-based text classifier, we have conducted an analysis to detect any mentions of HRV in the Telegram data. Our final approach yielded an $F_2$ score of 0.71 for HRV detection, representing an improvement of 0.38 over the multilingual BERT base model. We release two datasets that contains Telegram posts: (1) large corpus with over 2.3 millions posts and (2) annotated at the sentence-level dataset to indicate HRVs. The Telegram posts are in the context of the Russia-Ukraine war. We posit that our findings hold significant implications for NGOs, governments, and researchers by providing a means to detect and document possible human rights violations.
AI Meets Austen: Towards Human-Robot Discussions of Literary Metaphor
Apr 07, 2019
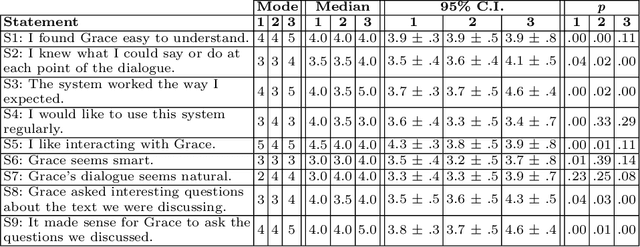

Artificial intelligence is revolutionizing formal education, fueled by innovations in learning assessment, content generation, and instructional delivery. Informal, lifelong learning settings have been the subject of less attention. We provide a proof-of-concept for an embodied book discussion companion, designed to stimulate conversations with readers about particularly creative metaphors in fiction literature. We collect ratings from 26 participants, each of whom discuss Jane Austen's "Pride and Prejudice" with the robot across one or more sessions, and find that participants rate their interactions highly. This suggests that companion robots could be an interesting entryway for the promotion of lifelong learning and cognitive exercise in future applications.
#SarcasmDetection is soooo general! Towards a Domain-Independent Approach for Detecting Sarcasm
Jun 08, 2018

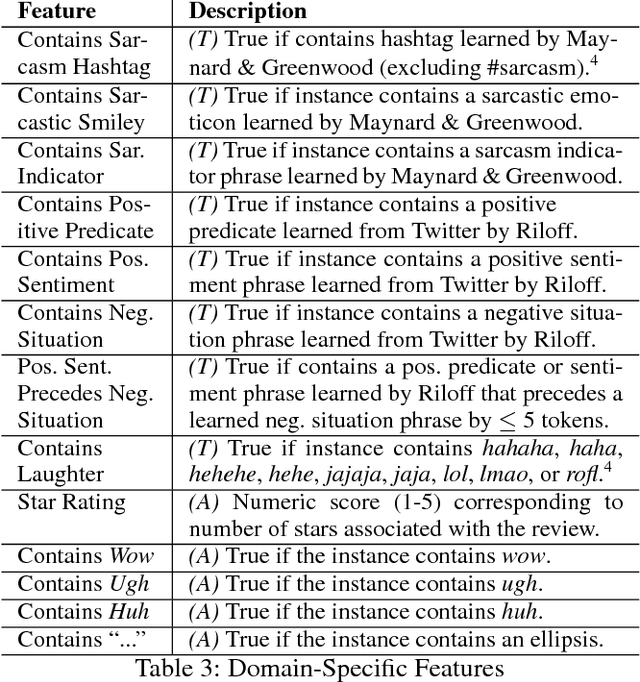
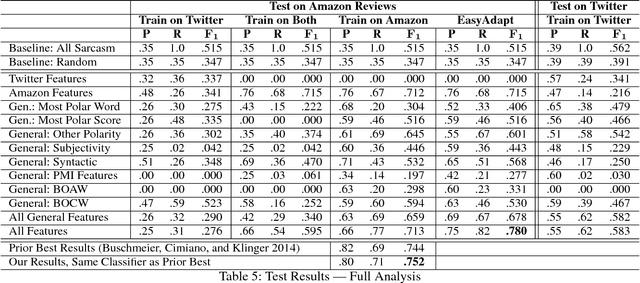
Automatic sarcasm detection methods have traditionally been designed for maximum performance on a specific domain. This poses challenges for those wishing to transfer those approaches to other existing or novel domains, which may be typified by very different language characteristics. We develop a general set of features and evaluate it under different training scenarios utilizing in-domain and/or out-of-domain training data. The best-performing scenario, training on both while employing a domain adaptation step, achieves an F1 of 0.780, which is well above baseline F1-measures of 0.515 and 0.345. We also show that the approach outperforms the best results from prior work on the same target domain.