Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge#SarcasmDetection is soooo general! Towards a Domain-Independent Approach for Detecting Sarcasm
Paper and Code
Jun 08, 2018

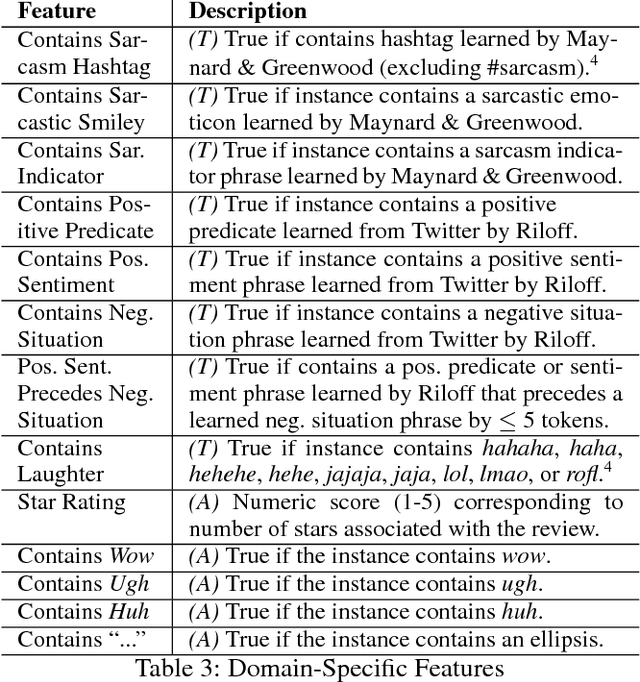
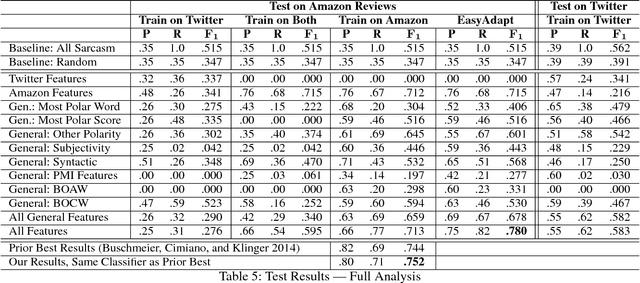
Automatic sarcasm detection methods have traditionally been designed for maximum performance on a specific domain. This poses challenges for those wishing to transfer those approaches to other existing or novel domains, which may be typified by very different language characteristics. We develop a general set of features and evaluate it under different training scenarios utilizing in-domain and/or out-of-domain training data. The best-performing scenario, training on both while employing a domain adaptation step, achieves an F1 of 0.780, which is well above baseline F1-measures of 0.515 and 0.345. We also show that the approach outperforms the best results from prior work on the same target domain.
* Proceedings of the 30th International Florida Artificial Intelligence
Research Society Conference
View paper on