 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniEdit: A Unified Knowledge Editing Benchmark for Large Language Models
May 18, 2025Model editing aims to enhance the accuracy and reliability of large language models (LLMs) by efficiently adjusting their internal parameters. Currently, most LLM editing datasets are confined to narrow knowledge domains and cover a limited range of editing evaluation. They often overlook the broad scope of editing demands and the diversity of ripple effects resulting from edits. In this context, we introduce UniEdit, a unified benchmark for LLM editing grounded in open-domain knowledge. First, we construct editing samples by selecting entities from 25 common domains across five major categories, utilizing the extensive triple knowledge available in open-domain knowledge graphs to ensure comprehensive coverage of the knowledge domains. To address the issues of generality and locality in editing, we design an Neighborhood Multi-hop Chain Sampling (NMCS) algorithm to sample subgraphs based on a given knowledge piece to entail comprehensive ripple effects to evaluate. Finally, we employ proprietary LLMs to convert the sampled knowledge subgraphs into natural language text, guaranteeing grammatical accuracy and syntactical diversity. Extensive statistical analysis confirms the scale, comprehensiveness, and diversity of our UniEdit benchmark. We conduct comprehensive experiments across multiple LLMs and editors, analyzing their performance to highlight strengths and weaknesses in editing across open knowledge domains and various evaluation criteria, thereby offering valuable insights for future research endeavors.
Lifelong Knowledge Editing for Vision Language Models with Low-Rank Mixture-of-Experts
Nov 23, 2024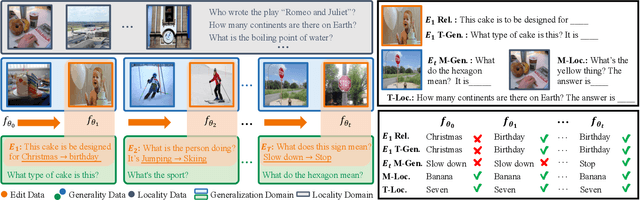
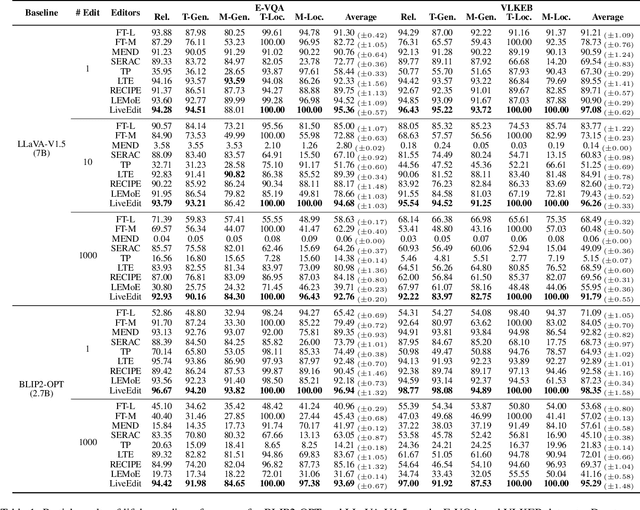
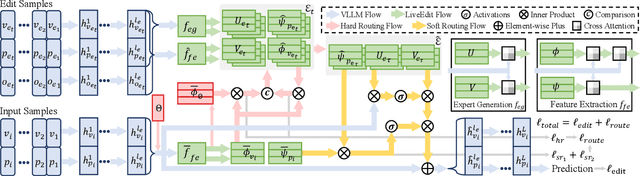
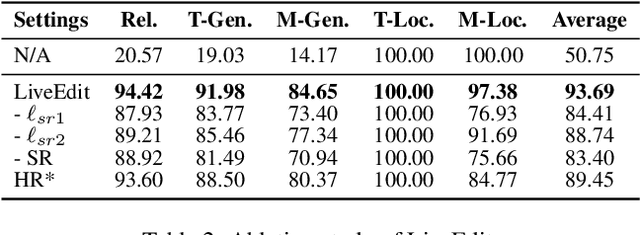
Model editing aims to correct inaccurate knowledge, update outdated information, and incorporate new data into Large Language Models (LLMs) without the need for retraining. This task poses challenges in lifelong scenarios where edits must be continuously applied for real-world applications. While some editors demonstrate strong robustness for lifelong editing in pure LLMs, Vision LLMs (VLLMs), which incorporate an additional vision modality, are not directly adaptable to existing LLM editors. In this paper, we propose LiveEdit, a LIfelong Vision language modEl Edit to bridge the gap between lifelong LLM editing and VLLMs. We begin by training an editing expert generator to independently produce low-rank experts for each editing instance, with the goal of correcting the relevant responses of the VLLM. A hard filtering mechanism is developed to utilize visual semantic knowledge, thereby coarsely eliminating visually irrelevant experts for input queries during the inference stage of the post-edited model. Finally, to integrate visually relevant experts, we introduce a soft routing mechanism based on textual semantic relevance to achieve multi-expert fusion. For evaluation, we establish a benchmark for lifelong VLLM editing. Extensive experiments demonstrate that LiveEdit offers significant advantages in lifelong VLLM editing scenarios. Further experiments validate the rationality and effectiveness of each module design in LiveEdit.
Attribution Analysis Meets Model Editing: Advancing Knowledge Correction in Vision Language Models with VisEdit
Aug 19, 2024



Model editing aims to correct outdated or erroneous knowledge in large models without costly retraining. Recent research discovered that the mid-layer representation of the subject's final token in a prompt has a strong influence on factual predictions, and developed Large Language Model (LLM) editing techniques based on this observation. However, for Vision-LLMs (VLLMs), how visual representations impact the predictions from a decoder-only language model remains largely unexplored. To the best of our knowledge, model editing for VLLMs has not been extensively studied in the literature. In this work, we employ the contribution allocation and noise perturbation methods to measure the contributions of visual representations for token predictions. Our attribution analysis shows that visual representations in mid-to-later layers that are highly relevant to the prompt contribute significantly to predictions. Based on these insights, we propose VisEdit, a novel model editor for VLLMs that effectively corrects knowledge by editing intermediate visual representations in regions important to the edit prompt. We evaluated VisEdit using multiple VLLM backbones and public VLLM editing benchmark datasets. The results show the superiority of VisEdit over the strong baselines adapted from existing state-of-the-art editors for LLMs.