 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Neural Data Server: A Data Recommender for Transfer Learning
Paper and Code
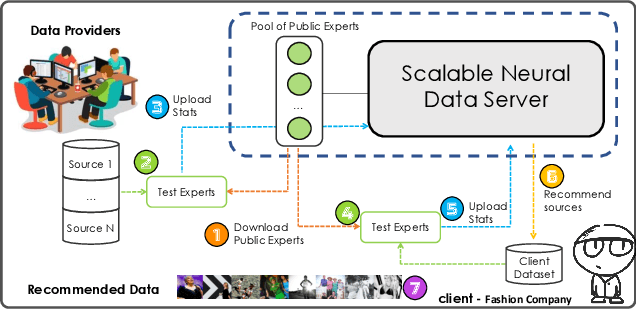
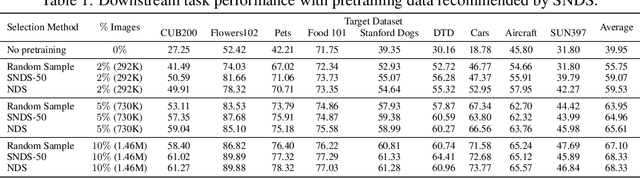
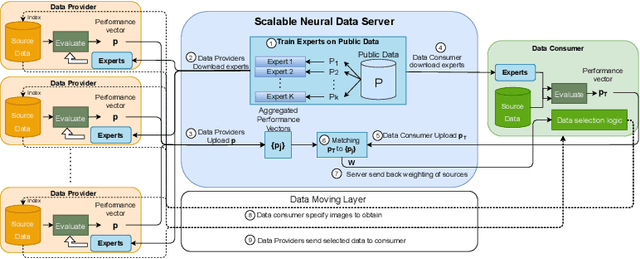
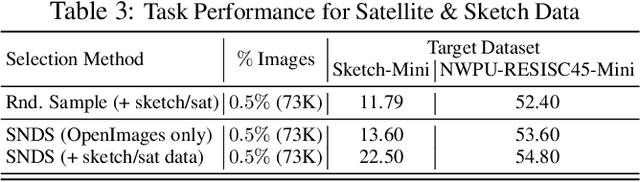
Absence of large-scale labeled data in the practitioner's target domain can be a bottleneck to applying machine learning algorithms in practice. Transfer learning is a popular strategy for leveraging additional data to improve the downstream performance, but finding the most relevant data to transfer from can be challenging. Neural Data Server (NDS), a search engine that recommends relevant data for a given downstream task, has been previously proposed to address this problem. NDS uses a mixture of experts trained on data sources to estimate similarity between each source and the downstream task. Thus, the computational cost to each user grows with the number of sources. To address these issues, we propose Scalable Neural Data Server (SNDS), a large-scale search engine that can theoretically index thousands of datasets to serve relevant ML data to end users. SNDS trains the mixture of experts on intermediary datasets during initialization, and represents both data sources and downstream tasks by their proximity to the intermediary datasets. As such, computational cost incurred by SNDS users remains fixed as new datasets are added to the server. We validate SNDS on a plethora of real world tasks and find that data recommended by SNDS improves downstream task performance over baselines. We also demonstrate the scalability of SNDS by showing its ability to select relevant data for transfer outside of the natural image setting.