 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTMPDiff: Temporal Mixed-Precision for Diffusion Models
Mar 14, 2026Diffusion models are the go-to method for Text-to-Image generation, but their iterative denoising processes has high inference latency. Quantization reduces compute time by using lower bitwidths, but applies a fixed precision across all denoising timesteps, leaving an entire optimization axis unexplored. We propose TMPDiff, a temporal mixed-precision framework for diffusion models that assigns different numeric precision to different denoising timesteps. We hypothesize that quantization errors accumulate additively across timesteps, which we then validate experimentally. Based on our observations, we develop an adaptive bisectioning-based algorithm, which assigns per-step precisions with linear evaluation complexity, reducing an otherwise exponential search problem. Across four state-of-the-art diffusion models and three datasets, TMPDiff consistently outperforms uniform-precision baselines at matched speedup, achieving 10 to 20% improvement in perceptual quality. On FLUX.1-dev, TMPDiff achieves 90% SSIM relative to the full-precision model at a speedup of 2.5x over 16-bit inference.
MPQ-Diff: Mixed Precision Quantization for Diffusion Models
Nov 28, 2024

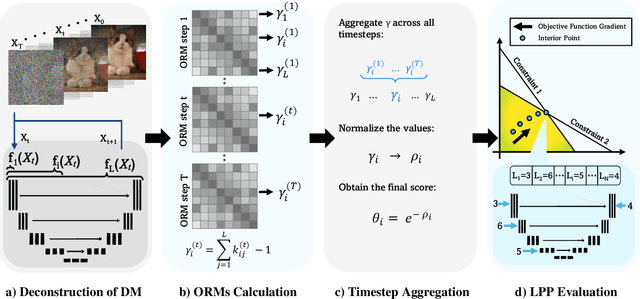

Diffusion models (DMs) generate remarkable high quality images via the stochastic denoising process, which unfortunately incurs high sampling time. Post-quantizing the trained diffusion models in fixed bit-widths, e.g., 4 bits on weights and 8 bits on activation, is shown effective in accelerating sampling time while maintaining the image quality. Motivated by the observation that the cross-layer dependency of DMs vary across layers and sampling steps, we propose a mixed precision quantization scheme, MPQ-Diff, which allocates different bit-width to the weights and activation of the layers. We advocate to use the cross-layer correlation of a given layer, termed network orthogonality metric, as a proxy to measure the relative importance of a layer per sampling step. We further adopt a uniform sampling scheme to avoid the excessive profiling overhead of estimating orthogonality across all time steps. We evaluate the proposed mixed-precision on LSUN and ImageNet, showing a significant improvement in FID from 65.73 to 15.39, and 52.66 to 14.93, compared to their fixed precision quantization, respectively.
Memory Efficient Mixed-Precision Optimizers
Sep 21, 2023Traditional optimization methods rely on the use of single-precision floating point arithmetic, which can be costly in terms of memory size and computing power. However, mixed precision optimization techniques leverage the use of both single and half-precision floating point arithmetic to reduce memory requirements while maintaining model accuracy. We provide here an algorithm to further reduce memory usage during the training of a model by getting rid of the floating point copy of the parameters, virtually keeping only half-precision numbers. We also explore the benefits of getting rid of the gradient's value by executing the optimizer step during the back-propagation. In practice, we achieve up to 25% lower peak memory use and 15% faster training while maintaining the same level of accuracy.