 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPQ-Diff: Mixed Precision Quantization for Diffusion Models
Nov 28, 2024

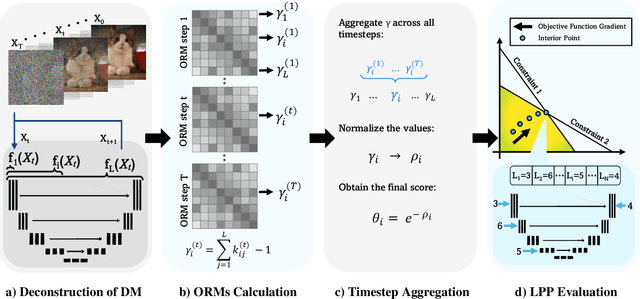

Diffusion models (DMs) generate remarkable high quality images via the stochastic denoising process, which unfortunately incurs high sampling time. Post-quantizing the trained diffusion models in fixed bit-widths, e.g., 4 bits on weights and 8 bits on activation, is shown effective in accelerating sampling time while maintaining the image quality. Motivated by the observation that the cross-layer dependency of DMs vary across layers and sampling steps, we propose a mixed precision quantization scheme, MPQ-Diff, which allocates different bit-width to the weights and activation of the layers. We advocate to use the cross-layer correlation of a given layer, termed network orthogonality metric, as a proxy to measure the relative importance of a layer per sampling step. We further adopt a uniform sampling scheme to avoid the excessive profiling overhead of estimating orthogonality across all time steps. We evaluate the proposed mixed-precision on LSUN and ImageNet, showing a significant improvement in FID from 65.73 to 15.39, and 52.66 to 14.93, compared to their fixed precision quantization, respectively.