 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangSAMP: Language-Script Aware Multilingual Pretraining
Sep 26, 2024Recent multilingual pretrained language models (mPLMs) often avoid using language embeddings -- learnable vectors assigned to different languages. These embeddings are discarded for two main reasons: (1) mPLMs are expected to have a single, unified parameter set across all languages, and (2) they need to function seamlessly as universal text encoders without requiring language IDs as input. However, this removal increases the burden on token embeddings to encode all language-specific information, which may hinder the model's ability to produce more language-neutral representations. To address this challenge, we propose Language-Script Aware Multilingual Pretraining (LangSAMP), a method that incorporates both language and script embeddings to enhance representation learning while maintaining a simple architecture. Specifically, we integrate these embeddings into the output of the transformer blocks before passing the final representations to the language modeling head for prediction. We apply LangSAMP to the continual pretraining of XLM-R on a highly multilingual corpus covering more than 500 languages. The resulting model consistently outperforms the baseline. Extensive analysis further shows that language/script embeddings encode language/script-specific information, which improves the selection of source languages for crosslingual transfer. We make our code and models publicly available at \url{https://github.com/cisnlp/LangSAMP}.
How Transliterations Improve Crosslingual Alignment
Sep 25, 2024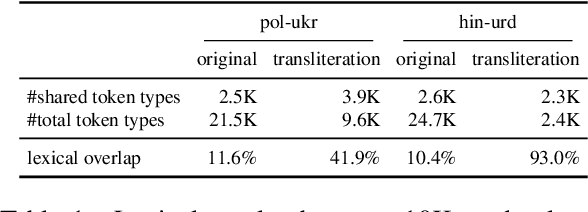

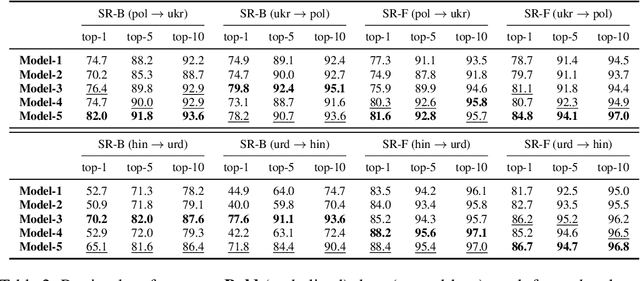

Recent studies have shown that post-aligning multilingual pretrained language models (mPLMs) using alignment objectives on both original and transliterated data can improve crosslingual alignment. This improvement further leads to better crosslingual transfer performance. However, it remains unclear how and why a better crosslingual alignment is achieved, as this technique only involves transliterations, and does not use any parallel data. This paper attempts to explicitly evaluate the crosslingual alignment and identify the key elements in transliteration-based approaches that contribute to better performance. For this, we train multiple models under varying setups for two pairs of related languages: (1) Polish and Ukrainian and (2) Hindi and Urdu. To assess alignment, we define four types of similarities based on sentence representations. Our experiments show that adding transliterations alone improves the overall similarities, even for random sentence pairs. With the help of auxiliary alignment objectives, especially the contrastive objective, the model learns to distinguish matched from random pairs, leading to better alignments. However, we also show that better alignment does not always yield better downstream performance, suggesting that further research is needed to clarify the connection between alignment and performance.
Exploring the Role of Transliteration in In-Context Learning for Low-resource Languages Written in Non-Latin Scripts
Jul 02, 2024



Decoder-only large language models (LLMs) excel in high-resource languages across various tasks through few-shot or even zero-shot in-context learning (ICL). However, their performance often does not transfer well to low-resource languages, especially those written in non-Latin scripts. Inspired by recent work that leverages transliteration in encoder-only models, we investigate whether transliteration is also effective in improving LLMs' performance for low-resource languages written in non-Latin scripts. To this end, we propose three prompt templates, where the target-language text is represented in (1) its original script, (2) Latin script, or (3) both. We apply these methods to several representative LLMs of different sizes on various tasks including text classification and sequential labeling. Our findings show that the effectiveness of transliteration varies by task type and model size. For instance, all models benefit from transliterations for sequential labeling (with increases of up to 25%).
TransMI: A Framework to Create Strong Baselines from Multilingual Pretrained Language Models for Transliterated Data
May 16, 2024Transliterating related languages that use different scripts into a common script shows effectiveness in improving crosslingual transfer in downstream tasks. However, this methodology often makes pretraining a model from scratch unavoidable, as transliteration brings about new subwords not covered in existing multilingual pretrained language models (mPLMs). This is not desired because it takes a lot of computation budget for pretraining. A more promising way is to make full use of available mPLMs. To this end, this paper proposes a simple but effective framework: Transliterate-Merge-Initialize (TransMI), which can create a strong baseline well-suited for data that is transliterated into a common script by exploiting an mPLM and its accompanied tokenizer. TransMI has three stages: (a) transliterate the vocabulary of an mPLM into a common script; (b) merge the new vocabulary with the original vocabulary; and (c) initialize the embeddings of the new subwords. We applied TransMI to three recent strong mPLMs, and our experiments demonstrate that TransMI not only preserves their ability to handle non-transliterated data, but also enables the models to effectively process transliterated data: the results show a consistent improvement of 3% to 34%, varying across different models and tasks. We make our code and models publicly available at \url{https://github.com/cisnlp/TransMI}.
TransliCo: A Contrastive Learning Framework to Address the Script Barrier in Multilingual Pretrained Language Models
Jan 12, 2024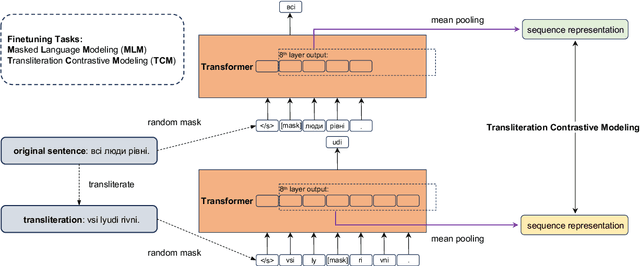
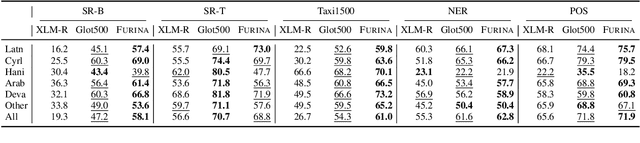
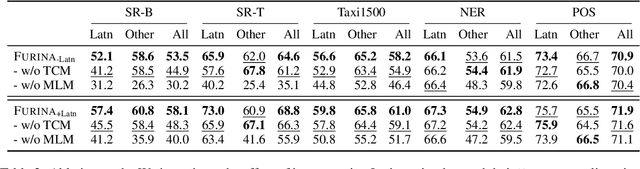
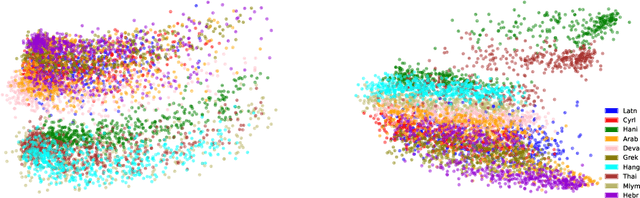
There are 293 scripts representing over 7,000 languages in the written form. Due to various reasons, many closely related languages use different scripts, which poses difficulty for multilingual pretrained language models (mPLMs) in learning crosslingual knowledge through lexical overlap. As a result, mPLMs present a script barrier: representations from different scripts are located in different subspaces, which is a strong indicator of why crosslingual transfer involving languages of different scripts shows sub-optimal performance. To address this problem, we propose a simple framework TransliCo that contains Transliteration Contrastive Modeling (TCM) to fine-tune an mPLM by contrasting sentences in its training data and their transliterations in a unified script (Latn, in our case), which ensures uniformity in the representation space for different scripts. Using Glot500-m, an mPLM pretrained on over 500 languages, as our source model, we find-tune it on a small portion (5\%) of its training data, and refer to the resulting model as Furina. We show that Furina not only better aligns representations from distinct scripts but also outperforms the original Glot500-m on various crosslingual transfer tasks. Additionally, we achieve consistent improvement in a case study on the Indic group where the languages are highly related but use different scripts. We make our code and models publicly available.
MoSECroT: Model Stitching with Static Word Embeddings for Crosslingual Zero-shot Transfer
Jan 09, 2024



Transformer-based pre-trained language models (PLMs) have achieved remarkable performance in various natural language processing (NLP) tasks. However, pre-training such models can take considerable resources that are almost only available to high-resource languages. On the contrary, static word embeddings are easier to train in terms of computing resources and the amount of data required. In this paper, we introduce MoSECroT Model Stitching with Static Word Embeddings for Crosslingual Zero-shot Transfer), a novel and challenging task that is especially relevant to low-resource languages for which static word embeddings are available. To tackle the task, we present the first framework that leverages relative representations to construct a common space for the embeddings of a source language PLM and the static word embeddings of a target language. In this way, we can train the PLM on source-language training data and perform zero-shot transfer to the target language by simply swapping the embedding layer. However, through extensive experiments on two classification datasets, we show that although our proposed framework is competitive with weak baselines when addressing MoSECroT, it fails to achieve competitive results compared with some strong baselines. In this paper, we attempt to explain this negative result and provide several thoughts on possible improvement.
Glot500: Scaling Multilingual Corpora and Language Models to 500 Languages
May 26, 2023



The NLP community has mainly focused on scaling Large Language Models (LLMs) vertically, i.e., making them better for about 100 languages. We instead scale LLMs horizontally: we create, through continued pretraining, Glot500-m, an LLM that covers 511 predominantly low-resource languages. An important part of this effort is to collect and clean Glot500-c, a corpus that covers these 511 languages and allows us to train Glot500-m. We evaluate Glot500-m on five diverse tasks across these languages. We observe large improvements for both high-resource and low-resource languages compared to an XLM-R baseline. Our analysis shows that no single factor explains the quality of multilingual LLM representations. Rather, a combination of factors determines quality including corpus size, script, "help" from related languages and the total capacity of the model. Our work addresses an important goal of NLP research: we should not limit NLP to a small fraction of the world's languages and instead strive to support as many languages as possible to bring the benefits of NLP technology to all languages and cultures. Code, data and models are available at https://github.com/cisnlp/Glot500.
Taxi1500: A Multilingual Dataset for Text Classification in 1500 Languages
May 15, 2023



While natural language processing tools have been developed extensively for some of the world's languages, a significant portion of the world's over 7000 languages are still neglected. One reason for this is that evaluation datasets do not yet cover a wide range of languages, including low-resource and endangered ones. We aim to address this issue by creating a text classification dataset encompassing a large number of languages, many of which currently have little to no annotated data available. We leverage parallel translations of the Bible to construct such a dataset by first developing applicable topics and employing a crowdsourcing tool to collect annotated data. By annotating the English side of the data and projecting the labels onto other languages through aligned verses, we generate text classification datasets for more than 1500 languages. We extensively benchmark several existing multilingual language models using our dataset. To facilitate the advancement of research in this area, we will release our dataset and code.