 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Word Embeddings for Low-Resource Languages using Anchors and a Chain of Related Languages
Nov 21, 2023



Very low-resource languages, having only a few million tokens worth of data, are not well-supported by multilingual NLP approaches due to poor quality cross-lingual word representations. Recent work showed that good cross-lingual performance can be achieved if a source language is related to the low-resource target language. However, not all language pairs are related. In this paper, we propose to build multilingual word embeddings (MWEs) via a novel language chain-based approach, that incorporates intermediate related languages to bridge the gap between the distant source and target. We build MWEs one language at a time by starting from the resource rich source and sequentially adding each language in the chain till we reach the target. We extend a semi-joint bilingual approach to multiple languages in order to eliminate the main weakness of previous works, i.e., independently trained monolingual embeddings, by anchoring the target language around the multilingual space. We evaluate our method on bilingual lexicon induction for 4 language families, involving 4 very low-resource (<5M tokens) and 4 moderately low-resource (<50M) target languages, showing improved performance in both categories. Additionally, our analysis reveals the importance of good quality embeddings for intermediate languages as well as the importance of leveraging anchor points from all languages in the multilingual space.
Glot500: Scaling Multilingual Corpora and Language Models to 500 Languages
May 26, 2023



The NLP community has mainly focused on scaling Large Language Models (LLMs) vertically, i.e., making them better for about 100 languages. We instead scale LLMs horizontally: we create, through continued pretraining, Glot500-m, an LLM that covers 511 predominantly low-resource languages. An important part of this effort is to collect and clean Glot500-c, a corpus that covers these 511 languages and allows us to train Glot500-m. We evaluate Glot500-m on five diverse tasks across these languages. We observe large improvements for both high-resource and low-resource languages compared to an XLM-R baseline. Our analysis shows that no single factor explains the quality of multilingual LLM representations. Rather, a combination of factors determines quality including corpus size, script, "help" from related languages and the total capacity of the model. Our work addresses an important goal of NLP research: we should not limit NLP to a small fraction of the world's languages and instead strive to support as many languages as possible to bring the benefits of NLP technology to all languages and cultures. Code, data and models are available at https://github.com/cisnlp/Glot500.
Graph-Based Multilingual Label Propagation for Low-Resource Part-of-Speech Tagging
Oct 18, 2022



Part-of-Speech (POS) tagging is an important component of the NLP pipeline, but many low-resource languages lack labeled data for training. An established method for training a POS tagger in such a scenario is to create a labeled training set by transferring from high-resource languages. In this paper, we propose a novel method for transferring labels from multiple high-resource source to low-resource target languages. We formalize POS tag projection as graph-based label propagation. Given translations of a sentence in multiple languages, we create a graph with words as nodes and alignment links as edges by aligning words for all language pairs. We then propagate node labels from source to target using a Graph Neural Network augmented with transformer layers. We show that our propagation creates training sets that allow us to train POS taggers for a diverse set of languages. When combined with enhanced contextualized embeddings, our method achieves a new state-of-the-art for unsupervised POS tagging of low-resource languages.
SilverAlign: MT-Based Silver Data Algorithm For Evaluating Word Alignment
Oct 12, 2022


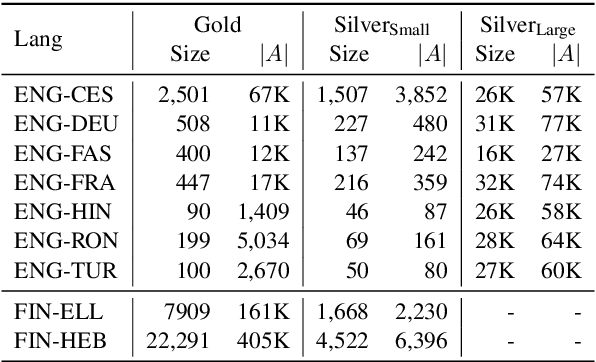
Word alignments are essential for a variety of NLP tasks. Therefore, choosing the best approaches for their creation is crucial. However, the scarce availability of gold evaluation data makes the choice difficult. We propose SilverAlign, a new method to automatically create silver data for the evaluation of word aligners by exploiting machine translation and minimal pairs. We show that performance on our silver data correlates well with gold benchmarks for 9 language pairs, making our approach a valid resource for evaluation of different domains and languages when gold data are not available. This addresses the important scenario of missing gold data alignments for low-resource languages.
Don't Forget Cheap Training Signals Before Building Unsupervised Bilingual Word Embeddings
May 31, 2022
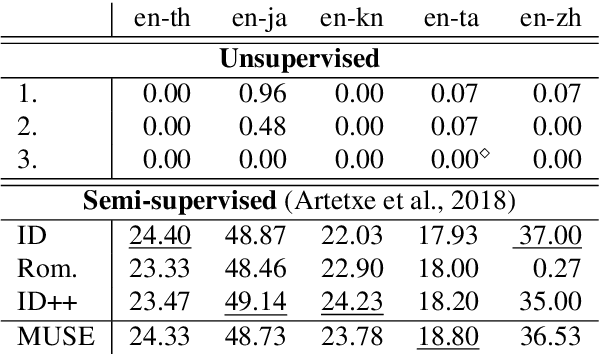

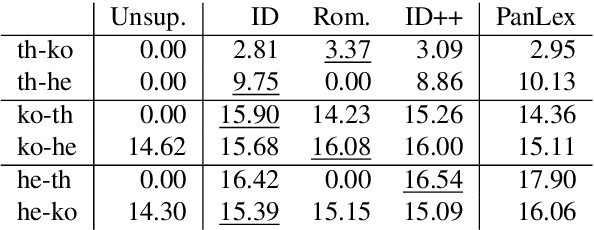
Bilingual Word Embeddings (BWEs) are one of the cornerstones of cross-lingual transfer of NLP models. They can be built using only monolingual corpora without supervision leading to numerous works focusing on unsupervised BWEs. However, most of the current approaches to build unsupervised BWEs do not compare their results with methods based on easy-to-access cross-lingual signals. In this paper, we argue that such signals should always be considered when developing unsupervised BWE methods. The two approaches we find most effective are: 1) using identical words as seed lexicons (which unsupervised approaches incorrectly assume are not available for orthographically distinct language pairs) and 2) combining such lexicons with pairs extracted by matching romanized versions of words with an edit distance threshold. We experiment on thirteen non-Latin languages (and English) and show that such cheap signals work well and that they outperform using more complex unsupervised methods on distant language pairs such as Chinese, Japanese, Kannada, Tamil, and Thai. In addition, they are even competitive with the use of high-quality lexicons in supervised approaches. Our results show that these training signals should not be neglected when building BWEs, even for distant languages.
Towards a Broad Coverage Named Entity Resource: A Data-Efficient Approach for Many Diverse Languages
Jan 28, 2022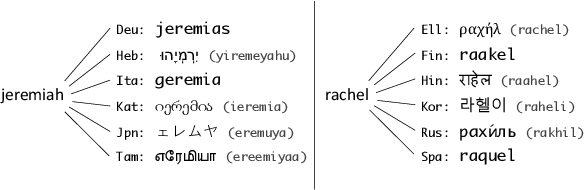
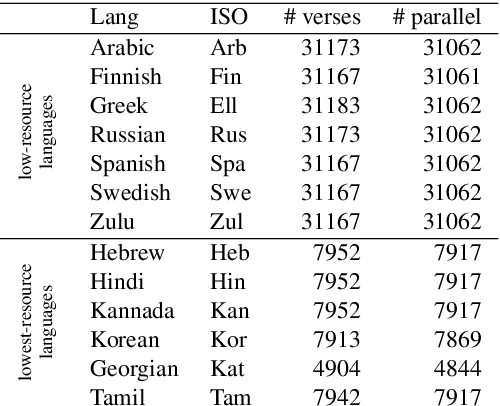
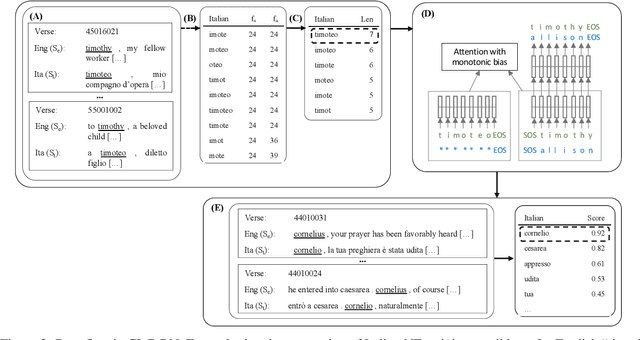
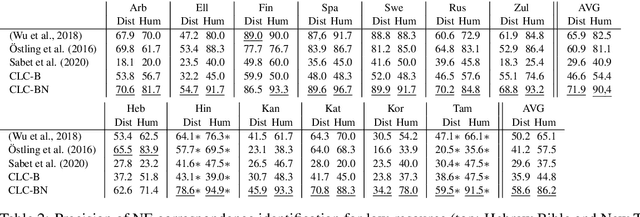
Parallel corpora are ideal for extracting a multilingual named entity (MNE) resource, i.e., a dataset of names translated into multiple languages. Prior work on extracting MNE datasets from parallel corpora required resources such as large monolingual corpora or word aligners that are unavailable or perform poorly for underresourced languages. We present CLC-BN, a new method for creating an MNE resource, and apply it to the Parallel Bible Corpus, a corpus of more than 1000 languages. CLC-BN learns a neural transliteration model from parallel-corpus statistics, without requiring any other bilingual resources, word aligners, or seed data. Experimental results show that CLC-BN clearly outperforms prior work. We release an MNE resource for 1340 languages and demonstrate its effectiveness in two downstream tasks: knowledge graph augmentation and bilingual lexicon induction.
CodeTrans: Towards Cracking the Language of Silicone's Code Through Self-Supervised Deep Learning and High Performance Computing
Apr 06, 2021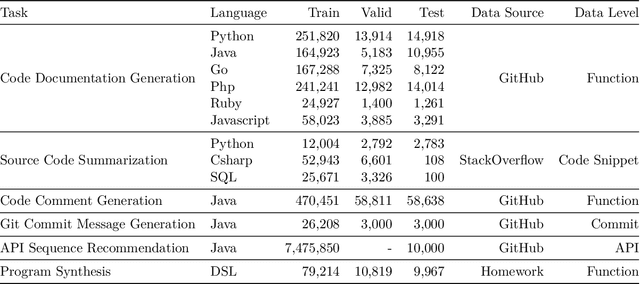
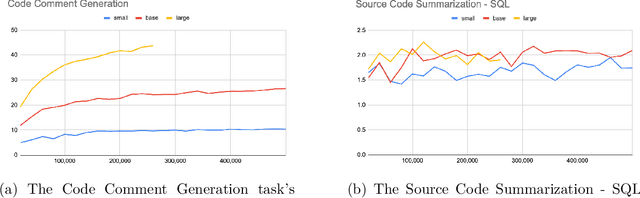
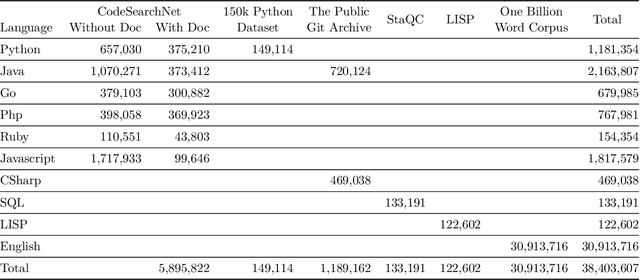
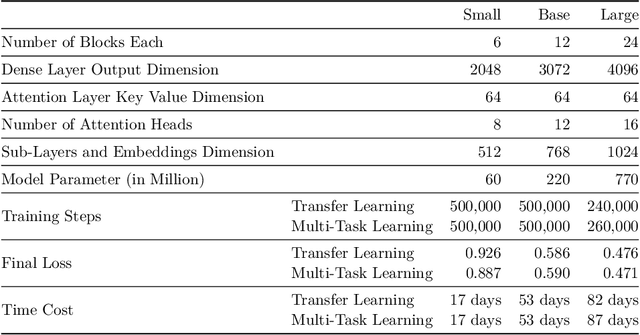
Currently, a growing number of mature natural language processing applications make people's life more convenient. Such applications are built by source code - the language in software engineering. However, the applications for understanding source code language to ease the software engineering process are under-researched. Simultaneously, the transformer model, especially its combination with transfer learning, has been proven to be a powerful technique for natural language processing tasks. These breakthroughs point out a promising direction for process source code and crack software engineering tasks. This paper describes CodeTrans - an encoder-decoder transformer model for tasks in the software engineering domain, that explores the effectiveness of encoder-decoder transformer models for six software engineering tasks, including thirteen sub-tasks. Moreover, we have investigated the effect of different training strategies, including single-task learning, transfer learning, multi-task learning, and multi-task learning with fine-tuning. CodeTrans outperforms the state-of-the-art models on all the tasks. To expedite future works in the software engineering domain, we have published our pre-trained models of CodeTrans. https://github.com/agemagician/CodeTrans