 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnkh3: Multi-Task Pretraining with Sequence Denoising and Completion Enhances Protein Representations
May 26, 2025Protein language models (PLMs) have emerged as powerful tools to detect complex patterns of protein sequences. However, the capability of PLMs to fully capture information on protein sequences might be limited by focusing on single pre-training tasks. Although adding data modalities or supervised objectives can improve the performance of PLMs, pre-training often remains focused on denoising corrupted sequences. To push the boundaries of PLMs, our research investigated a multi-task pre-training strategy. We developed Ankh3, a model jointly optimized on two objectives: masked language modeling with multiple masking probabilities and protein sequence completion relying only on protein sequences as input. This multi-task pre-training demonstrated that PLMs can learn richer and more generalizable representations solely from protein sequences. The results demonstrated improved performance in downstream tasks, such as secondary structure prediction, fluorescence, GB1 fitness, and contact prediction. The integration of multiple tasks gave the model a more comprehensive understanding of protein properties, leading to more robust and accurate predictions.
Beyond Simple Concatenation: Fairly Assessing PLM Architectures for Multi-Chain Protein-Protein Interactions Prediction
May 26, 2025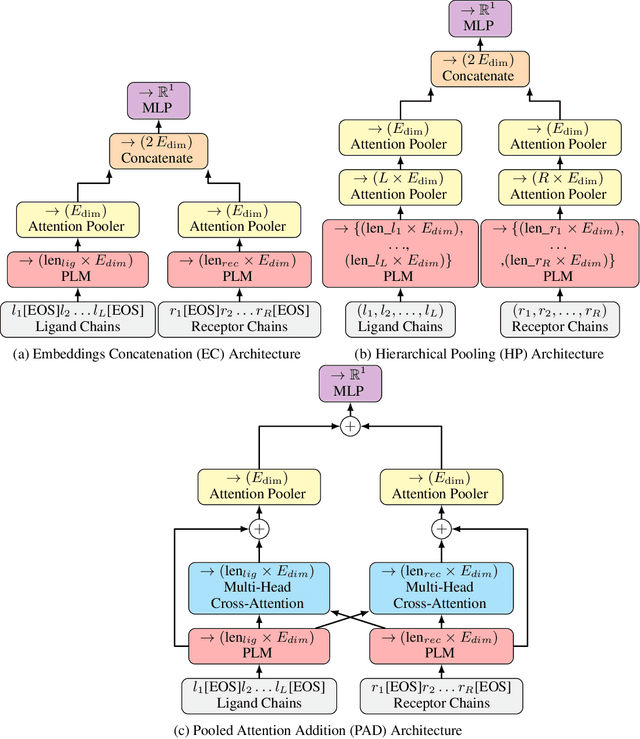
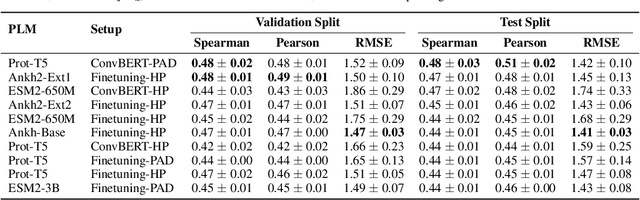
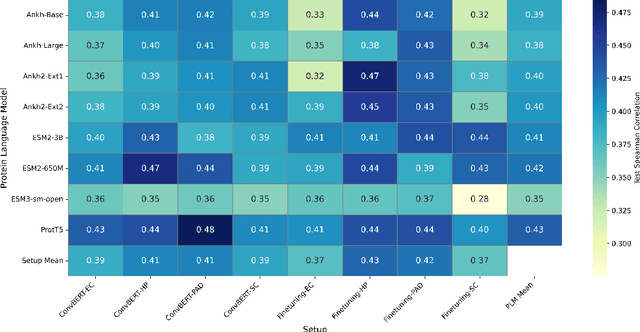
Protein-protein interactions (PPIs) are fundamental to numerous cellular processes, and their characterization is vital for understanding disease mechanisms and guiding drug discovery. While protein language models (PLMs) have demonstrated remarkable success in predicting protein structure and function, their application to sequence-based PPI binding affinity prediction remains relatively underexplored. This gap is often attributed to the scarcity of high-quality, rigorously refined datasets and the reliance on simple strategies for concatenating protein representations. In this work, we address these limitations. First, we introduce a meticulously curated version of the PPB-Affinity dataset of a total of 8,207 unique protein-protein interaction entries, by resolving annotation inconsistencies and duplicate entries for multi-chain protein interactions. This dataset incorporates a stringent, less than or equal to 30%, sequence identity threshold to ensure robust splitting into training, validation, and test sets, minimizing data leakage. Second, we propose and systematically evaluate four architectures for adapting PLMs to PPI binding affinity prediction: embeddings concatenation (EC), sequences concatenation (SC), hierarchical pooling (HP), and pooled attention addition (PAD). These architectures were assessed using two training methods: full fine-tuning and a lightweight approach employing ConvBERT heads over frozen PLM features. Our comprehensive experiments across multiple leading PLMs (ProtT5, ESM2, Ankh, Ankh2, and ESM3) demonstrated that the HP and PAD architectures consistently outperform conventional concatenation methods, achieving up to 12% increase in terms of Spearman correlation. These results highlight the necessity of sophisticated architectural designs to fully exploit the capabilities of PLMs for nuanced PPI binding affinity prediction.
Ankh: Optimized Protein Language Model Unlocks General-Purpose Modelling
Jan 16, 2023As opposed to scaling-up protein language models (PLMs), we seek improving performance via protein-specific optimization. Although the proportionality between the language model size and the richness of its learned representations is validated, we prioritize accessibility and pursue a path of data-efficient, cost-reduced, and knowledge-guided optimization. Through over twenty experiments ranging from masking, architecture, and pre-training data, we derive insights from protein-specific experimentation into building a model that interprets the language of life, optimally. We present Ankh, the first general-purpose PLM trained on Google's TPU-v4 surpassing the state-of-the-art performance with fewer parameters (<10% for pre-training, <7% for inference, and <30% for the embedding dimension). We provide a representative range of structure and function benchmarks where Ankh excels. We further provide a protein variant generation analysis on High-N and One-N input data scales where Ankh succeeds in learning protein evolutionary conservation-mutation trends and introducing functional diversity while retaining key structural-functional characteristics. We dedicate our work to promoting accessibility to research innovation via attainable resources.
CodeTrans: Towards Cracking the Language of Silicone's Code Through Self-Supervised Deep Learning and High Performance Computing
Apr 06, 2021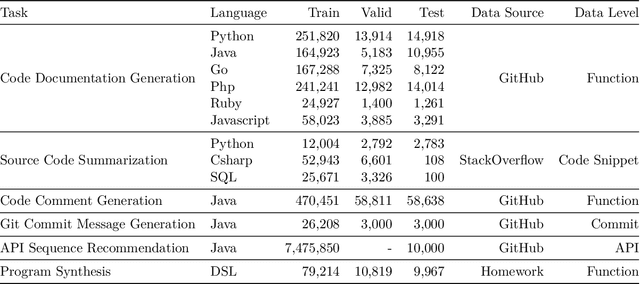
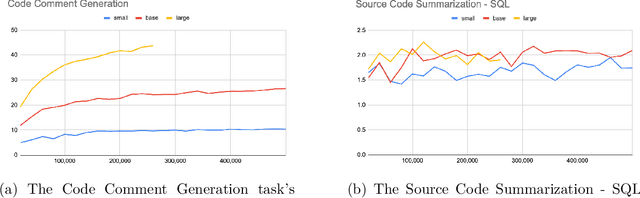
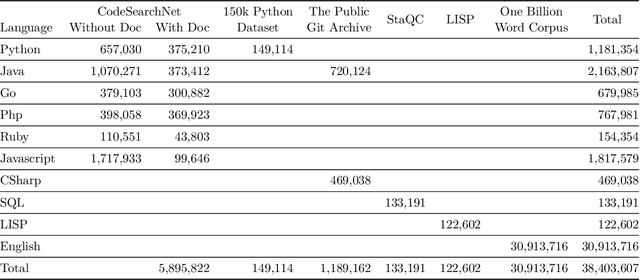
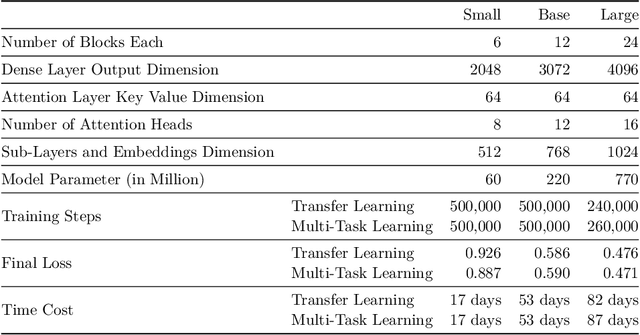
Currently, a growing number of mature natural language processing applications make people's life more convenient. Such applications are built by source code - the language in software engineering. However, the applications for understanding source code language to ease the software engineering process are under-researched. Simultaneously, the transformer model, especially its combination with transfer learning, has been proven to be a powerful technique for natural language processing tasks. These breakthroughs point out a promising direction for process source code and crack software engineering tasks. This paper describes CodeTrans - an encoder-decoder transformer model for tasks in the software engineering domain, that explores the effectiveness of encoder-decoder transformer models for six software engineering tasks, including thirteen sub-tasks. Moreover, we have investigated the effect of different training strategies, including single-task learning, transfer learning, multi-task learning, and multi-task learning with fine-tuning. CodeTrans outperforms the state-of-the-art models on all the tasks. To expedite future works in the software engineering domain, we have published our pre-trained models of CodeTrans. https://github.com/agemagician/CodeTrans
ProtTrans: Towards Cracking the Language of Life's Code Through Self-Supervised Deep Learning and High Performance Computing
Jul 20, 2020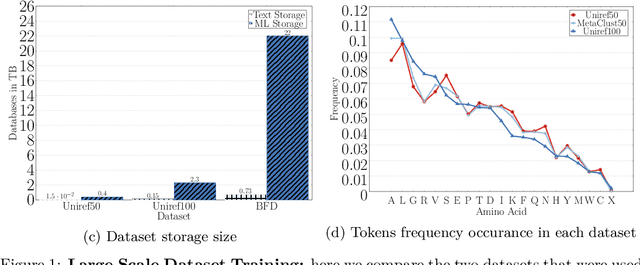
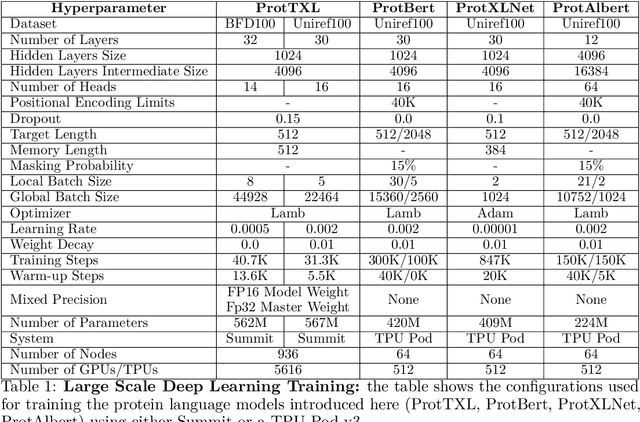
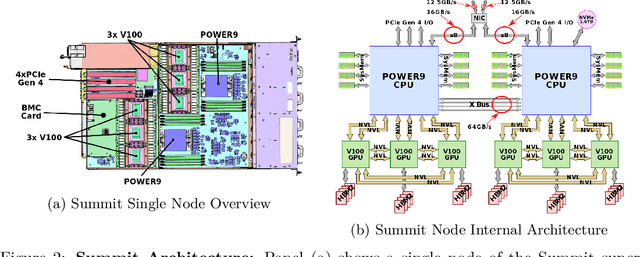
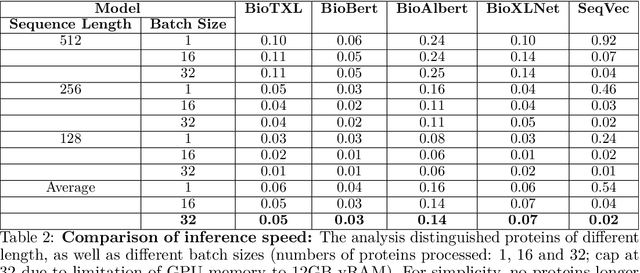
Computational biology and bioinformatics provide vast data gold-mines from protein sequences, ideal for Language Models (LMs) taken from Natural Language Processing (NLP). These LMs reach for new prediction frontiers at low inference costs. Here, we trained two auto-regressive language models (Transformer-XL, XLNet) and two auto-encoder models (Bert, Albert) on data from UniRef and BFD containing up to 393 billion amino acids (words) from 2.1 billion protein sequences (22- and 112-times the entire English Wikipedia). The LMs were trained on the Summit supercomputer at Oak Ridge National Laboratory (ORNL), using 936 nodes (total 5616 GPUs) and one TPU Pod (V3-512 or V3-1024). We validated the advantage of up-scaling LMs to larger models supported by bigger data by predicting secondary structure (3-states: Q3=76-84, 8-states: Q8=65-73), sub-cellular localization for 10 cellular compartments (Q10=74) and whether a protein is membrane-bound or water-soluble (Q2=89). Dimensionality reduction revealed that the LM-embeddings from unlabeled data (only protein sequences) captured important biophysical properties governing protein shape. This implied learning some of the grammar of the language of life realized in protein sequences. The successful up-scaling of protein LMs through HPC to larger data sets slightly reduced the gap between models trained on evolutionary information and LMs. The official GitHub repository: https://github.com/agemagician/ProtTrans
Multi-Task Deep Learning for Legal Document Translation, Summarization and Multi-Label Classification
Oct 16, 2018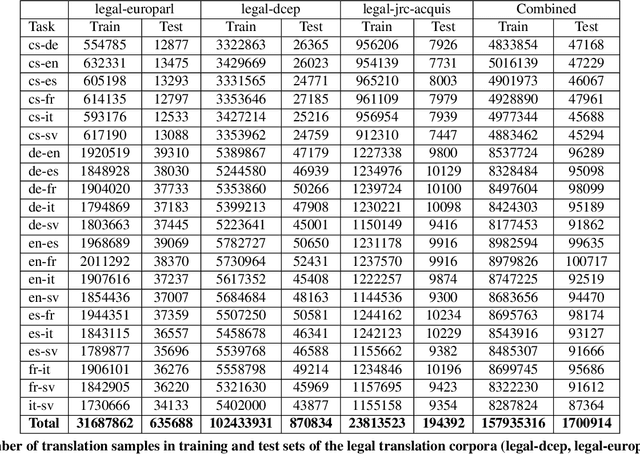
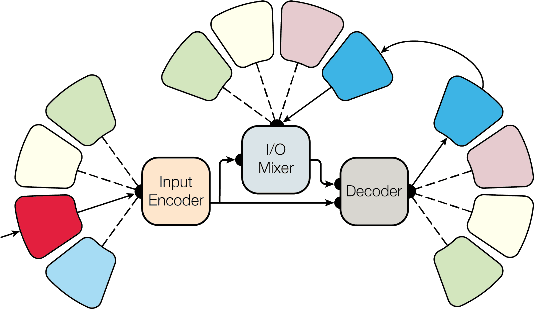
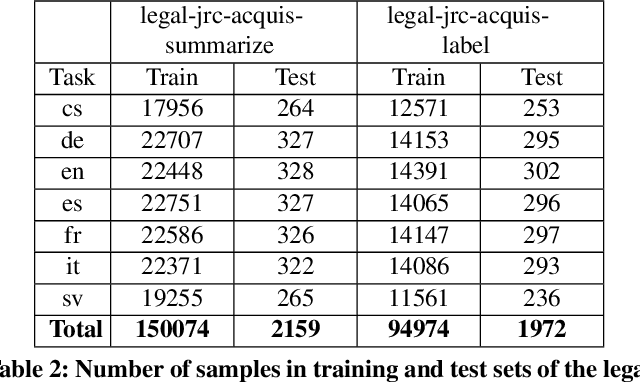
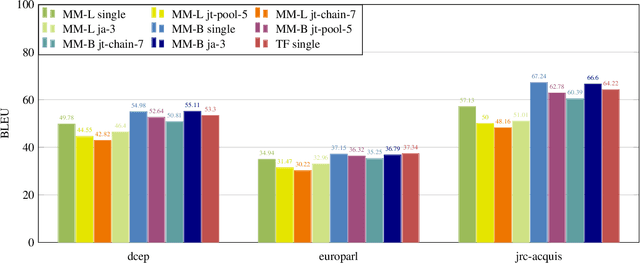
The digitalization of the legal domain has been ongoing for a couple of years. In that process, the application of different machine learning (ML) techniques is crucial. Tasks such as the classification of legal documents or contract clauses as well as the translation of those are highly relevant. On the other side, digitized documents are barely accessible in this field, particularly in Germany. Today, deep learning (DL) is one of the hot topics with many publications and various applications. Sometimes it provides results outperforming the human level. Hence this technique may be feasible for the legal domain as well. However, DL requires thousands of samples to provide decent results. A potential solution to this problem is multi-task DL to enable transfer learning. This approach may be able to overcome the data scarcity problem in the legal domain, specifically for the German language. We applied the state of the art multi-task model on three tasks: translation, summarization, and multi-label classification. The experiments were conducted on legal document corpora utilizing several task combinations as well as various model parameters. The goal was to find the optimal configuration for the tasks at hand within the legal domain. The multi-task DL approach outperformed the state of the art results in all three tasks. This opens a new direction to integrate DL technology more efficiently in the legal domain.
Named-Entity Linking Using Deep Learning For Legal Documents: A Transfer Learning Approach
Oct 15, 2018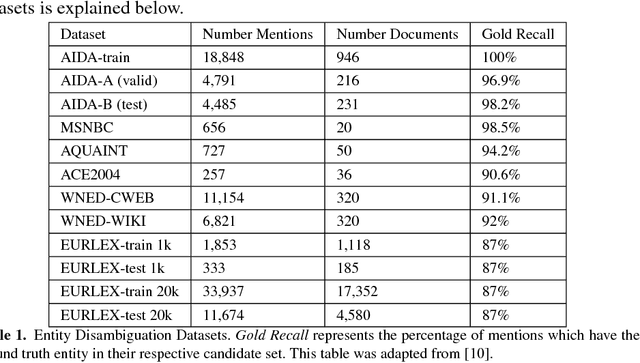
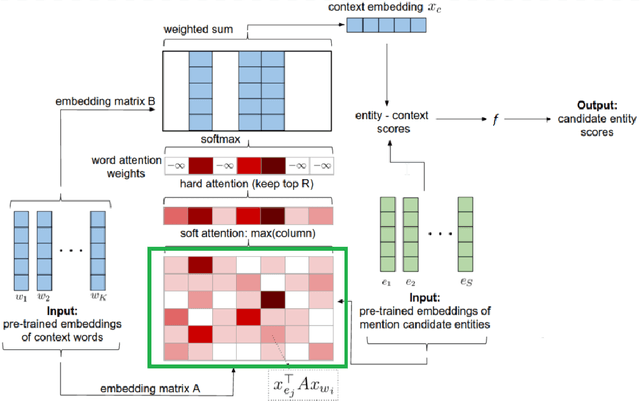
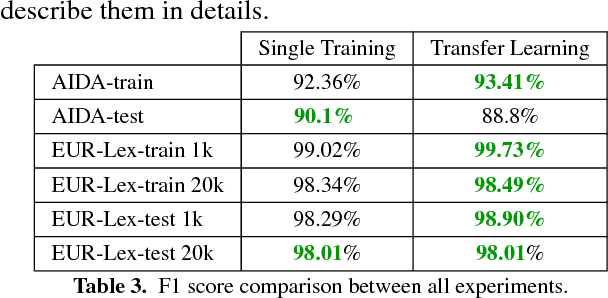
In the legal domain it is important to differentiate between words in general, and afterwards to link the occurrences of the same entities. The topic to solve these challenges is called Named-Entity Linking (NEL). Current supervised neural networks designed for NEL use publicly available datasets for training and testing. However, this paper focuses especially on the aspect of applying transfer learning approach using networks trained for NEL to legal documents. Experiments show consistent improvement in the legal datasets that were created from the European Union law in the scope of this research. Using transfer learning approach, we reached F1-score of 98.90\% and 98.01\% on the legal small and large test dataset.
Stop Illegal Comments: A Multi-Task Deep Learning Approach
Oct 15, 2018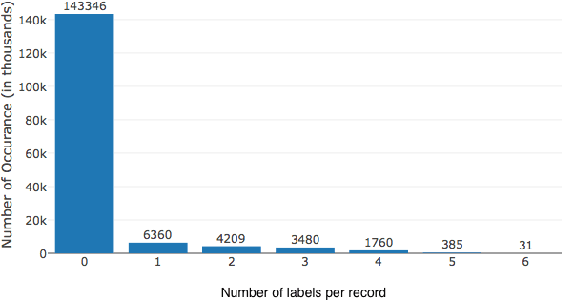
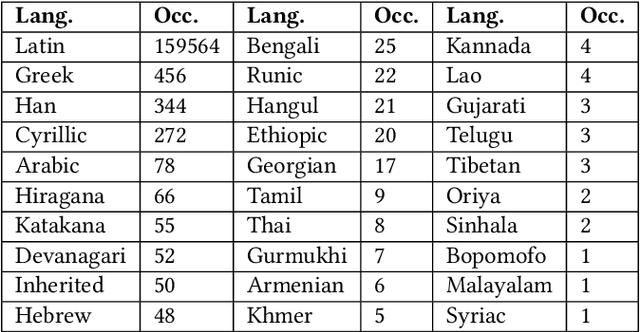
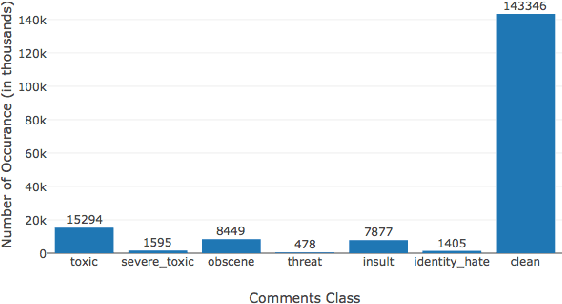
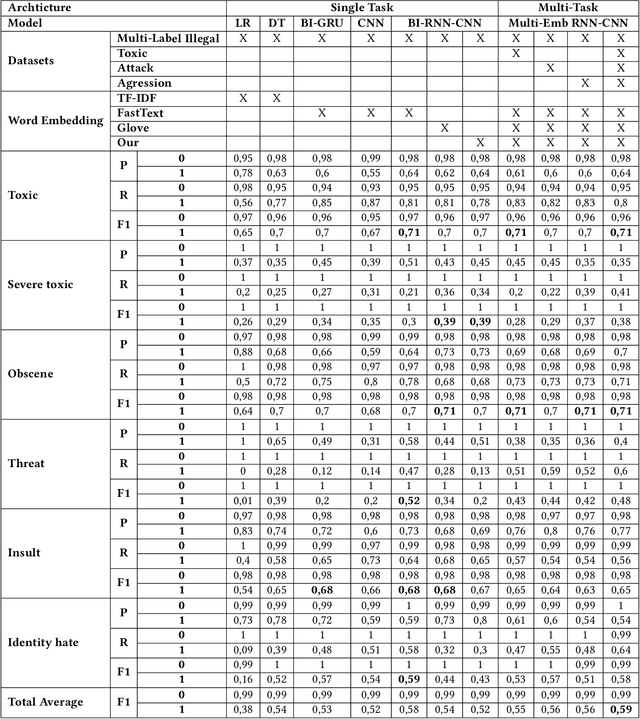
Deep learning methods are often difficult to apply in the legal domain due to the large amount of labeled data required by deep learning methods. A recent new trend in the deep learning community is the application of multi-task models that enable single deep neural networks to perform more than one task at the same time, for example classification and translation tasks. These powerful novel models are capable of transferring knowledge among different tasks or training sets and therefore could open up the legal domain for many deep learning applications. In this paper, we investigate the transfer learning capabilities of such a multi-task model on a classification task on the publicly available Kaggle toxic comment dataset for classifying illegal comments and we can report promising results.