 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnkh: Optimized Protein Language Model Unlocks General-Purpose Modelling
Jan 16, 2023As opposed to scaling-up protein language models (PLMs), we seek improving performance via protein-specific optimization. Although the proportionality between the language model size and the richness of its learned representations is validated, we prioritize accessibility and pursue a path of data-efficient, cost-reduced, and knowledge-guided optimization. Through over twenty experiments ranging from masking, architecture, and pre-training data, we derive insights from protein-specific experimentation into building a model that interprets the language of life, optimally. We present Ankh, the first general-purpose PLM trained on Google's TPU-v4 surpassing the state-of-the-art performance with fewer parameters (<10% for pre-training, <7% for inference, and <30% for the embedding dimension). We provide a representative range of structure and function benchmarks where Ankh excels. We further provide a protein variant generation analysis on High-N and One-N input data scales where Ankh succeeds in learning protein evolutionary conservation-mutation trends and introducing functional diversity while retaining key structural-functional characteristics. We dedicate our work to promoting accessibility to research innovation via attainable resources.
Modeling German Verb Argument Structures: LSTMs vs. Humans
Nov 30, 2019
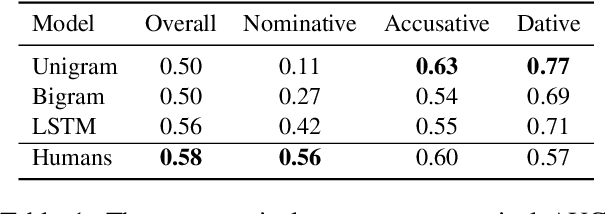
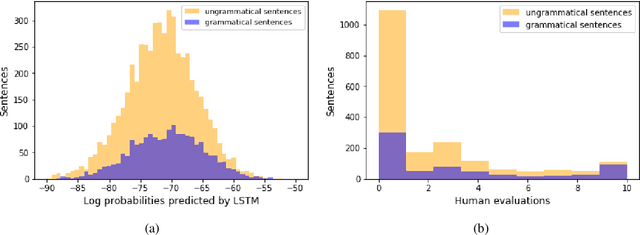
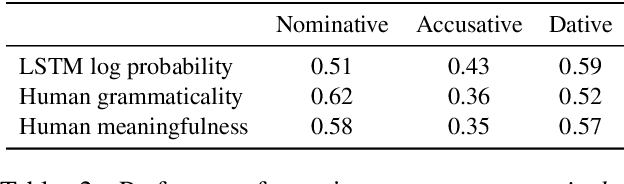
LSTMs have proven very successful at language modeling. However, it remains unclear to what extent they are able to capture complex morphosyntactic structures. In this paper, we examine whether LSTMs are sensitive to verb argument structures. We introduce a German grammaticality dataset in which ungrammatical sentences are constructed by manipulating case assignments (eg substituting nominative by accusative or dative). We find that LSTMs are better than chance in detecting incorrect argument structures and slightly worse than humans tested on the same dataset. Surprisingly, LSTMs are contaminated by heuristics not found in humans like a preference toward nominative noun phrases. In other respects they show human-similar results like biases for particular orders of case assignments.