 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Deep Learning for Legal Document Translation, Summarization and Multi-Label Classification
Paper and Code
Oct 16, 2018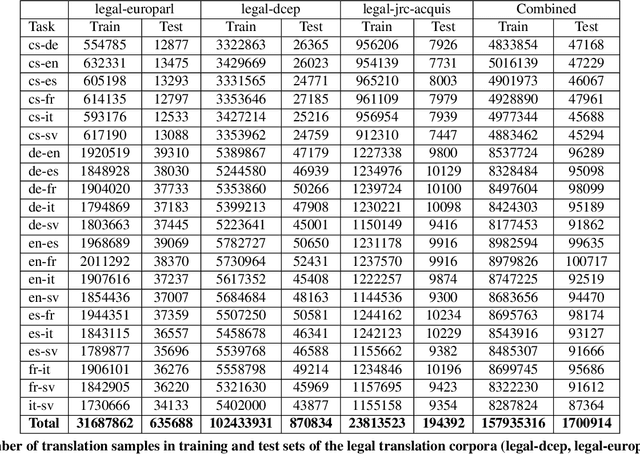
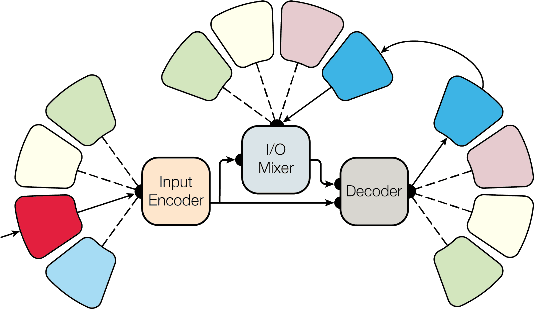
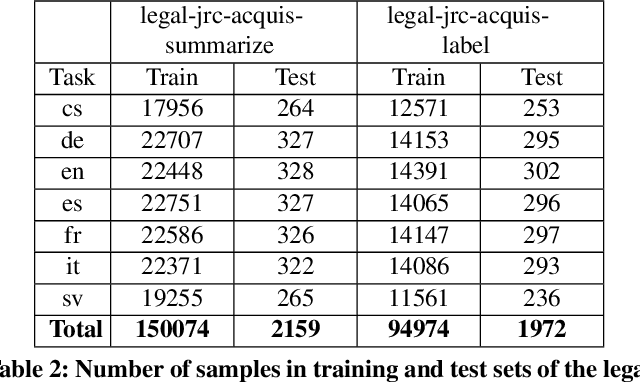
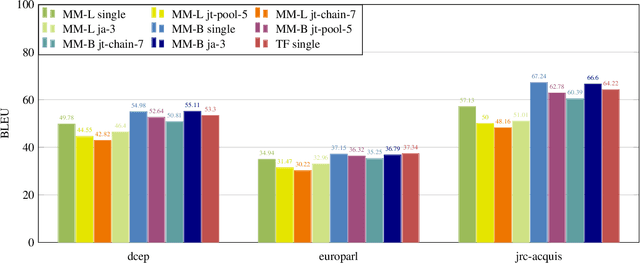
The digitalization of the legal domain has been ongoing for a couple of years. In that process, the application of different machine learning (ML) techniques is crucial. Tasks such as the classification of legal documents or contract clauses as well as the translation of those are highly relevant. On the other side, digitized documents are barely accessible in this field, particularly in Germany. Today, deep learning (DL) is one of the hot topics with many publications and various applications. Sometimes it provides results outperforming the human level. Hence this technique may be feasible for the legal domain as well. However, DL requires thousands of samples to provide decent results. A potential solution to this problem is multi-task DL to enable transfer learning. This approach may be able to overcome the data scarcity problem in the legal domain, specifically for the German language. We applied the state of the art multi-task model on three tasks: translation, summarization, and multi-label classification. The experiments were conducted on legal document corpora utilizing several task combinations as well as various model parameters. The goal was to find the optimal configuration for the tasks at hand within the legal domain. The multi-task DL approach outperformed the state of the art results in all three tasks. This opens a new direction to integrate DL technology more efficiently in the legal domain.