 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Relation-Specific Neurons in Large Language Models
Feb 24, 2025In large language models (LLMs), certain neurons can store distinct pieces of knowledge learned during pretraining. While knowledge typically appears as a combination of relations and entities, it remains unclear whether some neurons focus on a relation itself -- independent of any entity. We hypothesize such neurons detect a relation in the input text and guide generation involving such a relation. To investigate this, we study the Llama-2 family on a chosen set of relations with a statistics-based method. Our experiments demonstrate the existence of relation-specific neurons. We measure the effect of selectively deactivating candidate neurons specific to relation $r$ on the LLM's ability to handle (1) facts whose relation is $r$ and (2) facts whose relation is a different relation $r' \neq r$. With respect to their capacity for encoding relation information, we give evidence for the following three properties of relation-specific neurons. $\textbf{(i) Neuron cumulativity.}$ The neurons for $r$ present a cumulative effect so that deactivating a larger portion of them results in the degradation of more facts in $r$. $\textbf{(ii) Neuron versatility.}$ Neurons can be shared across multiple closely related as well as less related relations. Some relation neurons transfer across languages. $\textbf{(iii) Neuron interference.}$ Deactivating neurons specific to one relation can improve LLM generation performance for facts of other relations. We will make our code publicly available at https://github.com/cisnlp/relation-specific-neurons.
Citance-Contextualized Summarization of Scientific Papers
Nov 13, 2023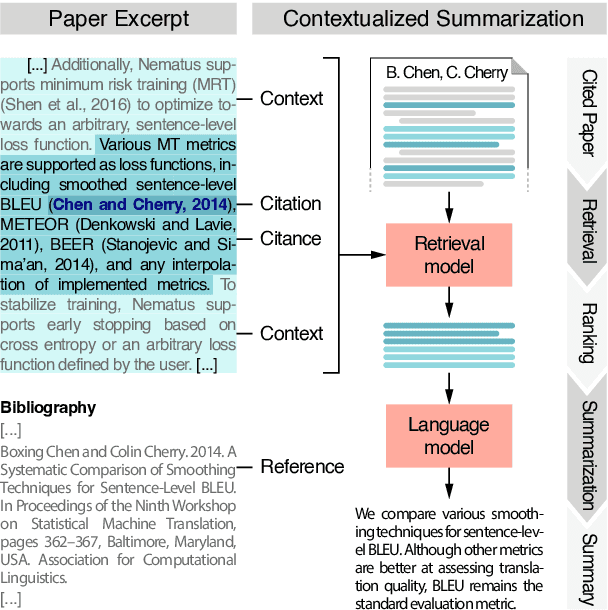
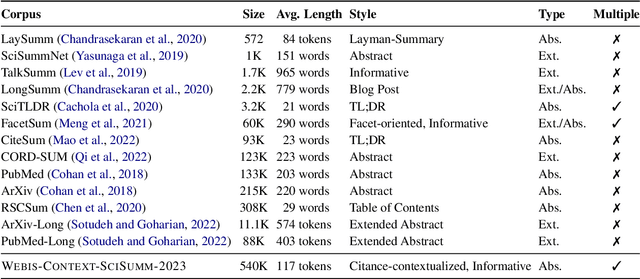

Current approaches to automatic summarization of scientific papers generate informative summaries in the form of abstracts. However, abstracts are not intended to show the relationship between a paper and the references cited in it. We propose a new contextualized summarization approach that can generate an informative summary conditioned on a given sentence containing the citation of a reference (a so-called "citance"). This summary outlines the content of the cited paper relevant to the citation location. Thus, our approach extracts and models the citances of a paper, retrieves relevant passages from cited papers, and generates abstractive summaries tailored to each citance. We evaluate our approach using $\textbf{Webis-Context-SciSumm-2023}$, a new dataset containing 540K~computer science papers and 4.6M~citances therein.