 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASAI: Modular Architecture for Software-engineering AI Agents
Jun 17, 2024A common method to solve complex problems in software engineering, is to divide the problem into multiple sub-problems. Inspired by this, we propose a Modular Architecture for Software-engineering AI (MASAI) agents, where different LLM-powered sub-agents are instantiated with well-defined objectives and strategies tuned to achieve those objectives. Our modular architecture offers several advantages: (1) employing and tuning different problem-solving strategies across sub-agents, (2) enabling sub-agents to gather information from different sources scattered throughout a repository, and (3) avoiding unnecessarily long trajectories which inflate costs and add extraneous context. MASAI enabled us to achieve the highest performance (28.33% resolution rate) on the popular and highly challenging SWE-bench Lite dataset consisting of 300 GitHub issues from 11 Python repositories. We conduct a comprehensive evaluation of MASAI relative to other agentic methods and analyze the effects of our design decisions and their contribution to the success of MASAI.
Class-Level Code Generation from Natural Language Using Iterative, Tool-Enhanced Reasoning over Repository
Apr 22, 2024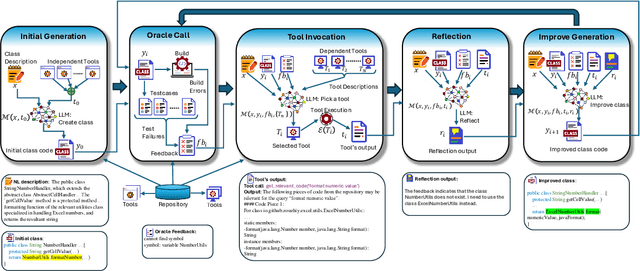
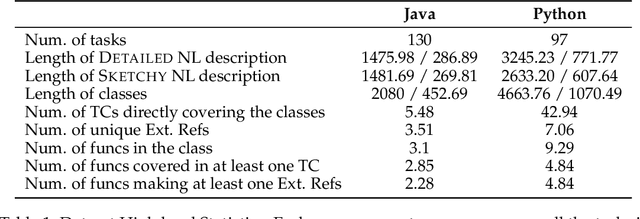

LLMs have demonstrated significant potential in code generation tasks, achieving promising results at the function or statement level in various benchmarks. However, the complexities associated with creating code artifacts like classes, particularly within the context of real-world software repositories, remain underexplored. Existing research often treats class-level generation as an isolated task, neglecting the intricate dependencies and interactions that characterize real-world software development environments. To address this gap, we introduce RepoClassBench, a benchmark designed to rigorously evaluate LLMs in generating complex, class-level code within real-world repositories. RepoClassBench includes natural language to class generation tasks across Java and Python, from a selection of public repositories. We ensure that each class in our dataset not only has cross-file dependencies within the repository but also includes corresponding test cases to verify its functionality. We find that current models struggle with the realistic challenges posed by our benchmark, primarily due to their limited exposure to relevant repository contexts. To address this shortcoming, we introduce Retrieve-Repotools-Reflect (RRR), a novel approach that equips LLMs with static analysis tools to iteratively navigate & reason about repository-level context in an agent-based framework. Our experiments demonstrate that RRR significantly outperforms existing baselines on RepoClassBench, showcasing its effectiveness across programming languages and in various settings. Our findings emphasize the need for benchmarks that incorporate repository-level dependencies to more accurately reflect the complexities of software development. Our work illustrates the benefits of leveraging specialized tools to enhance LLMs understanding of repository context. We plan to make our dataset and evaluation harness public.
FiGURe: Simple and Efficient Unsupervised Node Representations with Filter Augmentations
Oct 04, 2023



Unsupervised node representations learnt using contrastive learning-based methods have shown good performance on downstream tasks. However, these methods rely on augmentations that mimic low-pass filters, limiting their performance on tasks requiring different eigen-spectrum parts. This paper presents a simple filter-based augmentation method to capture different parts of the eigen-spectrum. We show significant improvements using these augmentations. Further, we show that sharing the same weights across these different filter augmentations is possible, reducing the computational load. In addition, previous works have shown that good performance on downstream tasks requires high dimensional representations. Working with high dimensions increases the computations, especially when multiple augmentations are involved. We mitigate this problem and recover good performance through lower dimensional embeddings using simple random Fourier feature projections. Our method, FiGURe achieves an average gain of up to 4.4%, compared to the state-of-the-art unsupervised models, across all datasets in consideration, both homophilic and heterophilic. Our code can be found at: https://github.com/microsoft/figure.
User Embedding based Neighborhood Aggregation Method for Inductive Recommendation
Feb 16, 2021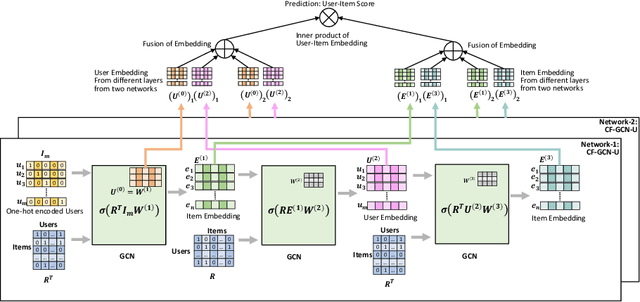
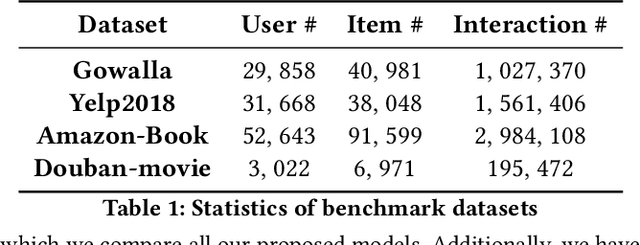
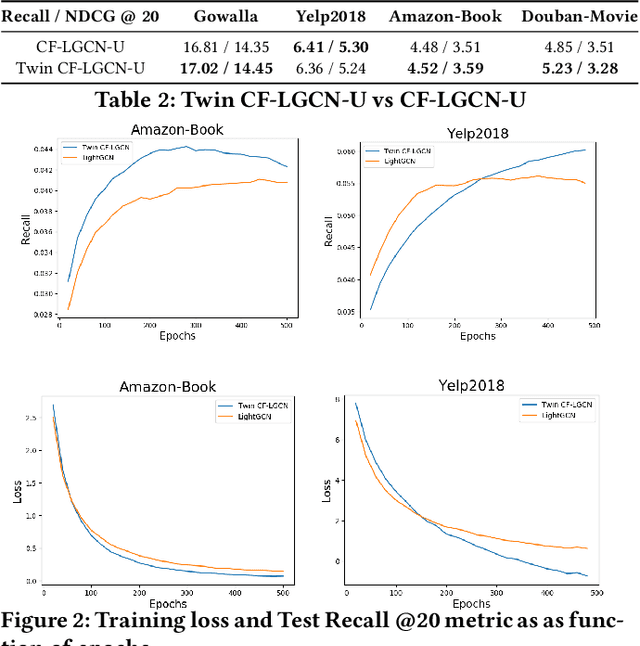
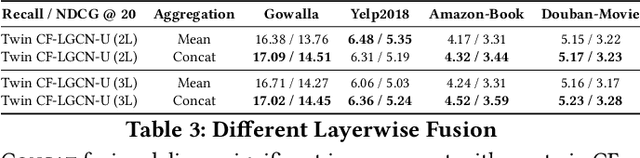
We consider the problem of learning latent features (aka embedding) for users and items in a recommendation setting. Given only a user-item interaction graph, the goal is to recommend items for each user. Traditional approaches employ matrix factorization-based collaborative filtering methods. Recent methods using graph convolutional networks (e.g., LightGCN) achieve state-of-the-art performance. They learn both user and item embedding. One major drawback of most existing methods is that they are not inductive; they do not generalize for users and items unseen during training. Besides, existing network models are quite complex, difficult to train and scale. Motivated by LightGCN, we propose a graph convolutional network modeling approach for collaborative filtering CF-GCN. We solely learn user embedding and derive item embedding using light variant CF-LGCN-U performing neighborhood aggregation, making it scalable due to reduced model complexity. CF-LGCN-U models naturally possess the inductive capability for new items, and we propose a simple solution to generalize for new users. We show how the proposed models are related to LightGCN. As a by-product, we suggest a simple solution to make LightGCN inductive. We perform comprehensive experiments on several benchmark datasets and demonstrate the capabilities of the proposed approach. Experimental results show that similar or better generalization performance is achievable than the state of the art methods in both transductive and inductive settings.