 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Answer Semantic Queries over Code
Sep 17, 2022
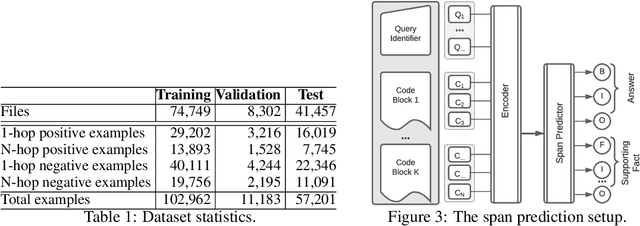
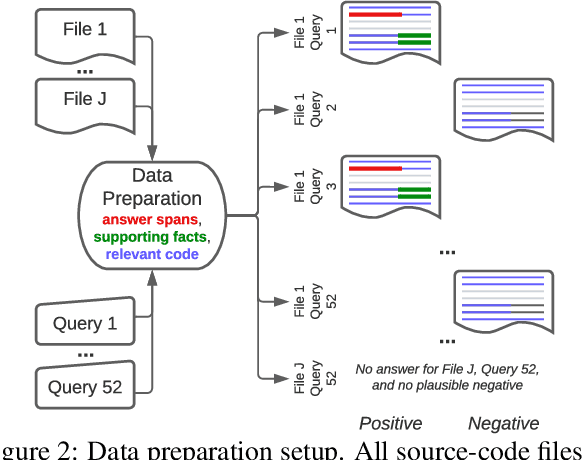

During software development, developers need answers to queries about semantic aspects of code. Even though extractive question-answering using neural approaches has been studied widely in natural languages, the problem of answering semantic queries over code using neural networks has not yet been explored. This is mainly because there is no existing dataset with extractive question and answer pairs over code involving complex concepts and long chains of reasoning. We bridge this gap by building a new, curated dataset called CodeQueries, and proposing a neural question-answering methodology over code. We build upon state-of-the-art pre-trained models of code to predict answer and supporting-fact spans. Given a query and code, only some of the code may be relevant to answer the query. We first experiment under an ideal setting where only the relevant code is given to the model and show that our models do well. We then experiment under three pragmatic considerations: (1) scaling to large-size code, (2) learning from a limited number of examples and (3) robustness to minor syntax errors in code. Our results show that while a neural model can be resilient to minor syntax errors in code, increasing size of code, presence of code that is not relevant to the query, and reduced number of training examples limit the model performance. We are releasing our data and models to facilitate future work on the proposed problem of answering semantic queries over code.
HyperTeNet: Hypergraph and Transformer-based Neural Network for Personalized List Continuation
Oct 07, 2021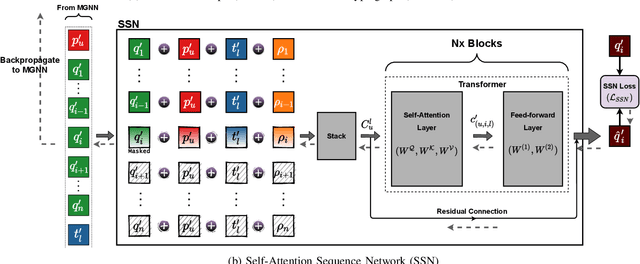
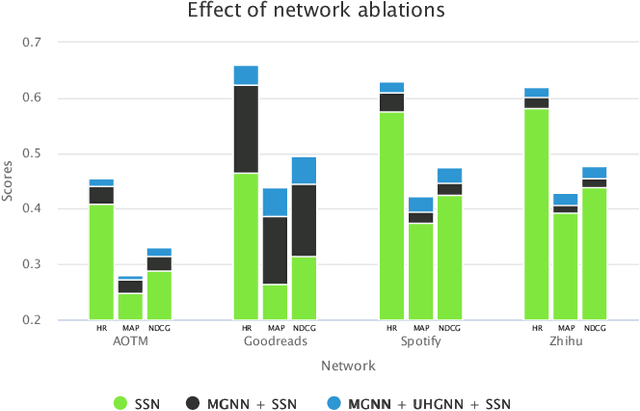
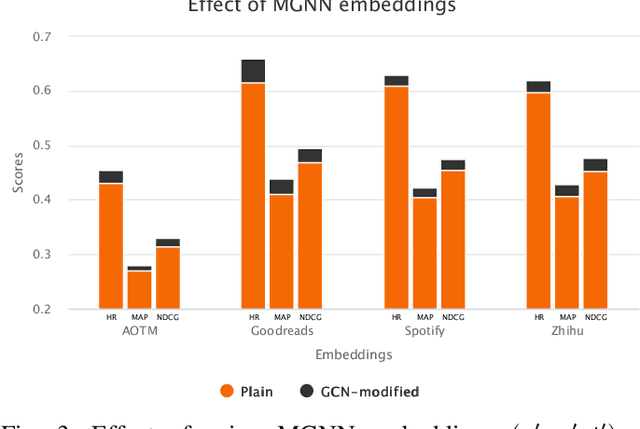
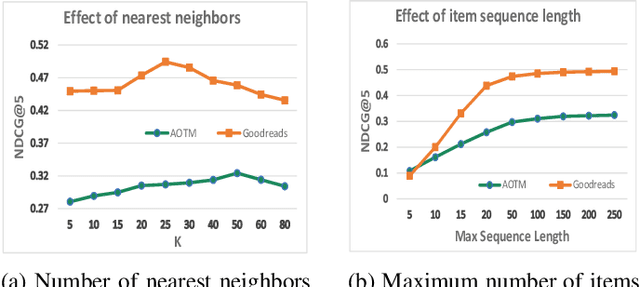
The personalized list continuation (PLC) task is to curate the next items to user-generated lists (ordered sequence of items) in a personalized way. The main challenge in this task is understanding the ternary relationships among the interacting entities (users, items, and lists) that the existing works do not consider. Further, they do not take into account the multi-hop relationships among entities of the same type. In addition, capturing the sequential information amongst the items already present in the list also plays a vital role in determining the next relevant items that get curated. In this work, we propose HyperTeNet -- a self-attention hypergraph and Transformer-based neural network architecture for the personalized list continuation task to address the challenges mentioned above. We use graph convolutions to learn the multi-hop relationship among the entities of the same type and leverage a self-attention-based hypergraph neural network to learn the ternary relationships among the interacting entities via hyperlink prediction in a 3-uniform hypergraph. Further, the entity embeddings are shared with a Transformer-based architecture and are learned through an alternating optimization procedure. As a result, this network also learns the sequential information needed to curate the next items to be added to the list. Experimental results demonstrate that HyperTeNet significantly outperforms the other state-of-the-art models on real-world datasets. Our implementation and datasets are available at https://github.com/mvijaikumar/HyperTeNet.
Stateful Detection of Model Extraction Attacks
Jul 12, 2021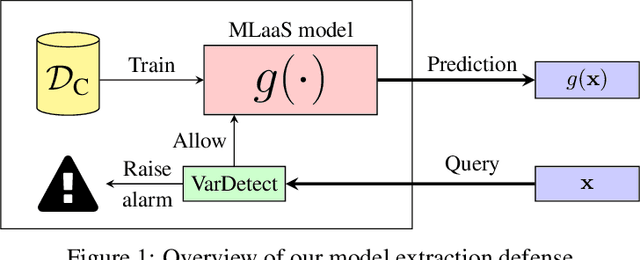
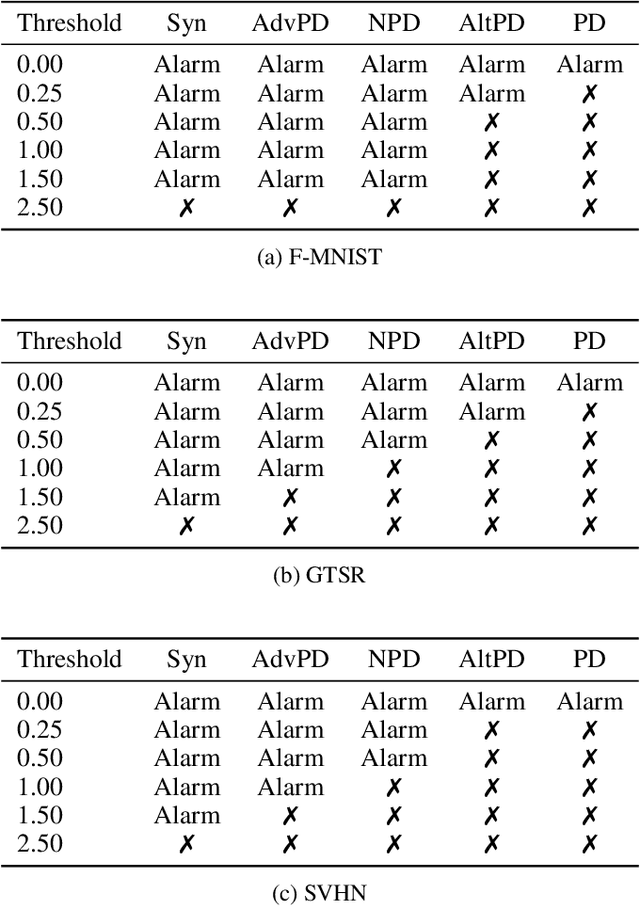

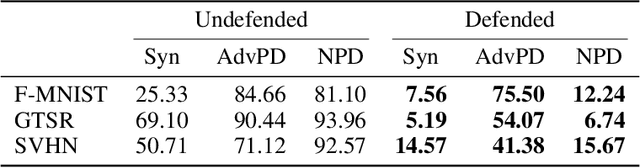
Machine-Learning-as-a-Service providers expose machine learning (ML) models through application programming interfaces (APIs) to developers. Recent work has shown that attackers can exploit these APIs to extract good approximations of such ML models, by querying them with samples of their choosing. We propose VarDetect, a stateful monitor that tracks the distribution of queries made by users of such a service, to detect model extraction attacks. Harnessing the latent distributions learned by a modified variational autoencoder, VarDetect robustly separates three types of attacker samples from benign samples, and successfully raises an alarm for each. Further, with VarDetect deployed as an automated defense mechanism, the extracted substitute models are found to exhibit poor performance and transferability, as intended. Finally, we demonstrate that even adaptive attackers with prior knowledge of the deployment of VarDetect, are detected by it.
Neural Cross-Domain Collaborative Filtering with Shared Entities
Jul 19, 2019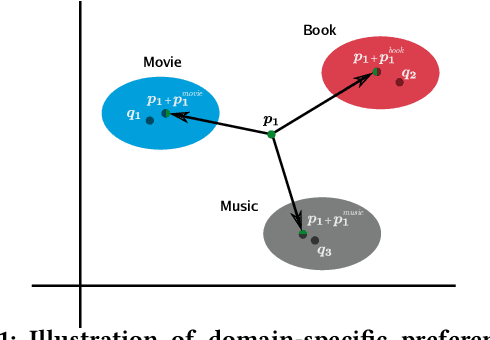
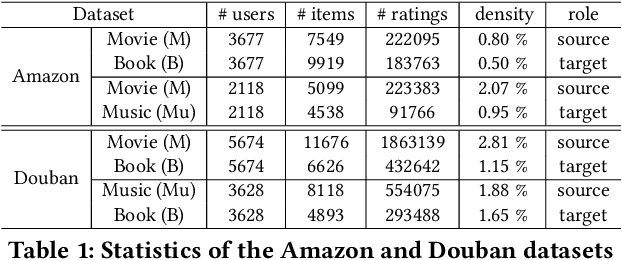
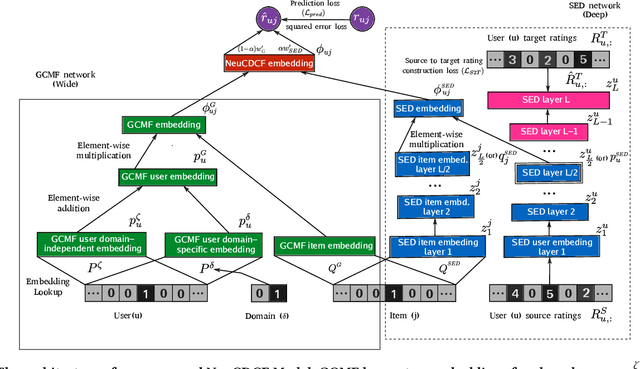
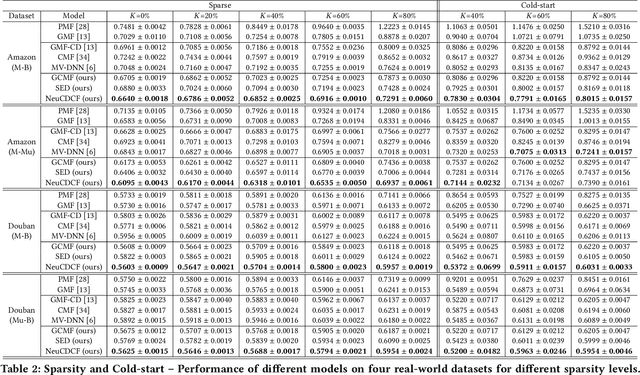
Cross-Domain Collaborative Filtering (CDCF) provides a way to alleviate data sparsity and cold-start problems present in recommendation systems by exploiting the knowledge from related domains. Existing CDCF models are either based on matrix factorization or deep neural networks. Either of the techniques in isolation may result in suboptimal performance for the prediction task. Also, most of the existing models face challenges particularly in handling diversity between domains and learning complex non-linear relationships that exist amongst entities (users/items) within and across domains. In this work, we propose an end-to-end neural network model -- NeuCDCF, to address these challenges in a cross-domain setting. More importantly, NeuCDCF follows a wide and deep framework and it learns the representations combinedly from both matrix factorization and deep neural networks. We perform experiments on four real-world datasets and demonstrate that our model performs better than state-of-the-art CDCF models.
Deep Learning for Bug-Localization in Student Programs
May 28, 2019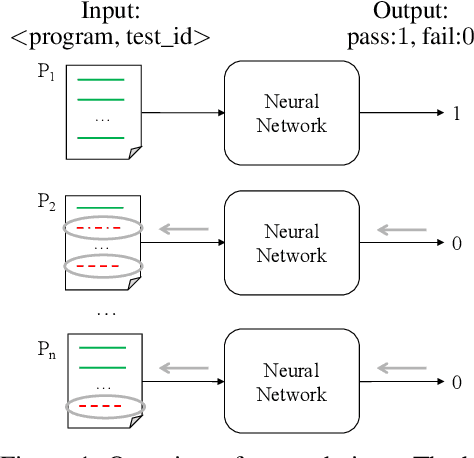


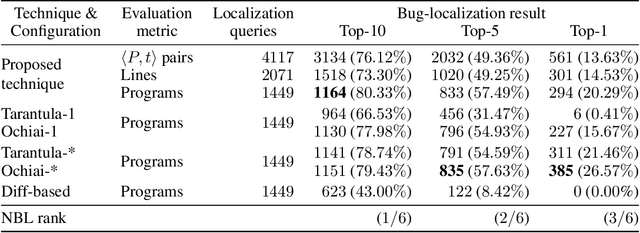
Providing feedback is an integral part of teaching. Most open online courses on programming make use of automated grading systems to support programming assignments and give real-time feedback. These systems usually rely on test results to quantify the programs' functional correctness. They return failing tests to the students as feedback. However, students may find it difficult to debug their programs if they receive no hints about where the bug is and how to fix it. In this work, we present the first deep learning based technique that can localize bugs in a faulty program w.r.t. a failing test, without even running the program. At the heart of our technique is a novel tree convolutional neural network which is trained to predict whether a program passes or fails a given test. To localize the bugs, we analyze the trained network using a state-of-the-art neural prediction attribution technique and see which lines of the programs make it predict the test outcomes. Our experiments show that the proposed technique is generally more accurate than two state-of-the-art program-spectrum based and one syntactic difference based bug-localization baselines.
A framework for the extraction of Deep Neural Networks by leveraging public data
May 22, 2019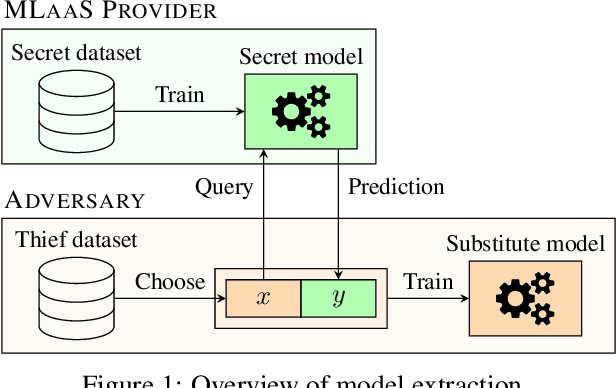


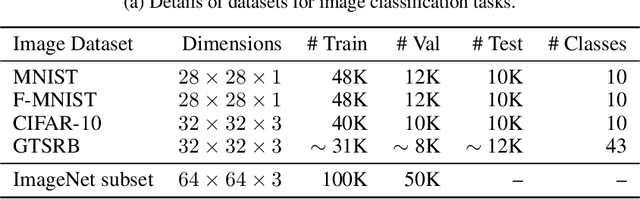
Machine learning models trained on confidential datasets are increasingly being deployed for profit. Machine Learning as a Service (MLaaS) has made such models easily accessible to end-users. Prior work has developed model extraction attacks, in which an adversary extracts an approximation of MLaaS models by making black-box queries to it. However, none of these works is able to satisfy all the three essential criteria for practical model extraction: (1) the ability to work on deep learning models, (2) the non-requirement of domain knowledge and (3) the ability to work with a limited query budget. We design a model extraction framework that makes use of active learning and large public datasets to satisfy them. We demonstrate that it is possible to use this framework to steal deep classifiers trained on a variety of datasets from image and text domains. By querying a model via black-box access for its top prediction, our framework improves performance on an average over a uniform noise baseline by 4.70x for image tasks and 2.11x for text tasks respectively, while using only 30% (30,000 samples) of the public dataset at its disposal.
Active Learning for Efficient Testing of Student Programs
Apr 13, 2018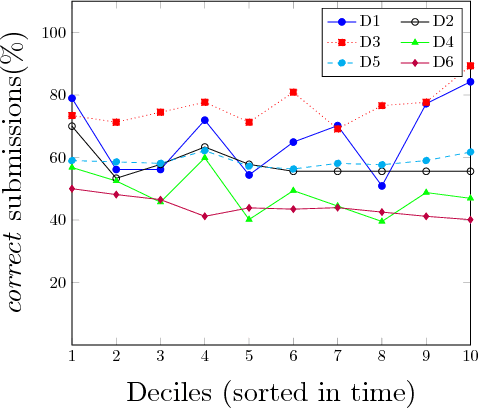
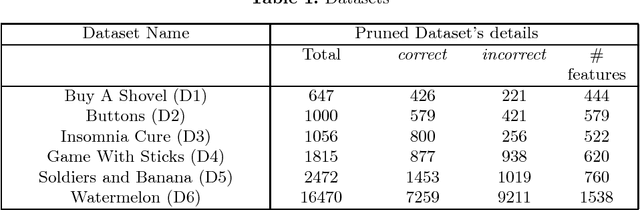
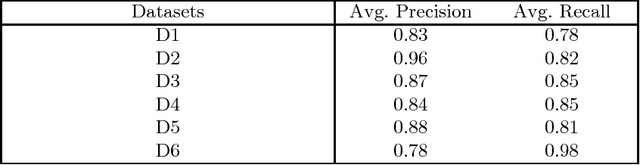

In this work, we propose an automated method to identify semantic bugs in student programs, called ATAS, which builds upon the recent advances in both symbolic execution and active learning. Symbolic execution is a program analysis technique which can generate test cases through symbolic constraint solving. Our method makes use of a reference implementation of the task as its sole input. We compare our method with a symbolic execution-based baseline on 6 programming tasks retrieved from CodeForces comprising a total of 23K student submissions. We show an average improvement of over 2.5x over the baseline in terms of runtime (thus making it more suitable for online evaluation), without a significant degradation in evaluation accuracy.
Deep Reinforcement Learning for Programming Language Correction
Jan 31, 2018

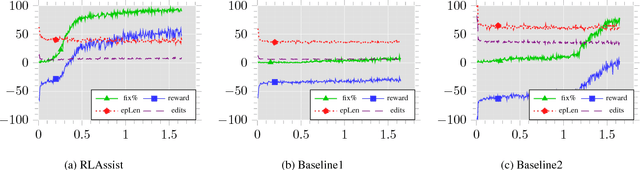

Novice programmers often struggle with the formal syntax of programming languages. To assist them, we design a novel programming language correction framework amenable to reinforcement learning. The framework allows an agent to mimic human actions for text navigation and editing. We demonstrate that the agent can be trained through self-exploration directly from the raw input, that is, program text itself, without any knowledge of the formal syntax of the programming language. We leverage expert demonstrations for one tenth of the training data to accelerate training. The proposed technique is evaluated on 6975 erroneous C programs with typographic errors, written by students during an introductory programming course. Our technique fixes 14% more programs and 29% more compiler error messages relative to those fixed by a state-of-the-art tool, DeepFix, which uses a fully supervised neural machine translation approach.
Learning Semantically Coherent and Reusable Kernels in Convolution Neural Nets for Sentence Classification
Oct 10, 2016
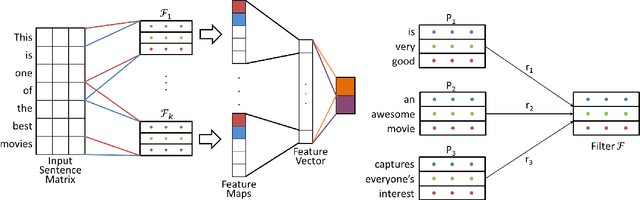
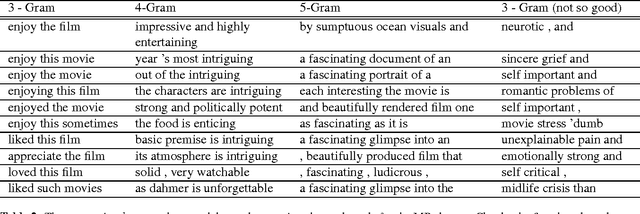

The state-of-the-art CNN models give good performance on sentence classification tasks. The purpose of this work is to empirically study desirable properties such as semantic coherence, attention mechanism and reusability of CNNs in these tasks. Semantically coherent kernels are preferable as they are a lot more interpretable for explaining the decision of the learned CNN model. We observe that the learned kernels do not have semantic coherence. Motivated by this observation, we propose to learn kernels with semantic coherence using clustering scheme combined with Word2Vec representation and domain knowledge such as SentiWordNet. We suggest a technique to visualize attention mechanism of CNNs for decision explanation purpose. Reusable property enables kernels learned on one problem to be used in another problem. This helps in efficient learning as only a few additional domain specific filters may have to be learned. We demonstrate the efficacy of our core ideas of learning semantically coherent kernels and leveraging reusable kernels for efficient learning on several benchmark datasets. Experimental results show the usefulness of our approach by achieving performance close to the state-of-the-art methods but with semantic and reusable properties.
Gaussian Process Pseudo-Likelihood Models for Sequence Labeling
Sep 21, 2016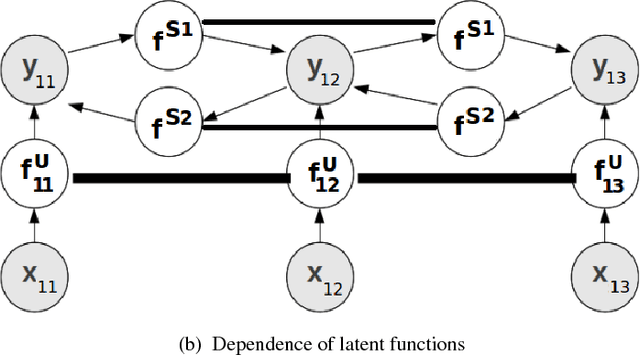
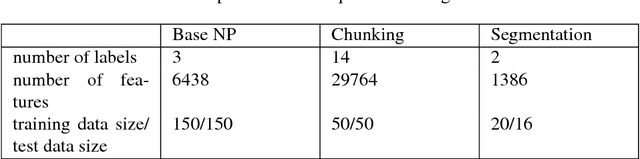
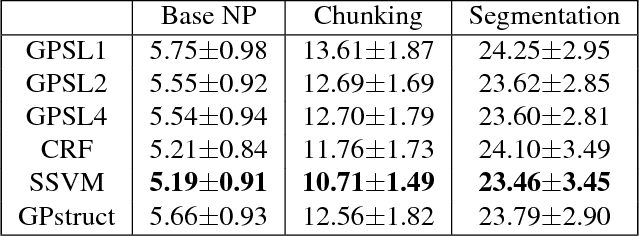
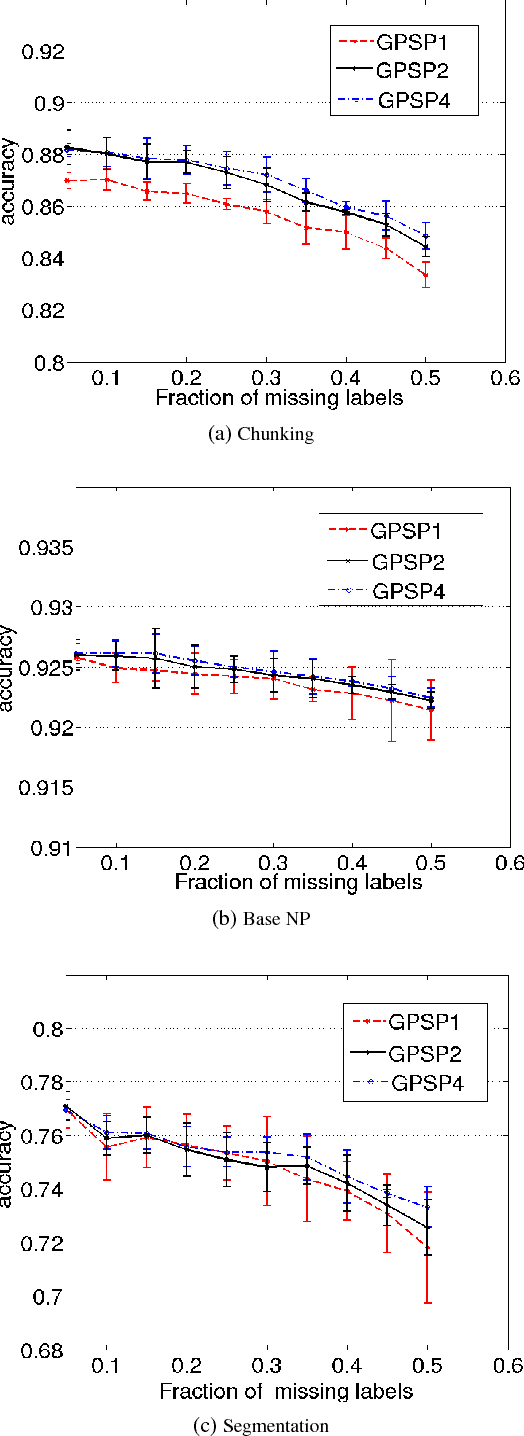
Several machine learning problems arising in natural language processing can be modeled as a sequence labeling problem. We provide Gaussian process models based on pseudo-likelihood approximation to perform sequence labeling. Gaussian processes (GPs) provide a Bayesian approach to learning in a kernel based framework. The pseudo-likelihood model enables one to capture long range dependencies among the output components of the sequence without becoming computationally intractable. We use an efficient variational Gaussian approximation method to perform inference in the proposed model. We also provide an iterative algorithm which can effectively make use of the information from the neighboring labels to perform prediction. The ability to capture long range dependencies makes the proposed approach useful for a wide range of sequence labeling problems. Numerical experiments on some sequence labeling data sets demonstrate the usefulness of the proposed approach.