 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStateful Detection of Model Extraction Attacks
Jul 12, 2021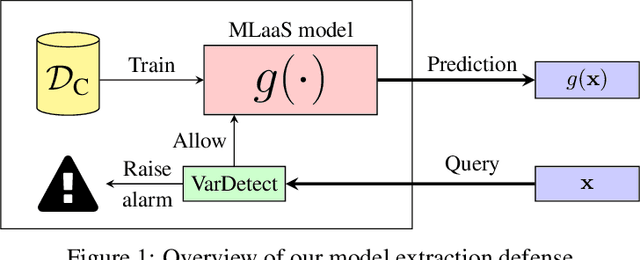
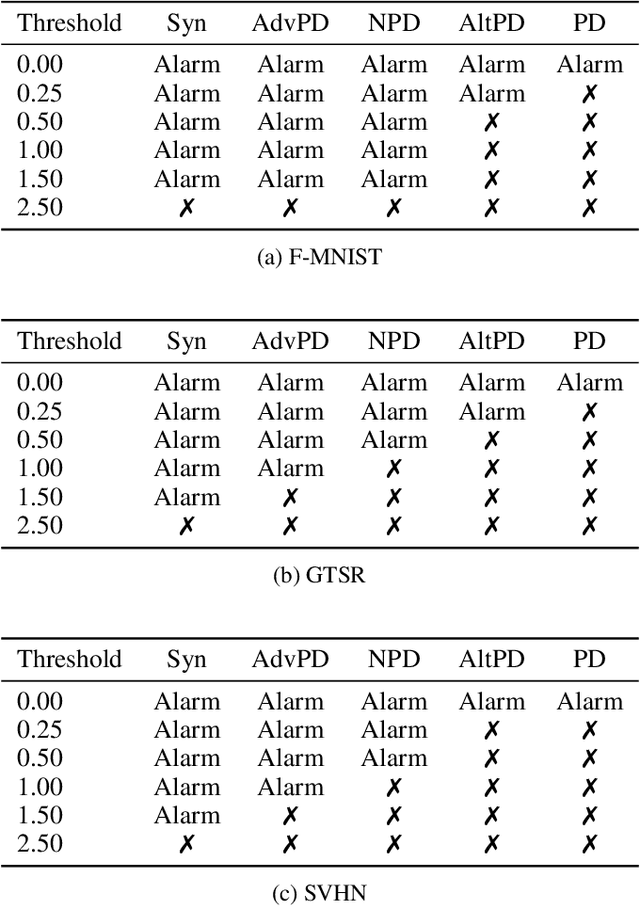

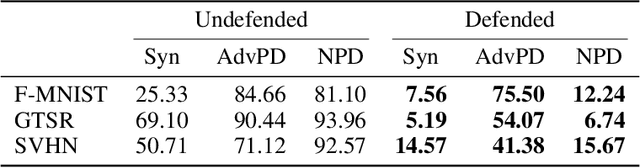
Machine-Learning-as-a-Service providers expose machine learning (ML) models through application programming interfaces (APIs) to developers. Recent work has shown that attackers can exploit these APIs to extract good approximations of such ML models, by querying them with samples of their choosing. We propose VarDetect, a stateful monitor that tracks the distribution of queries made by users of such a service, to detect model extraction attacks. Harnessing the latent distributions learned by a modified variational autoencoder, VarDetect robustly separates three types of attacker samples from benign samples, and successfully raises an alarm for each. Further, with VarDetect deployed as an automated defense mechanism, the extracted substitute models are found to exhibit poor performance and transferability, as intended. Finally, we demonstrate that even adaptive attackers with prior knowledge of the deployment of VarDetect, are detected by it.
A framework for the extraction of Deep Neural Networks by leveraging public data
May 22, 2019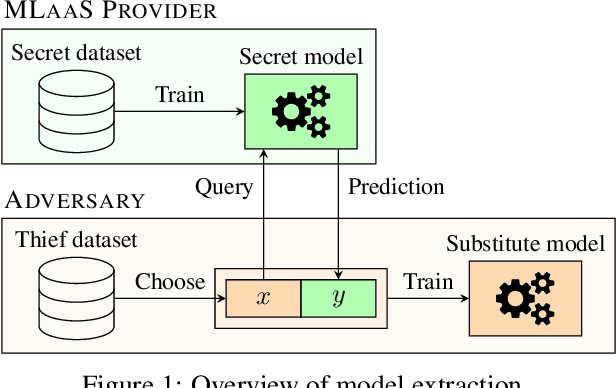


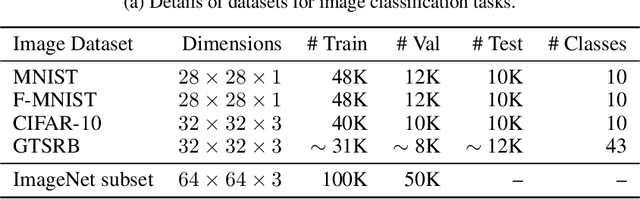
Machine learning models trained on confidential datasets are increasingly being deployed for profit. Machine Learning as a Service (MLaaS) has made such models easily accessible to end-users. Prior work has developed model extraction attacks, in which an adversary extracts an approximation of MLaaS models by making black-box queries to it. However, none of these works is able to satisfy all the three essential criteria for practical model extraction: (1) the ability to work on deep learning models, (2) the non-requirement of domain knowledge and (3) the ability to work with a limited query budget. We design a model extraction framework that makes use of active learning and large public datasets to satisfy them. We demonstrate that it is possible to use this framework to steal deep classifiers trained on a variety of datasets from image and text domains. By querying a model via black-box access for its top prediction, our framework improves performance on an average over a uniform noise baseline by 4.70x for image tasks and 2.11x for text tasks respectively, while using only 30% (30,000 samples) of the public dataset at its disposal.