 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking LLM Summaries of Multimodal Clinical Time Series for Remote Monitoring
Mar 02, 2026Large language models (LLMs) can generate fluent clinical summaries of remote therapeutic monitoring time series. However, it remains unclear whether these narratives faithfully capture clinically significant events, such as sustained abnormalities. Existing evaluation metrics primarily focus on semantic similarity and linguistic quality, leaving event-level correctness largely unmeasured. To address this gap, we introduce an event-based evaluation framework for multimodal time-series summarization using the Technology-Integrated Health Management (TIHM)-1.5 dementia monitoring dataset. Clinically grounded daily events are derived through rule-based abnormal thresholds and temporal persistence criteria. Model-generated summaries are then aligned with these structured facts. Our evaluation protocol measures abnormality recall, duration recall, measurement coverage, and hallucinated event mentions. We benchmark three approaches: zero-shot prompting, statistical prompting, and a vision-based pipeline that uses rendered time-series visualizations. The results reveal a striking decoupling between conventional metrics and clinical event fidelity. Models that achieve high semantic similarity scores often exhibit near-zero abnormality recall. In contrast, the vision-based approach demonstrates the strongest event alignment, achieving 45.7% abnormality recall and 100% duration recall. These findings underscore the importance of event-aware evaluation to ensure reliable clinical time-series summarization.
A framework for the extraction of Deep Neural Networks by leveraging public data
May 22, 2019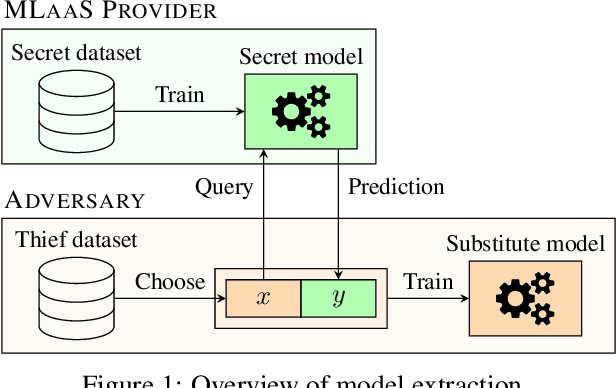


Machine learning models trained on confidential datasets are increasingly being deployed for profit. Machine Learning as a Service (MLaaS) has made such models easily accessible to end-users. Prior work has developed model extraction attacks, in which an adversary extracts an approximation of MLaaS models by making black-box queries to it. However, none of these works is able to satisfy all the three essential criteria for practical model extraction: (1) the ability to work on deep learning models, (2) the non-requirement of domain knowledge and (3) the ability to work with a limited query budget. We design a model extraction framework that makes use of active learning and large public datasets to satisfy them. We demonstrate that it is possible to use this framework to steal deep classifiers trained on a variety of datasets from image and text domains. By querying a model via black-box access for its top prediction, our framework improves performance on an average over a uniform noise baseline by 4.70x for image tasks and 2.11x for text tasks respectively, while using only 30% (30,000 samples) of the public dataset at its disposal.
A case for multiple and parallel RRAMs as synaptic model for training SNNs
Mar 13, 2018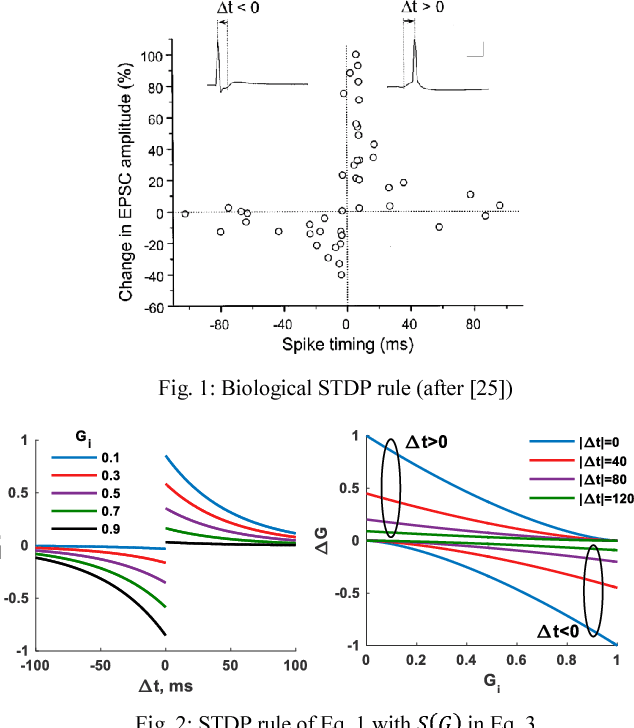
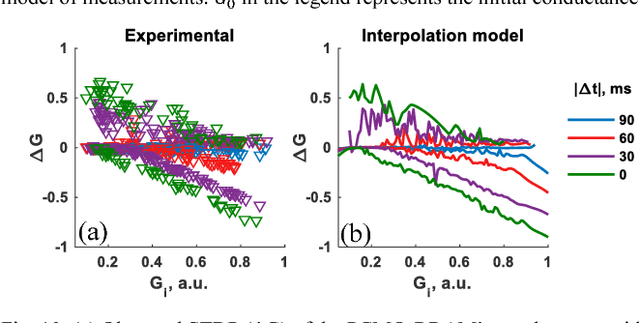
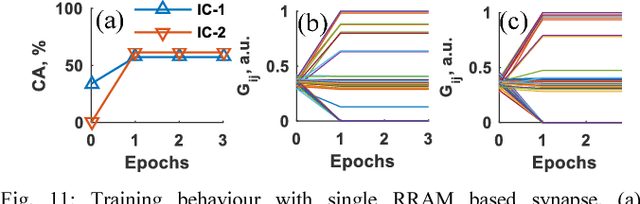
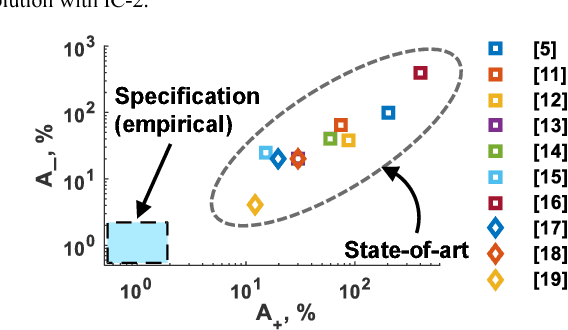
To enable a dense integration of model synapses in a spiking neural networks hardware, various nano-scale devices are being considered. Such a device, besides exhibiting spike-time dependent plasticity (STDP), needs to be highly scalable, have a large endurance and require low energy for transitioning between states. In this work, we first introduce and empirically determine two new specifications for an synapse in SNNs: number of conductance levels per synapse and maximum learning-rate. To the best of our knowledge, there are no RRAMs that meet the latter specification. As a solution, we propose the use of multiple PCMO-RRAMs in parallel within a synapse. While synaptic reading, all PCMO-RRAMs are simultaneously read and for each synaptic conductance-change event, the mechanism for conductance STDP is initiated for only one RRAM, randomly picked from the set. Second, to validate our solution, we experimentally demonstrate STDP of conductance of a PCMO-RRAM and then show that due to a large learning-rate, a single PCMO-RRAM fails to model a synapse in the training of an SNN. As anticipated, network training improves as more PCMO-RRAMs are added to the synapse. Fourth, we discuss the circuit-requirements for implementing such a scheme, to conclude that the requirements are within bounds. Thus, our work presents specifications for synaptic devices in trainable SNNs, indicates the shortcomings of state-of-art synaptic contenders, and provides a solution to extrinsically meet the specifications and discusses the peripheral circuitry that implements the solution.
An On-chip Trainable and Clock-less Spiking Neural Network with 1R Memristive Synapses
Nov 03, 2017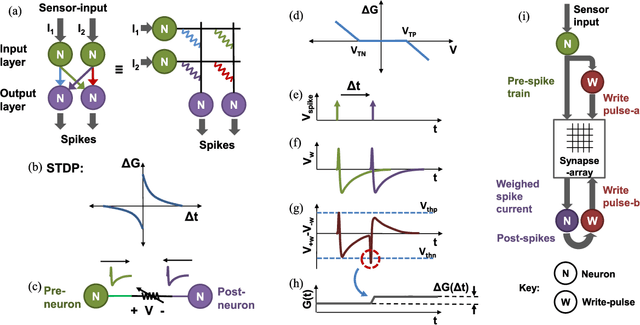
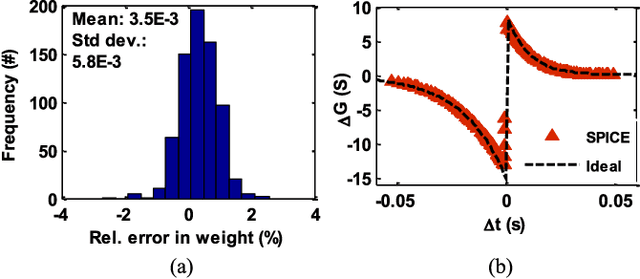
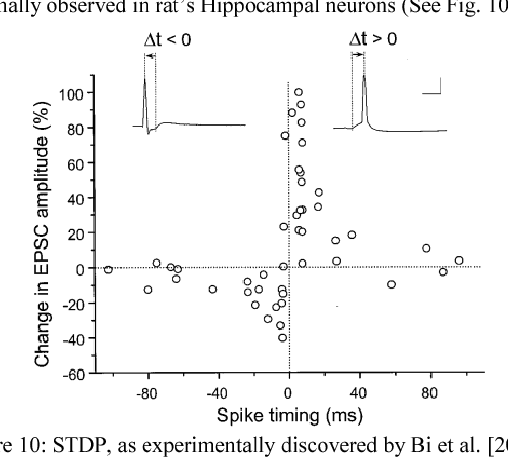
Spiking neural networks (SNNs) are being explored in an attempt to mimic brain's capability to learn and recognize at low power. Crossbar architecture with highly scalable Resistive RAM or RRAM array serving as synaptic weights and neuronal drivers in the periphery is an attractive option for SNN. Recognition (akin to reading the synaptic weight) requires small amplitude bias applied across the RRAM to minimize conductance change. Learning (akin to writing or updating the synaptic weight) requires large amplitude bias pulses to produce a conductance change. The contradictory bias amplitude requirement to perform reading and writing simultaneously and asynchronously, akin to biology, is a major challenge. Solutions suggested in the literature rely on time-division-multiplexing of read and write operations based on clocks, or approximations ignoring the reading when coincidental with writing. In this work, we overcome this challenge and present a clock-less approach wherein reading and writing are performed in different frequency domains. This enables learning and recognition simultaneously on an SNN. We validate our scheme in SPICE circuit simulator by translating a two-layered feed-forward Iris classifying SNN to demonstrate software-equivalent performance. The system performance is not adversely affected by a voltage dependence of conductance in realistic RRAMs, despite departing from linearity. Overall, our approach enables direct implementation of biological SNN algorithms in hardware.
A Software-equivalent SNN Hardware using RRAM-array for Asynchronous Real-time Learning
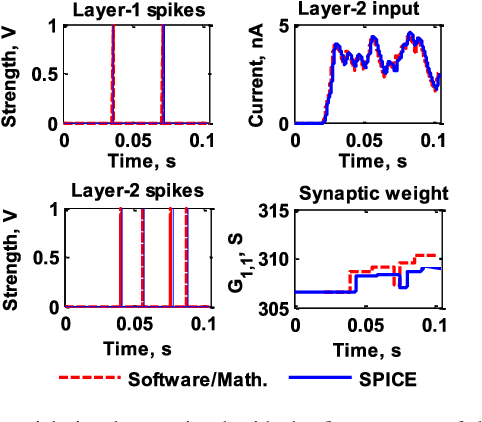
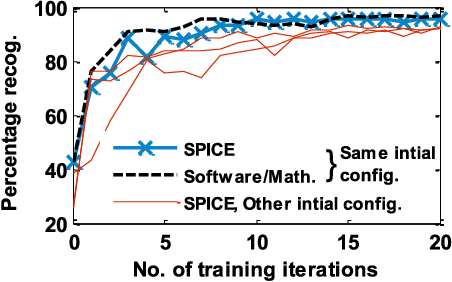
Apr 06, 2017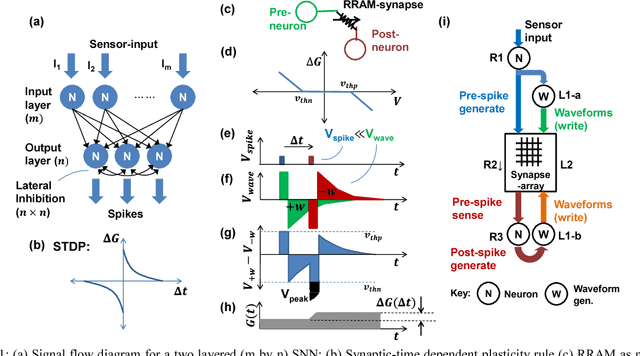
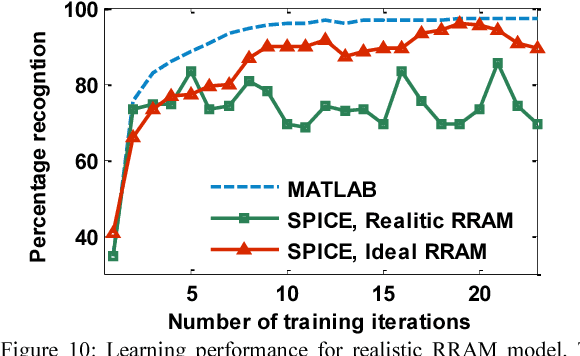
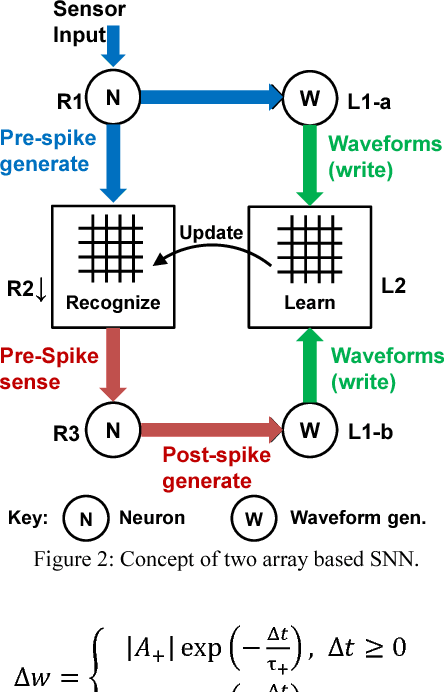
Spiking Neural Network (SNN) naturally inspires hardware implementation as it is based on biology. For learning, spike time dependent plasticity (STDP) may be implemented using an energy efficient waveform superposition on memristor based synapse. However, system level implementation has three challenges. First, a classic dilemma is that recognition requires current reading for short voltage$-$spikes which is disturbed by large voltage$-$waveforms that are simultaneously applied on the same memristor for real$-$time learning i.e. the simultaneous read$-$write dilemma. Second, the hardware needs to exactly replicate software implementation for easy adaptation of algorithm to hardware. Third, the devices used in hardware simulations must be realistic. In this paper, we present an approach to address the above concerns. First, the learning and recognition occurs in separate arrays simultaneously in real$-$time, asynchronously $-$ avoiding non$-$biomimetic clocking based complex signal management. Second, we show that the hardware emulates software at every stage by comparison of SPICE (circuit$-$simulator) with MATLAB (mathematical SNN algorithm implementation in software) implementations. As an example, the hardware shows 97.5 per cent accuracy in classification which is equivalent to software for a Fisher$-$Iris dataset. Third, the STDP is implemented using a model of synaptic device implemented using HfO2 memristor. We show that an increasingly realistic memristor model slightly reduces the hardware performance (85 per cent), which highlights the need to engineer RRAM characteristics specifically for SNN.