 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Platform to Evaluate STDP Learning Rule and Synapse Model using Pattern Recognition in a Spiking Neural Network
Jun 24, 2025We develop a unified platform to evaluate Ideal, Linear, and Non-linear $\text{Pr}_{0.7}\text{Ca}_{0.3}\text{MnO}_{3}$ memristor-based synapse models, each getting progressively closer to hardware realism, alongside four STDP learning rules in a two-layer SNN with LIF neurons and adaptive thresholds for five-class MNIST classification. On MNIST with small train set and large test set, our two-layer SNN with ideal, 25-state, and 12-state nonlinear memristor synapses achieves 92.73 %, 91.07 %, and 80 % accuracy, respectively, while converging faster and using fewer parameters than comparable ANN/CNN baselines.
A case for multiple and parallel RRAMs as synaptic model for training SNNs
Mar 13, 2018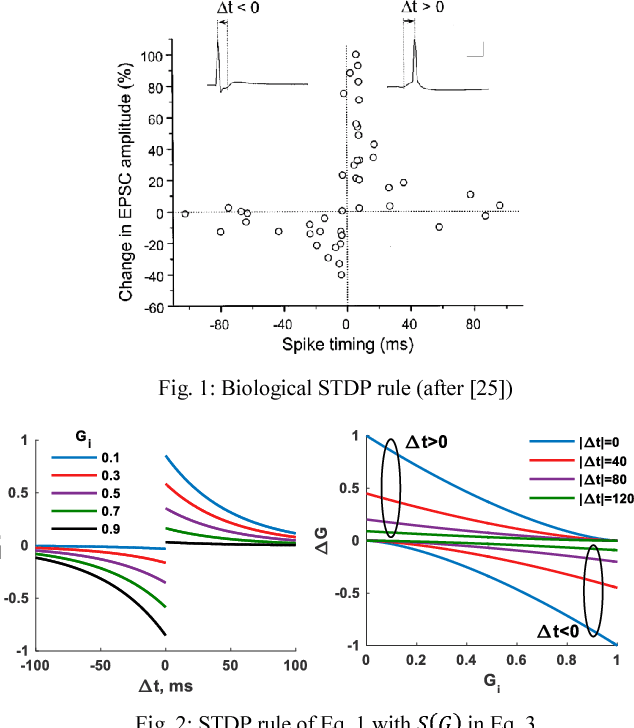
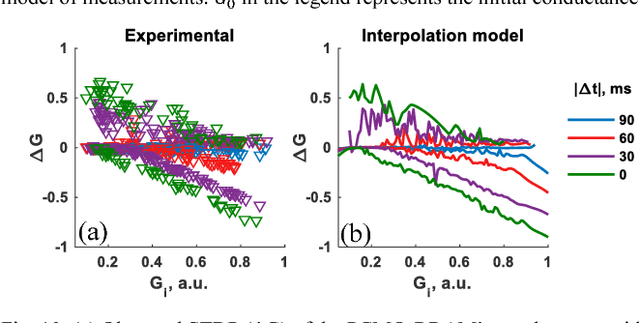
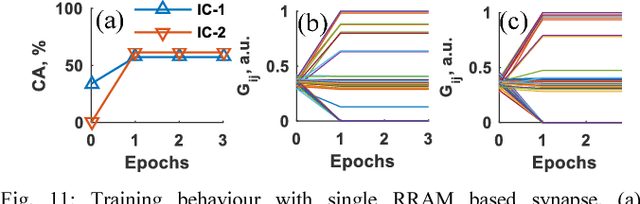
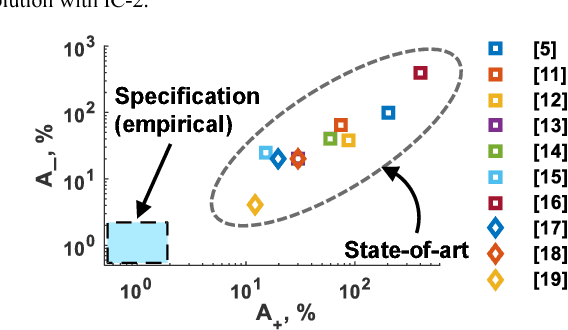
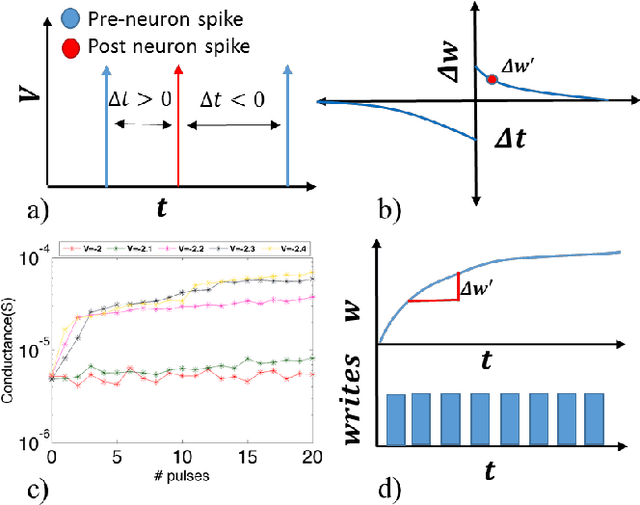
To enable a dense integration of model synapses in a spiking neural networks hardware, various nano-scale devices are being considered. Such a device, besides exhibiting spike-time dependent plasticity (STDP), needs to be highly scalable, have a large endurance and require low energy for transitioning between states. In this work, we first introduce and empirically determine two new specifications for an synapse in SNNs: number of conductance levels per synapse and maximum learning-rate. To the best of our knowledge, there are no RRAMs that meet the latter specification. As a solution, we propose the use of multiple PCMO-RRAMs in parallel within a synapse. While synaptic reading, all PCMO-RRAMs are simultaneously read and for each synaptic conductance-change event, the mechanism for conductance STDP is initiated for only one RRAM, randomly picked from the set. Second, to validate our solution, we experimentally demonstrate STDP of conductance of a PCMO-RRAM and then show that due to a large learning-rate, a single PCMO-RRAM fails to model a synapse in the training of an SNN. As anticipated, network training improves as more PCMO-RRAMs are added to the synapse. Fourth, we discuss the circuit-requirements for implementing such a scheme, to conclude that the requirements are within bounds. Thus, our work presents specifications for synaptic devices in trainable SNNs, indicates the shortcomings of state-of-art synaptic contenders, and provides a solution to extrinsically meet the specifications and discusses the peripheral circuitry that implements the solution.
A simple and efficient SNN and its performance & robustness evaluation method to enable hardware implementation
Dec 07, 2016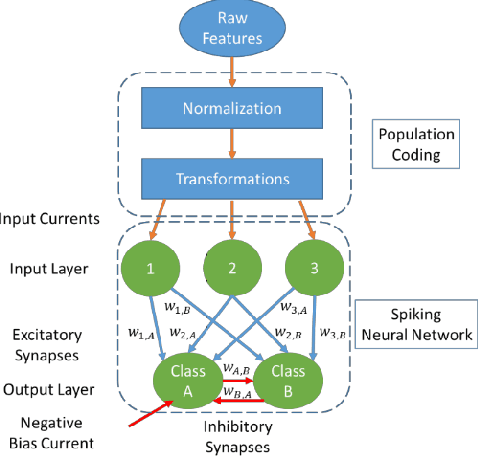
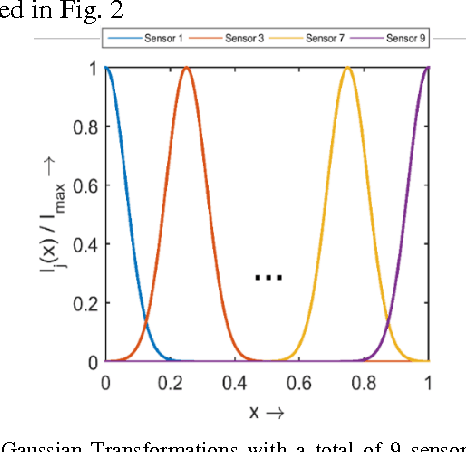

Spiking Neural Networks (SNN) are more closely related to brain-like computation and inspire hardware implementation. This is enabled by small networks that give high performance on standard classification problems. In literature, typical SNNs are deep and complex in terms of network structure, weight update rules and learning algorithms. This makes it difficult to translate them into hardware. In this paper, we first develop a simple 2-layered network in software which compares with the state of the art on four different standard data-sets within SNNs and has improved efficiency. For example, it uses lower number of neurons (3 x), synapses (3.5 x) and epochs for training (30 x) for the Fisher Iris classification problem. The efficient network is based on effective population coding and synapse-neuron co-design. Second, we develop a computationally efficient (15000 x) and accurate (correlation of 0.98) method to evaluate the performance of the network without standard recognition tests. Third, we show that the method produces a robustness metric that can be used to evaluate noise tolerance.