 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularization-based Framework for Quantization-, Fault- and Variability-Aware Training
Mar 05, 2025Efficient inference is critical for deploying deep learning models on edge AI devices. Low-bit quantization (e.g., 3- and 4-bit) with fixed-point arithmetic improves efficiency, while low-power memory technologies like analog nonvolatile memory enable further gains. However, these methods introduce non-ideal hardware behavior, including bit faults and device-to-device variability. We propose a regularization-based quantization-aware training (QAT) framework that supports fixed, learnable step-size, and learnable non-uniform quantization, achieving competitive results on CIFAR-10 and ImageNet. Our method also extends to Spiking Neural Networks (SNNs), demonstrating strong performance on 4-bit networks on CIFAR10-DVS and N-Caltech 101. Beyond quantization, our framework enables fault and variability-aware fine-tuning, mitigating stuck-at faults (fixed weight bits) and device resistance variability. Compared to prior fault-aware training, our approach significantly improves performance recovery under upto 20% bit-fault rate and 40% device-to-device variability. Our results establish a generalizable framework for quantization and robustness-aware training, enhancing efficiency and reliability in low-power, non-ideal hardware.
Temporal and Spatial Reservoir Ensembling Techniques for Liquid State Machines
Nov 18, 2024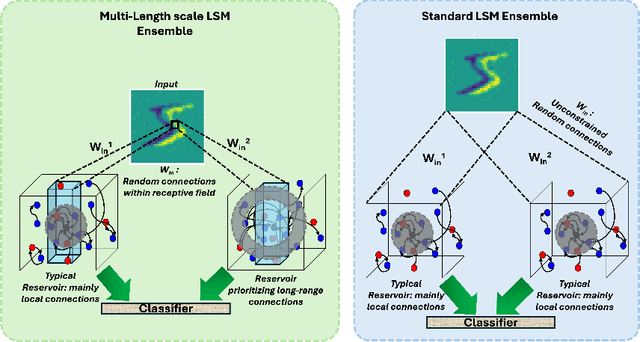
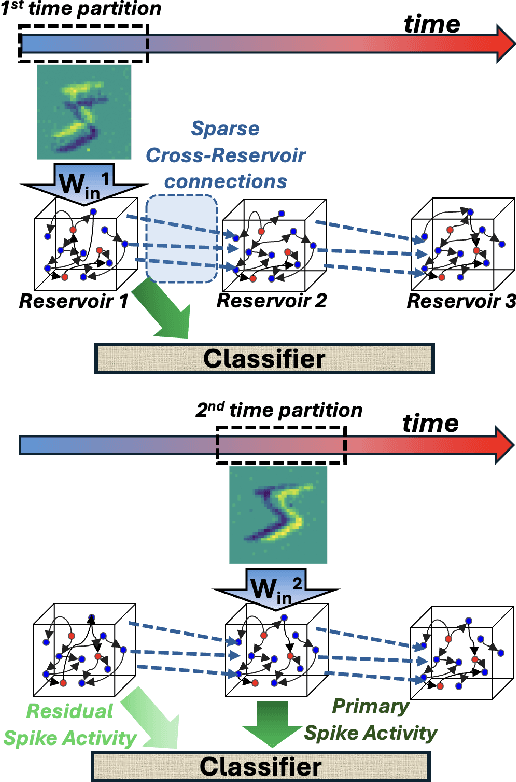
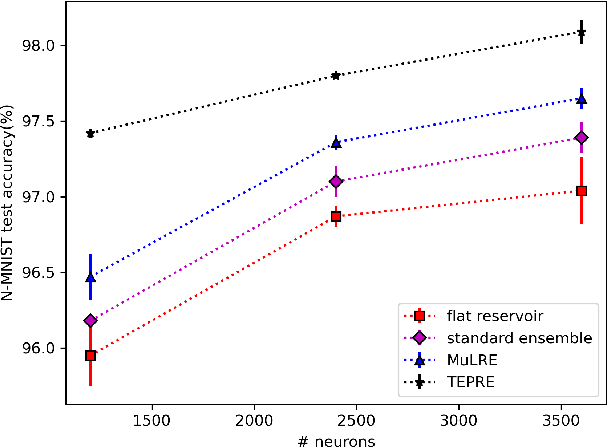
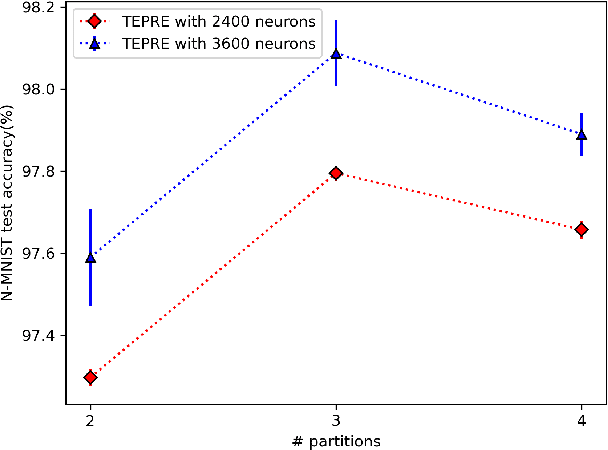
Reservoir computing (RC), is a class of computational methods such as Echo State Networks (ESN) and Liquid State Machines (LSM) describe a generic method to perform pattern recognition and temporal analysis with any non-linear system. This is enabled by Reservoir Computing being a shallow network model with only Input, Reservoir, and Readout layers where input and reservoir weights are not learned (only the readout layer is trained). LSM is a special case of Reservoir computing inspired by the organization of neurons in the brain and generally refers to spike-based Reservoir computing approaches. LSMs have been successfully used to showcase decent performance on some neuromorphic vision and speech datasets but a common problem associated with LSMs is that since the model is more-or-less fixed, the main way to improve the performance is by scaling up the Reservoir size, but that only gives diminishing rewards despite a tremendous increase in model size and computation. In this paper, we propose two approaches for effectively ensembling LSM models - Multi-Length Scale Reservoir Ensemble (MuLRE) and Temporal Excitation Partitioned Reservoir Ensemble (TEPRE) and benchmark them on Neuromorphic-MNIST (N-MNIST), Spiking Heidelberg Digits (SHD), and DVSGesture datasets, which are standard neuromorphic benchmarks. We achieve 98.1% test accuracy on N-MNIST with a 3600-neuron LSM model which is higher than any prior LSM-based approach and 77.8% test accuracy on the SHD dataset which is on par with a standard Recurrent Spiking Neural Network trained by Backprop Through Time (BPTT). We also propose receptive field-based input weights to the Reservoir to work alongside the Multi-Length Scale Reservoir ensemble model for vision tasks. Thus, we introduce effective means of scaling up the performance of LSM models and evaluate them against relevant neuromorphic benchmarks
A Temporally and Spatially Local Spike-based Backpropagation Algorithm to Enable Training in Hardware
Jul 20, 2022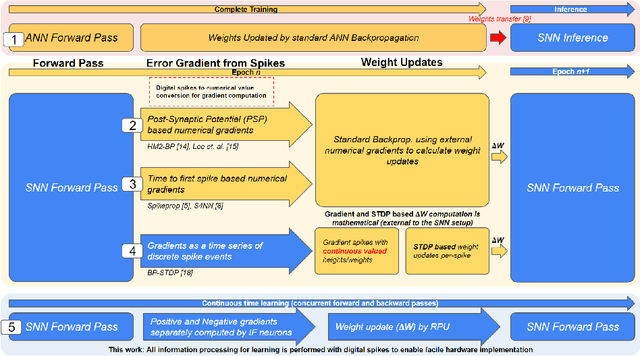
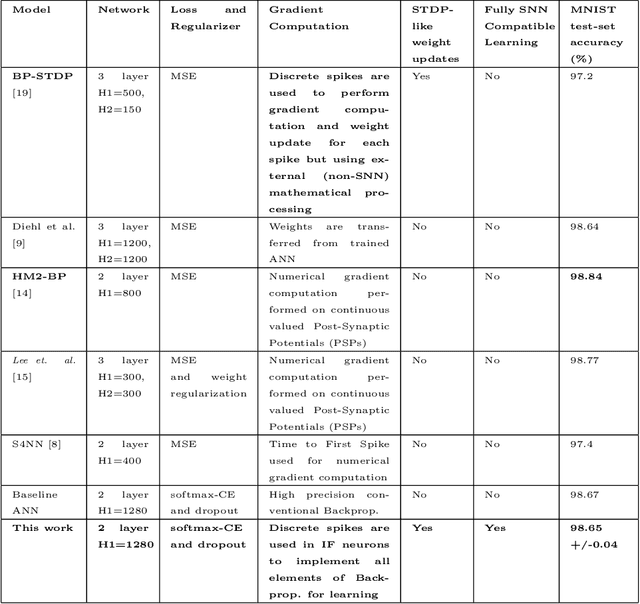
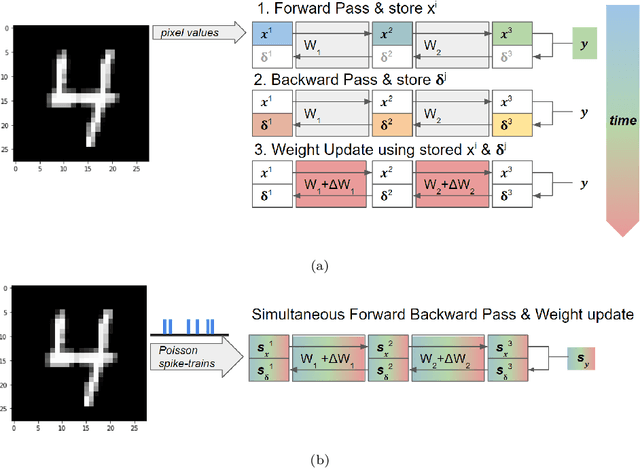
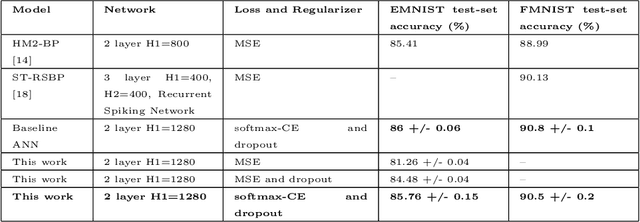
Spiking Neural Networks (SNNs) have emerged as a hardware efficient architecture for classification tasks. The penalty of spikes-based encoding has been the lack of a universal training mechanism performed entirely using spikes. There have been several attempts to adopt the powerful backpropagation (BP) technique used in non-spiking artificial neural networks (ANN): (1) SNNs can be trained by externally computed numerical gradients. (2) A major advancement toward native spike-based learning has been the use of approximate Backpropagation using spike-time-dependent plasticity (STDP) with phased forward/backward passes. However, the transfer of information between such phases necessitates external memory and computational access. This is a challenge for neuromorphic hardware implementations. In this paper, we propose a stochastic SNN-based Back-Prop (SSNN-BP) algorithm that utilizes a composite neuron to simultaneously compute the forward pass activations and backward pass gradients explicitly with spikes. Although signed gradient values are a challenge for spike-based representation, we tackle this by splitting the gradient signal into positive and negative streams. The composite neuron encodes information in the form of stochastic spike-trains and converts Backpropagation weight updates into temporally and spatially local discrete STDP-like spike coincidence updates compatible with hardware-friendly Resistive Processing Units (RPUs). Furthermore, our method approaches BP ANN baseline with sufficiently long spike-trains. Finally, we show that softmax cross-entropy loss function can be implemented through inhibitory lateral connections enforcing a Winner Take All (WTA) rule. Our SNN shows excellent generalization through comparable performance to ANNs on the MNIST, Fashion-MNIST and Extended MNIST datasets. Thus, SSNN-BP enables BP compatible with purely spike-based neuromorphic hardware.
A simple and efficient SNN and its performance & robustness evaluation method to enable hardware implementation
Dec 07, 2016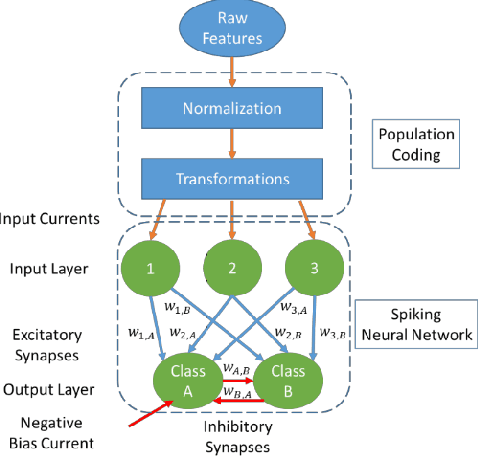
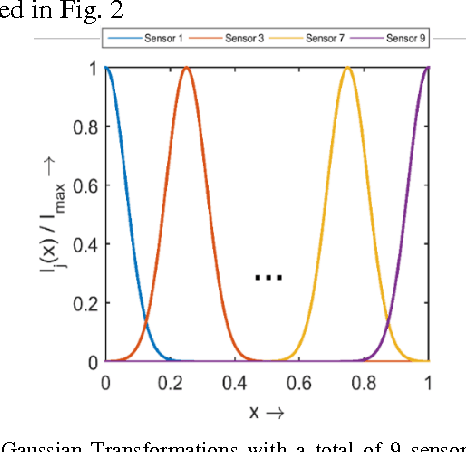

Spiking Neural Networks (SNN) are more closely related to brain-like computation and inspire hardware implementation. This is enabled by small networks that give high performance on standard classification problems. In literature, typical SNNs are deep and complex in terms of network structure, weight update rules and learning algorithms. This makes it difficult to translate them into hardware. In this paper, we first develop a simple 2-layered network in software which compares with the state of the art on four different standard data-sets within SNNs and has improved efficiency. For example, it uses lower number of neurons (3 x), synapses (3.5 x) and epochs for training (30 x) for the Fisher Iris classification problem. The efficient network is based on effective population coding and synapse-neuron co-design. Second, we develop a computationally efficient (15000 x) and accurate (correlation of 0.98) method to evaluate the performance of the network without standard recognition tests. Third, we show that the method produces a robustness metric that can be used to evaluate noise tolerance.