 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Ideal Program-Time Conservation in Charge Trap Flash for Deep Learning
Jul 12, 2023Training deep neural networks (DNNs) is computationally intensive but arrays of non-volatile memories like Charge Trap Flash (CTF) can accelerate DNN operations using in-memory computing. Specifically, the Resistive Processing Unit (RPU) architecture uses the voltage-threshold program by stochastic encoded pulse trains and analog memory features to accelerate vector-vector outer product and weight update for the gradient descent algorithms. Although CTF, offering high precision, has been regarded as an excellent choice for implementing RPU, the accumulation of charge due to the applied stochastic pulse trains is ultimately of critical significance in determining the final weight update. In this paper, we report the non-ideal program-time conservation in CTF through pulsing input measurements. We experimentally measure the effect of pulse width and pulse gap, keeping the total ON-time of the input pulse train constant, and report three non-idealities: (1) Cumulative V_T shift reduces when total ON-time is fragmented into a larger number of shorter pulses, (2) Cumulative V_T shift drops abruptly for pulse widths < 2 {\mu}s, (3) Cumulative V_T shift depends on the gap between consecutive pulses and the V_T shift reduction gets recovered for smaller gaps. We present an explanation based on a transient tunneling field enhancement due to blocking oxide trap-charge dynamics to explain these non-idealities. Identifying and modeling the responsible mechanisms and predicting their system-level effects during learning is critical. This non-ideal accumulation is expected to affect algorithms and architectures relying on devices for implementing mathematically equivalent functions for in-memory computing-based acceleration.
A Temporally and Spatially Local Spike-based Backpropagation Algorithm to Enable Training in Hardware
Jul 20, 2022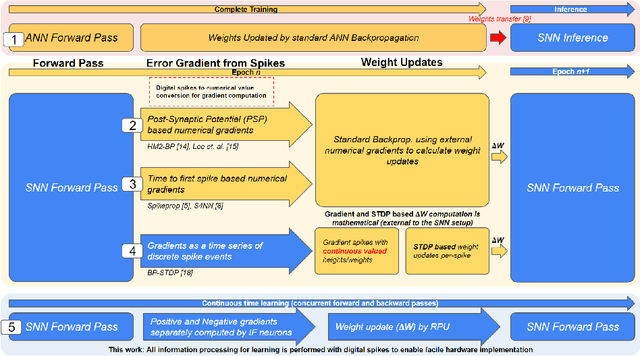
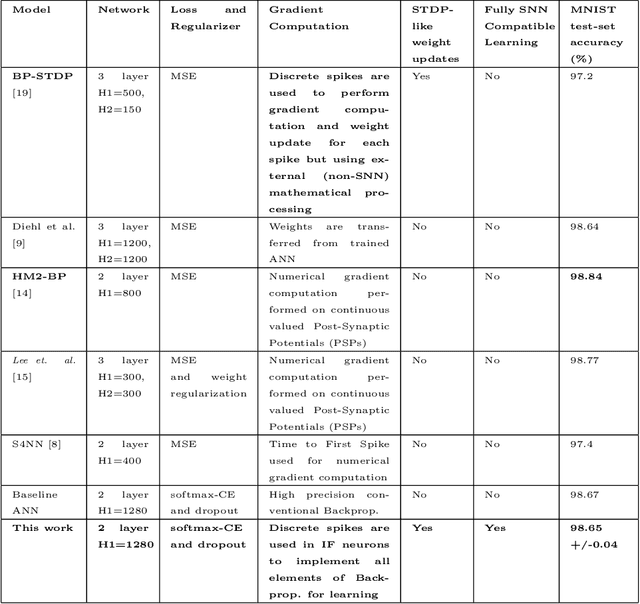
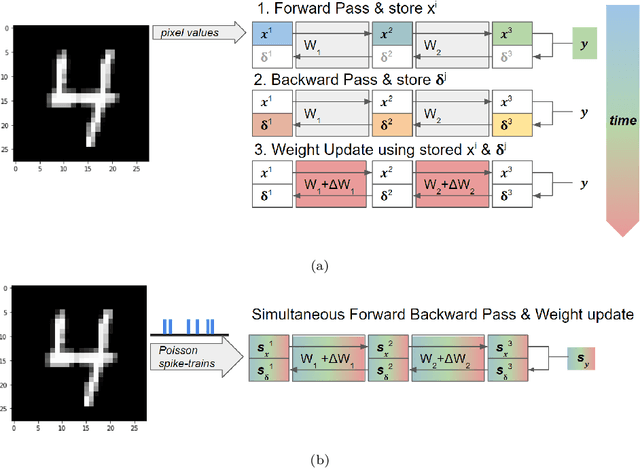
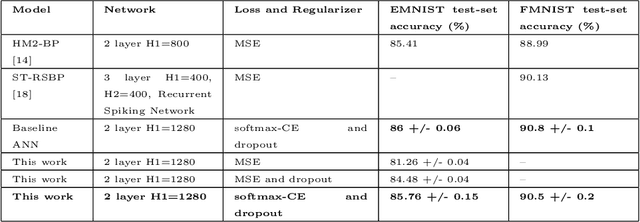
Spiking Neural Networks (SNNs) have emerged as a hardware efficient architecture for classification tasks. The penalty of spikes-based encoding has been the lack of a universal training mechanism performed entirely using spikes. There have been several attempts to adopt the powerful backpropagation (BP) technique used in non-spiking artificial neural networks (ANN): (1) SNNs can be trained by externally computed numerical gradients. (2) A major advancement toward native spike-based learning has been the use of approximate Backpropagation using spike-time-dependent plasticity (STDP) with phased forward/backward passes. However, the transfer of information between such phases necessitates external memory and computational access. This is a challenge for neuromorphic hardware implementations. In this paper, we propose a stochastic SNN-based Back-Prop (SSNN-BP) algorithm that utilizes a composite neuron to simultaneously compute the forward pass activations and backward pass gradients explicitly with spikes. Although signed gradient values are a challenge for spike-based representation, we tackle this by splitting the gradient signal into positive and negative streams. The composite neuron encodes information in the form of stochastic spike-trains and converts Backpropagation weight updates into temporally and spatially local discrete STDP-like spike coincidence updates compatible with hardware-friendly Resistive Processing Units (RPUs). Furthermore, our method approaches BP ANN baseline with sufficiently long spike-trains. Finally, we show that softmax cross-entropy loss function can be implemented through inhibitory lateral connections enforcing a Winner Take All (WTA) rule. Our SNN shows excellent generalization through comparable performance to ANNs on the MNIST, Fashion-MNIST and Extended MNIST datasets. Thus, SSNN-BP enables BP compatible with purely spike-based neuromorphic hardware.
Algorithm For 3D-Chemotaxis Using Spiking Neural Network
Jun 30, 2021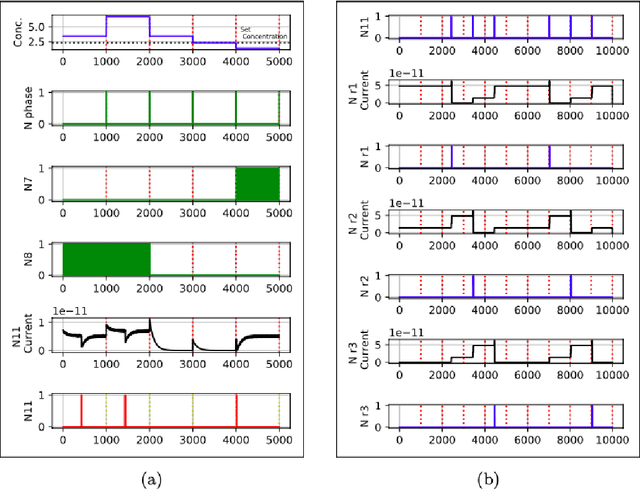
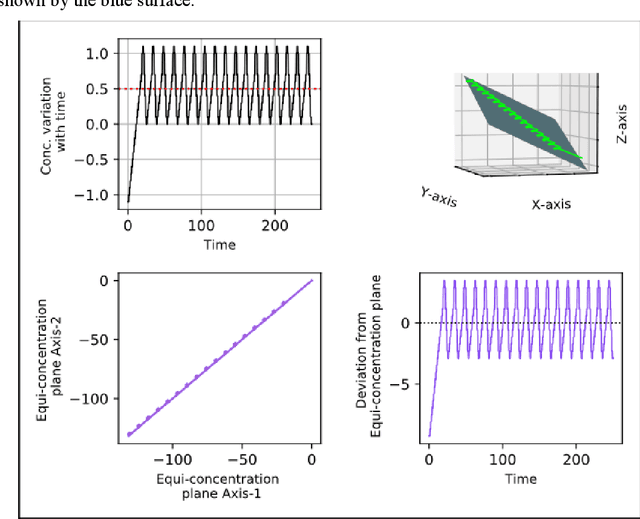
In this work, we aim to devise an end-to-end spiking implementation for contour tracking in 3D media inspired by chemotaxis, where the worm reaches the region which has the given set concentration. For a planer medium, efficient contour tracking algorithms have already been devised, but a new degree of freedom has quite a few challenges. Here we devise an algorithm based on klinokinesis - where the motion of the worm is in response to the stimuli but not proportional to it. Thus the path followed is not the shortest, but we can track the set concentration successfully. We are using simple LIF neurons for the neural network implementation, considering the feasibility of its implementation in the neuromorphic computing hardware.
Simplified Klinokinesis using Spiking Neural Networks for Resource-Constrained Navigation on the Neuromorphic Processor Loihi
May 04, 2021C. elegans shows chemotaxis using klinokinesis where the worm senses the concentration based on a single concentration sensor to compute the concentration gradient to perform foraging through gradient ascent/descent towards the target concentration followed by contour tracking. The biomimetic implementation requires complex neurons with multiple ion channel dynamics as well as interneurons for control. While this is a key capability of autonomous robots, its implementation on energy-efficient neuromorphic hardware like Intel's Loihi requires adaptation of the network to hardware-specific constraints, which has not been achieved. In this paper, we demonstrate the adaptation of chemotaxis based on klinokinesis to Loihi by implementing necessary neuronal dynamics with only LIF neurons as well as a complete spike-based implementation of all functions e.g. Heaviside function and subtractions. Our results show that Loihi implementation is equivalent to the software counterpart on Python in terms of performance - both during foraging and contour tracking. The Loihi results are also resilient in noisy environments. Thus, we demonstrate a successful adaptation of chemotaxis on Loihi - which can now be combined with the rich array of SNN blocks for SNN based complex robotic control.
Hardware-Friendly Synaptic Orders and Timescales in Liquid State Machines for Speech Classification
Apr 29, 2021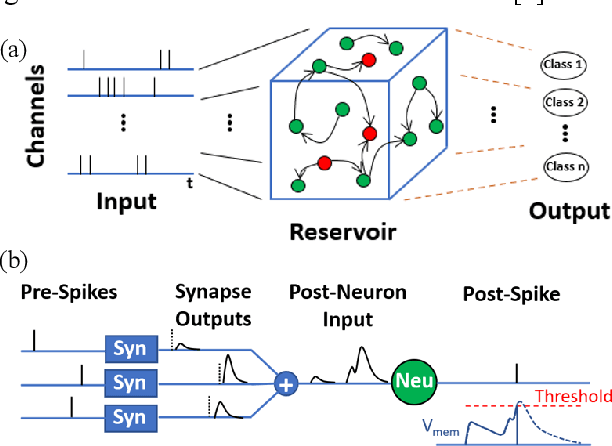
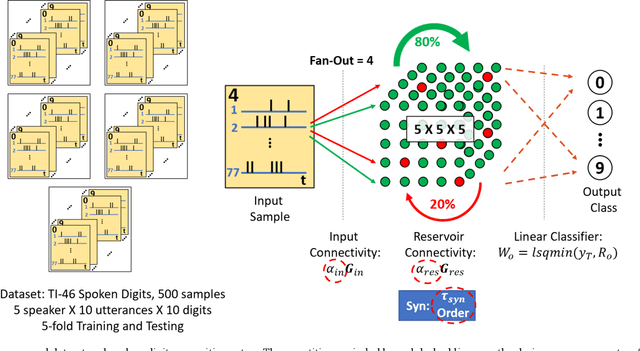
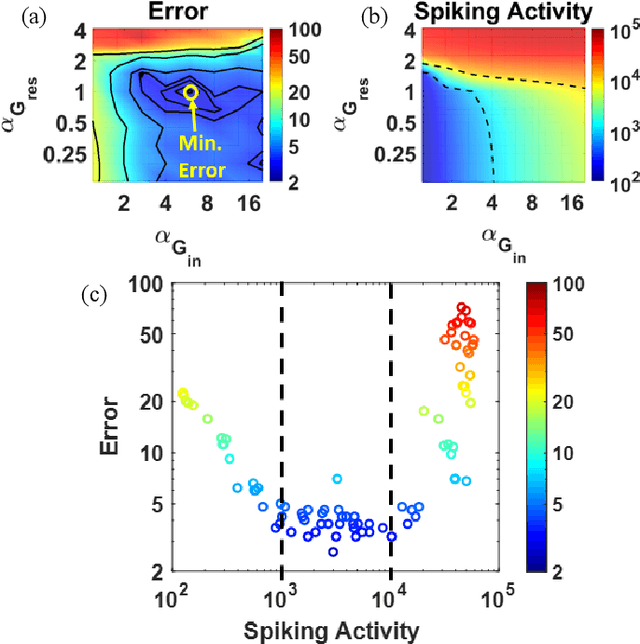
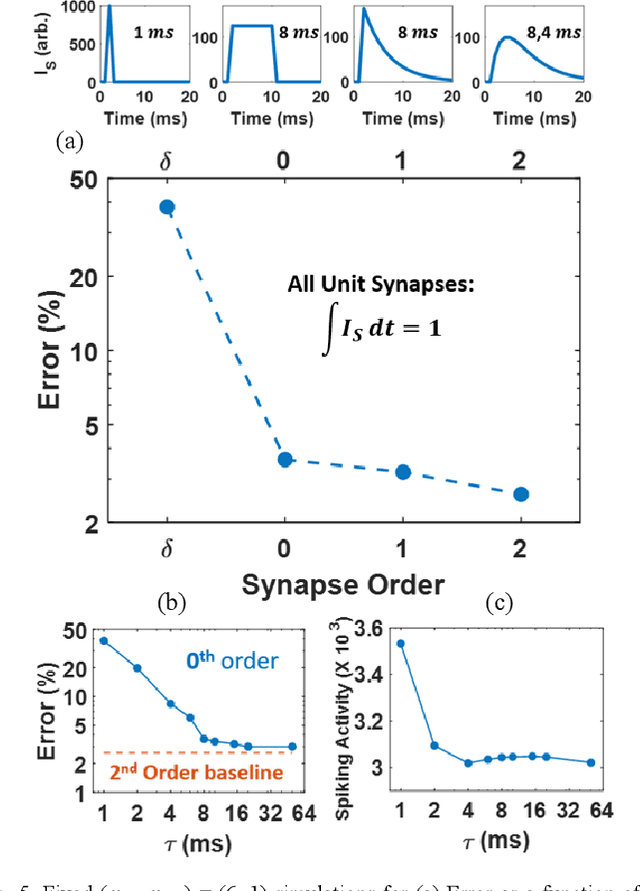
Liquid State Machines are brain inspired spiking neural networks (SNNs) with random reservoir connectivity and bio-mimetic neuronal and synaptic models. Reservoir computing networks are proposed as an alternative to deep neural networks to solve temporal classification problems. Previous studies suggest 2nd order (double exponential) synaptic waveform to be crucial for achieving high accuracy for TI-46 spoken digits recognition. The proposal of long-time range (ms) bio-mimetic synaptic waveforms is a challenge to compact and power efficient neuromorphic hardware. In this work, we analyze the role of synaptic orders namely: {\delta} (high output for single time step), 0th (rectangular with a finite pulse width), 1st (exponential fall) and 2nd order (exponential rise and fall) and synaptic timescales on the reservoir output response and on the TI-46 spoken digits classification accuracy under a more comprehensive parameter sweep. We find the optimal operating point to be correlated to an optimal range of spiking activity in the reservoir. Further, the proposed 0th order synapses perform at par with the biologically plausible 2nd order synapses. This is substantial relaxation for circuit designers as synapses are the most abundant components in an in-memory implementation for SNNs. The circuit benefits for both analog and mixed-signal realizations of 0th order synapse are highlighted demonstrating 2-3 orders of savings in area and power consumptions by eliminating Op-Amps and Digital to Analog Converter circuits. This has major implications on a complete neural network implementation with focus on peripheral limitations and algorithmic simplifications to overcome them.
Adaptive Chemotaxis for improved Contour Tracking using Spiking Neural Networks
Aug 01, 2020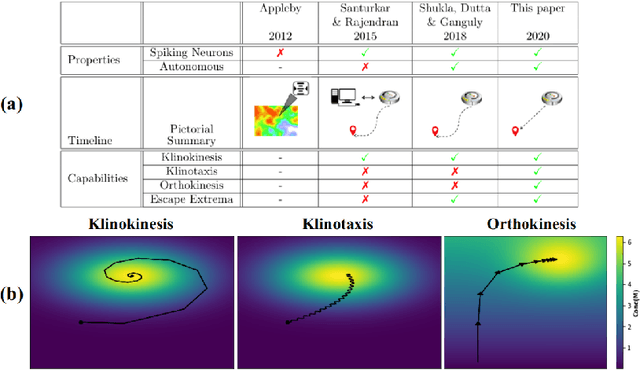
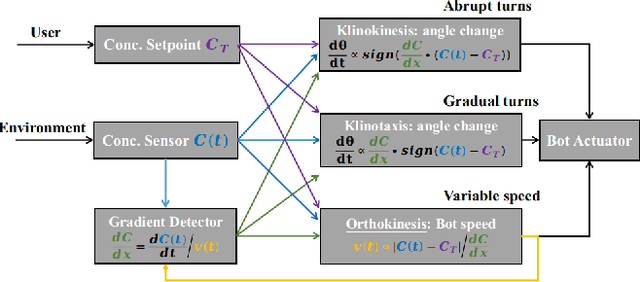
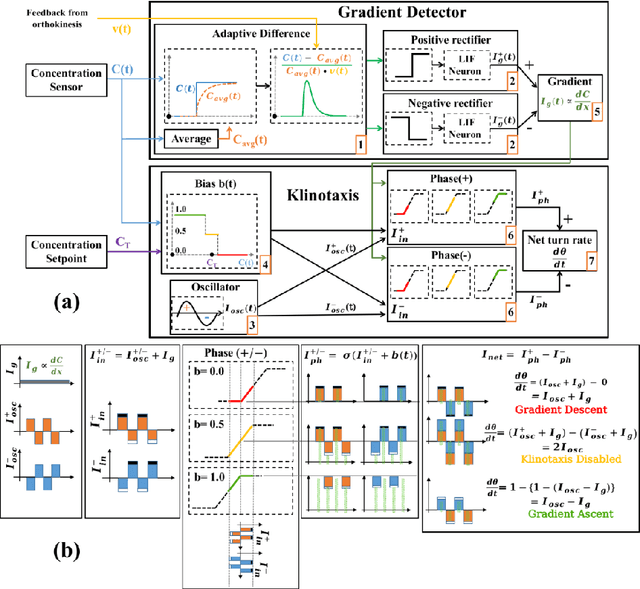
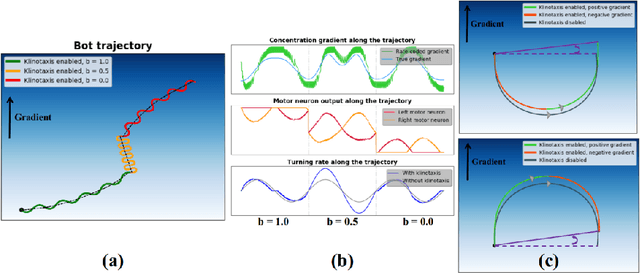
In this paper we present a Spiking Neural Network (SNN) for autonomous navigation, inspired by the chemotaxis network of the worm Caenorhabditis elegans. In particular, we focus on the problem of contour tracking, wherein the bot must reach and subsequently follow a desired concentration setpoint. Past schemes that used only klinokinesis can follow the contour efficiently but take excessive time to reach the setpoint. We address this shortcoming by proposing a novel adaptive klinotaxis mechanism that builds upon a previously proposed gradient climbing circuit. We demonstrate how our klinotaxis circuit can autonomously be configured to perform gradient ascent, gradient descent and subsequently be disabled to seamlessly integrate with the aforementioned klinokinesis circuit. We also incorporate speed regulation (orthokinesis) to further improve contour tracking performance. Thus for the first time, we present a model that successfully integrates klinokinesis, klinotaxis and orthokinesis. We demonstrate via contour tracking simulations that our proposed scheme achieves an 2.4x reduction in the time to reach the setpoint, along with a simultaneous 8.7x reduction in average deviation from the setpoint.
Predicting Performance using Approximate State Space Model for Liquid State Machines
Jan 18, 2019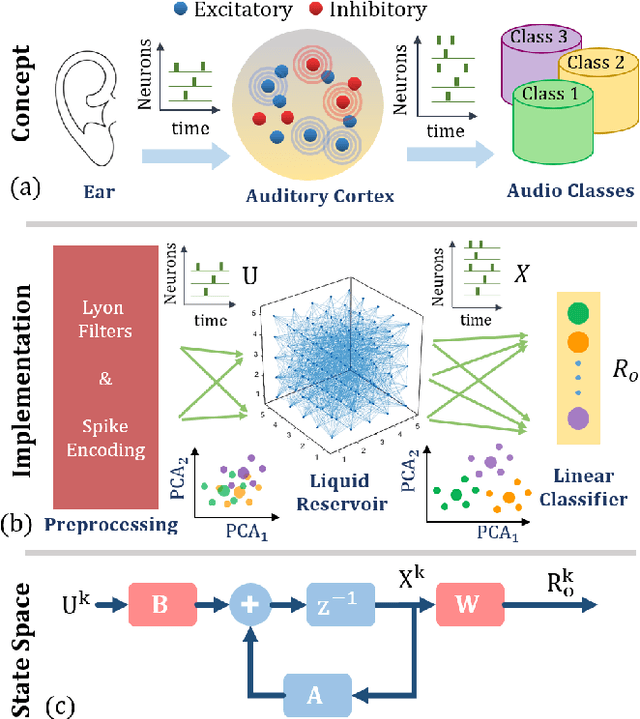
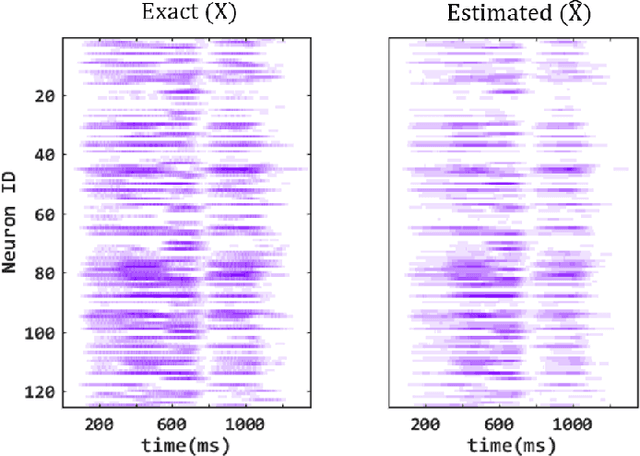

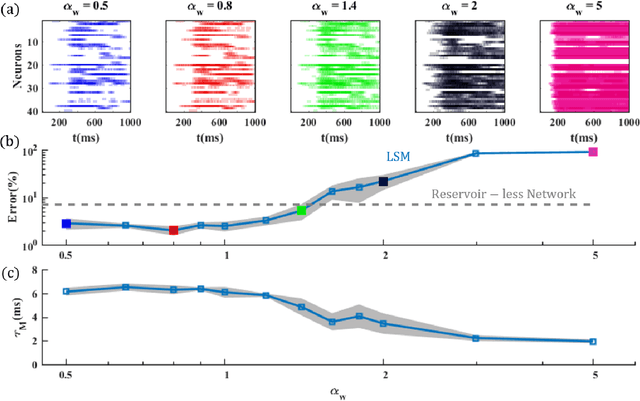
Liquid State Machine (LSM) is a brain-inspired architecture used for solving problems like speech recognition and time series prediction. LSM comprises of a randomly connected recurrent network of spiking neurons. This network propagates the non-linear neuronal and synaptic dynamics. Maass et al. have argued that the non-linear dynamics of LSMs is essential for its performance as a universal computer. Lyapunov exponent (mu), used to characterize the "non-linearity" of the network, correlates well with LSM performance. We propose a complementary approach of approximating the LSM dynamics with a linear state space representation. The spike rates from this model are well correlated to the spike rates from LSM. Such equivalence allows the extraction of a "memory" metric (tau_M) from the state transition matrix. tau_M displays high correlation with performance. Further, high tau_M system require lesser epochs to achieve a given accuracy. Being computationally cheap (1800x time efficient compared to LSM), the tau_M metric enables exploration of the vast parameter design space. We observe that the performance correlation of the tau_M surpasses the Lyapunov exponent (mu), (2-4x improvement) in the high-performance regime over multiple datasets. In fact, while mu increases monotonically with network activity, the performance reaches a maxima at a specific activity described in literature as the "edge of chaos". On the other hand, tau_M remains correlated with LSM performance even as mu increases monotonically. Hence, tau_M captures the useful memory of network activity that enables LSM performance. It also enables rapid design space exploration and fine-tuning of LSM parameters for high performance.