 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust deep learning for emulating turbulent viscosities
Oct 01, 2021
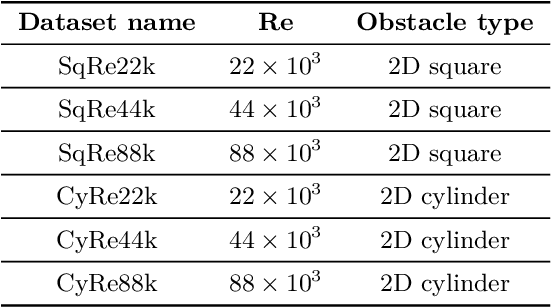


From the simplest models to complex deep neural networks, modeling turbulence with machine learning techniques still offers multiple challenges. In this context, the present contribution proposes a robust strategy using patch-based training to learn turbulent viscosity from flow velocities, and demonstrates its efficient use on the Spallart-Allmaras turbulence model. Training datasets are generated for flow past two-dimensional (2D) obstacles at high Reynolds numbers and used to train an auto-encoder type convolutional neural network with local patch inputs. Compared to a standard training technique, patch-based learning not only yields increased accuracy but also reduces the computational cost required for training.
Hardware-Friendly Synaptic Orders and Timescales in Liquid State Machines for Speech Classification
Apr 29, 2021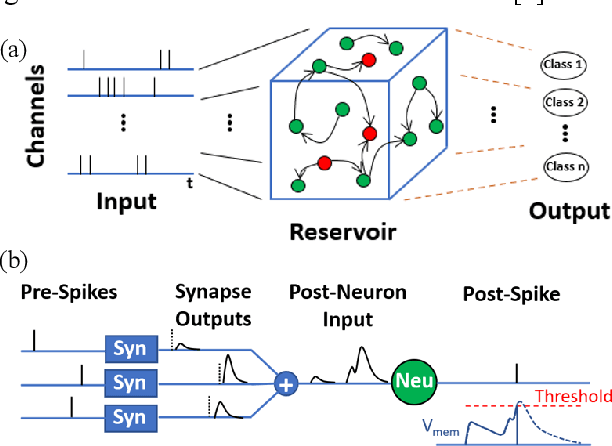
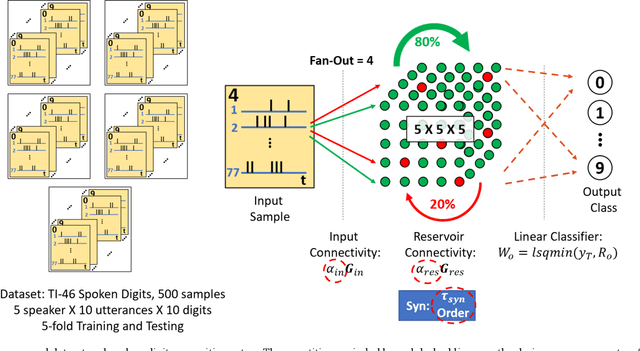
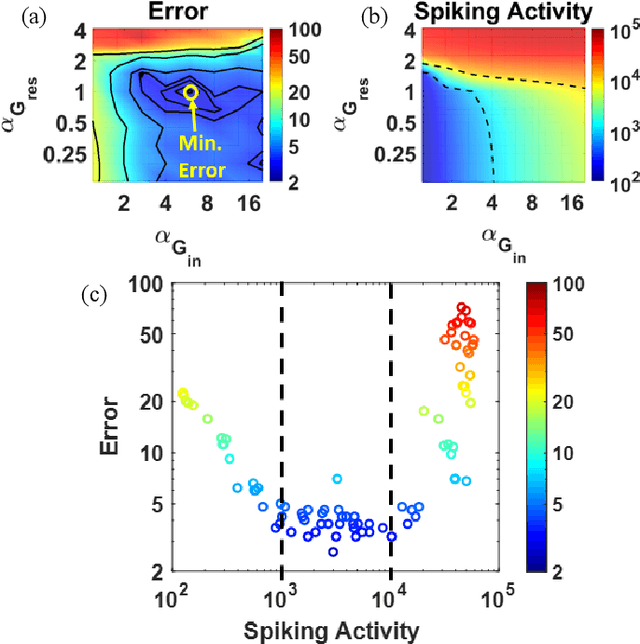
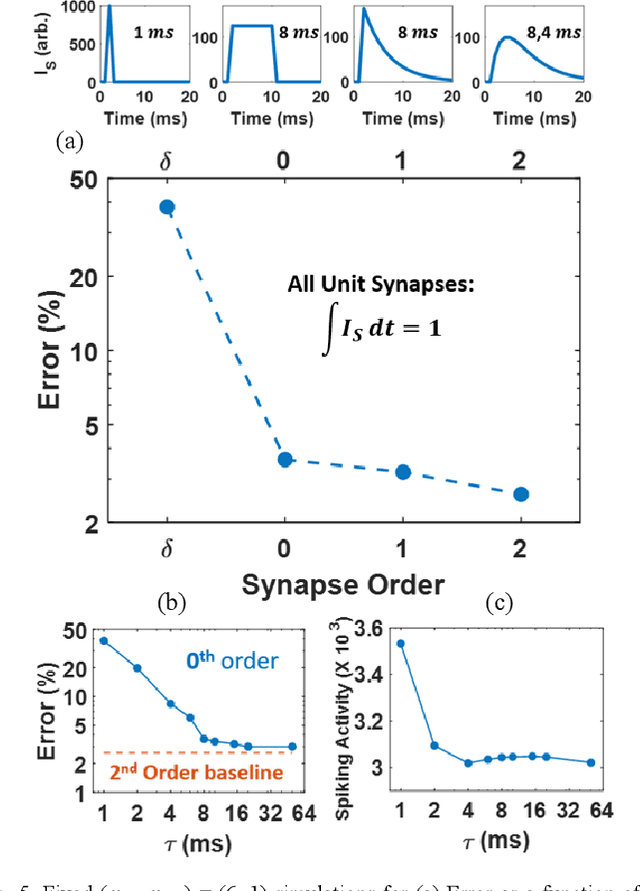
Liquid State Machines are brain inspired spiking neural networks (SNNs) with random reservoir connectivity and bio-mimetic neuronal and synaptic models. Reservoir computing networks are proposed as an alternative to deep neural networks to solve temporal classification problems. Previous studies suggest 2nd order (double exponential) synaptic waveform to be crucial for achieving high accuracy for TI-46 spoken digits recognition. The proposal of long-time range (ms) bio-mimetic synaptic waveforms is a challenge to compact and power efficient neuromorphic hardware. In this work, we analyze the role of synaptic orders namely: {\delta} (high output for single time step), 0th (rectangular with a finite pulse width), 1st (exponential fall) and 2nd order (exponential rise and fall) and synaptic timescales on the reservoir output response and on the TI-46 spoken digits classification accuracy under a more comprehensive parameter sweep. We find the optimal operating point to be correlated to an optimal range of spiking activity in the reservoir. Further, the proposed 0th order synapses perform at par with the biologically plausible 2nd order synapses. This is substantial relaxation for circuit designers as synapses are the most abundant components in an in-memory implementation for SNNs. The circuit benefits for both analog and mixed-signal realizations of 0th order synapse are highlighted demonstrating 2-3 orders of savings in area and power consumptions by eliminating Op-Amps and Digital to Analog Converter circuits. This has major implications on a complete neural network implementation with focus on peripheral limitations and algorithmic simplifications to overcome them.
ADEPOS: A Novel Approximate Computing Framework for Anomaly Detection Systems and its Implementation in 65nm CMOS
Dec 04, 2019
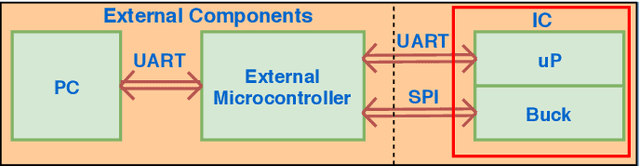
To overcome the energy and bandwidth limitations of traditional IoT systems, edge computing or information extraction at the sensor node has become popular. However, now it is important to create very low energy information extraction or pattern recognition systems. In this paper, we present an approximate computing method to reduce the computation energy of a specific type of IoT system used for anomaly detection (e.g. in predictive maintenance, epileptic seizure detection, etc). Termed as Anomaly Detection Based Power Savings (ADEPOS), our proposed method uses low precision computing and low complexity neural networks at the beginning when it is easy to distinguish healthy data. However, on the detection of anomalies, the complexity of the network and computing precision are adaptively increased for accurate predictions. We show that ensemble approaches are well suited for adaptively changing network size. To validate our proposed scheme, a chip has been fabricated in UMC65nm process that includes an MSP430 microprocessor along with an on-chip switching mode DC-DC converter for dynamic voltage and frequency scaling. Using NASA bearing dataset for machine health monitoring, we show that using ADEPOS we can achieve 8.95X saving of energy along the lifetime without losing any detection accuracy. The energy savings are obtained by reducing the execution time of the neural network on the microprocessor.
* 14 pages
Hardware Architecture for Large Parallel Array of Random Feature Extractors applied to Image Recognition
Dec 24, 2015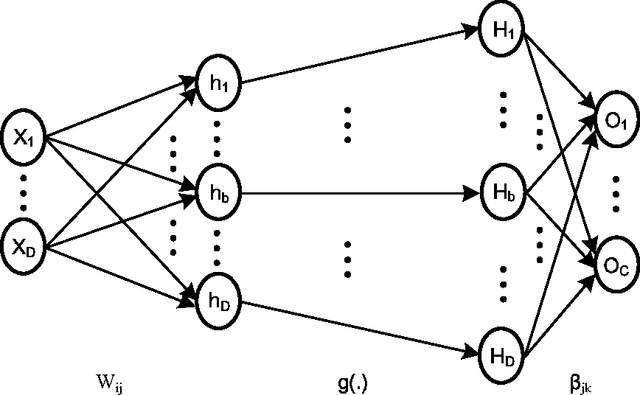

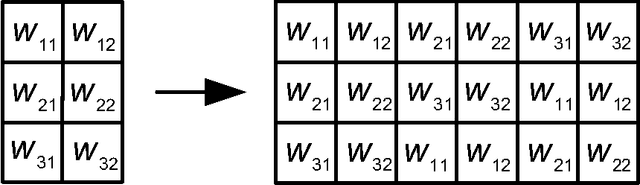

We demonstrate a low-power and compact hardware implementation of Random Feature Extractor (RFE) core. With complex tasks like Image Recognition requiring a large set of features, we show how weight reuse technique can allow to virtually expand the random features available from RFE core. Further, we show how to avoid computation cost wasted for propagating "incognizant" or redundant random features. For proof of concept, we validated our approach by using our RFE core as the first stage of Extreme Learning Machine (ELM)--a two layer neural network--and were able to achieve $>97\%$ accuracy on MNIST database of handwritten digits. ELM's first stage of RFE is done on an analog ASIC occupying $5$mm$\times5$mm area in $0.35\mu$m CMOS and consuming $5.95$ $\mu$J/classify while using $\approx 5000$ effective hidden neurons. The ELM second stage consisting of just adders can be implemented as digital circuit with estimated power consumption of $20.9$ nJ/classify. With a total energy consumption of only $5.97$ $\mu$J/classify, this low-power mixed signal ASIC can act as a co-processor in portable electronic gadgets with cameras.