 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-3DEdit: Generalized Versatile 3D Editing in One-Pass
Mar 18, 2026Most instruction-driven 3D editing methods rely on 2D models to guide the explicit and iterative optimization of 3D representations. This paradigm, however, suffers from two primary drawbacks. First, it lacks a universal design of different 3D editing tasks because the explicit manipulation of 3D geometry necessitates task-dependent rules, e.g., 3D appearance editing demands inherent source 3D geometry, while 3D removal alters source geometry. Second, the iterative optimization process is highly time-consuming, often requiring thousands of invocations of 2D/3D updating. We present Omni-3DEdit, a unified, learning-based model that generalizes various 3D editing tasks implicitly. One key challenge to achieve our goal is the scarcity of paired source-edited multi-view assets for training. To address this issue, we construct a data pipeline, synthesizing a relatively rich number of high-quality paired multi-view editing samples. Subsequently, we adapt the pre-trained generative model SEVA as our backbone by concatenating source view latents along with conditional tokens in sequence space. A dual-stream LoRA module is proposed to disentangle different view cues, largely enhancing our model's representational learning capability. As a learning-based model, our model is free of the time-consuming online optimization, and it can complete various 3D editing tasks in one forward pass, reducing the inference time from tens of minutes to approximately two minutes. Extensive experiments demonstrate the effectiveness and efficiency of Omni-3DEdit.
SA-EMO: Structure-Aligned Encoder Mixture of Operators for Generalizable Full-waveform Inversion
Nov 07, 2025Full-waveform inversion (FWI) can produce high-resolution subsurface models, yet it remains inherently ill-posed, highly nonlinear, and computationally intensive. Although recent deep learning and numerical acceleration methods have improved speed and scalability, they often rely on single CNN architectures or single neural operators, which struggle to generalize in unknown or complex geological settings and are ineffective at distinguishing diverse geological types. To address these issues, we propose a Structure-Aligned Encoder-Mixture-of-Operators (SA-EMO) architecture for velocity-field inversion under unknown subsurface structures. First, a structure-aligned encoder maps high-dimensional seismic wavefields into a physically consistent latent space, thereby eliminating spatio-temporal mismatch between the waveform and velocity domains, recovering high-frequency components, and enhancing feature generalization. Then, an adaptive routing mechanism selects and fuses multiple neural-operator experts, including spectral, wavelet, multiscale, and local operators, to predict the velocity model. We systematically evaluate our approach on the OpenFWI benchmark and the Marmousi2 dataset. Results show that SA-EMO significantly outperforms traditional CNN or single-operator methods, achieving an average MAE reduction of approximately 58.443% and an improvement in boundary resolution of about 10.308%. Ablation studies further reveal that the structure-aligned encoder, the expert-fusion mechanism, and the routing module each contribute markedly to the performance gains. This work introduces a new paradigm for efficient, scalable, and physically interpretable full-waveform inversion.
TacticExpert: Spatial-Temporal Graph Language Model for Basketball Tactics
Mar 13, 2025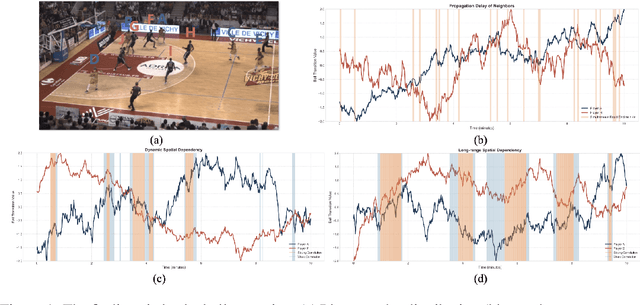
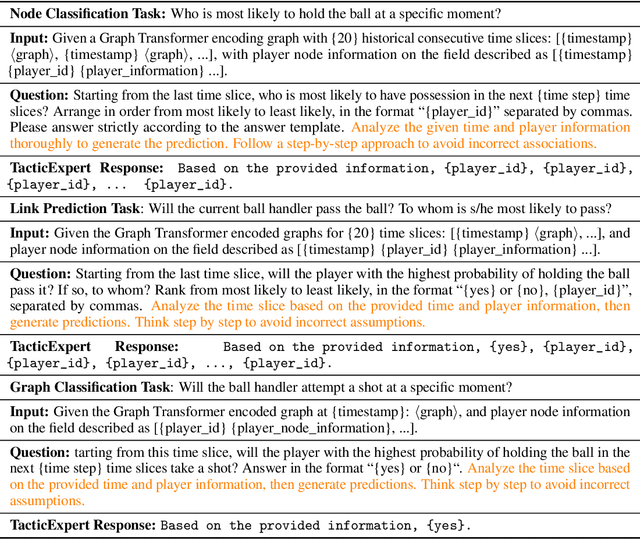
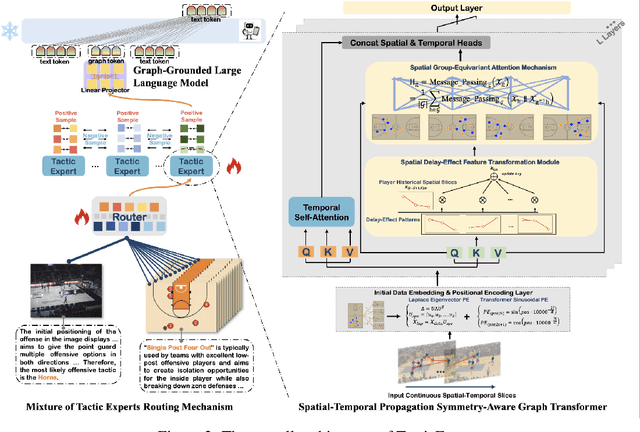
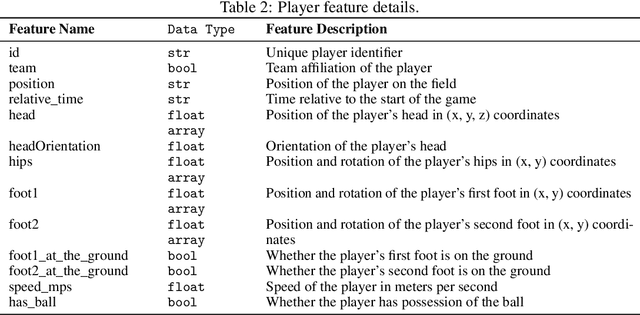
The core challenge in basketball tactic modeling lies in efficiently extracting complex spatial-temporal dependencies from historical data and accurately predicting various in-game events. Existing state-of-the-art (SOTA) models, primarily based on graph neural networks (GNNs), encounter difficulties in capturing long-term, long-distance, and fine-grained interactions among heterogeneous player nodes, as well as in recognizing interaction patterns. Additionally, they exhibit limited generalization to untrained downstream tasks and zero-shot scenarios. In this work, we propose a Spatial-Temporal Propagation Symmetry-Aware Graph Transformer for fine-grained game modeling. This architecture explicitly captures delay effects in the spatial space to enhance player node representations across discrete-time slices, employing symmetry-invariant priors to guide the attention mechanism. We also introduce an efficient contrastive learning strategy to train a Mixture of Tactics Experts module, facilitating differentiated modeling of offensive tactics. By integrating dense training with sparse inference, we achieve a 2.4x improvement in model efficiency. Moreover, the incorporation of Lightweight Graph Grounding for Large Language Models enables robust performance in open-ended downstream tasks and zero-shot scenarios, including novel teams or players. The proposed model, TacticExpert, delineates a vertically integrated large model framework for basketball, unifying pretraining across multiple datasets and downstream prediction tasks. Fine-grained modeling modules significantly enhance spatial-temporal representations, and visualization analyzes confirm the strong interpretability of the model.
EAUWSeg: Eliminating annotation uncertainty in weakly-supervised medical image segmentation
Jan 03, 2025



Weakly-supervised medical image segmentation is gaining traction as it requires only rough annotations rather than accurate pixel-to-pixel labels, thereby reducing the workload for specialists. Although some progress has been made, there is still a considerable performance gap between the label-efficient methods and fully-supervised one, which can be attributed to the uncertainty nature of these weak labels. To address this issue, we propose a novel weak annotation method coupled with its learning framework EAUWSeg to eliminate the annotation uncertainty. Specifically, we first propose the Bounded Polygon Annotation (BPAnno) by simply labeling two polygons for a lesion. Then, the tailored learning mechanism that explicitly treat bounded polygons as two separated annotations is proposed to learn invariant feature by providing adversarial supervision signal for model training. Subsequently, a confidence-auxiliary consistency learner incorporates with a classification-guided confidence generator is designed to provide reliable supervision signal for pixels in uncertain region by leveraging the feature presentation consistency across pixels within the same category as well as class-specific information encapsulated in bounded polygons annotation. Experimental results demonstrate that EAUWSeg outperforms existing weakly-supervised segmentation methods. Furthermore, compared to fully-supervised counterparts, the proposed method not only delivers superior performance but also costs much less annotation workload. This underscores the superiority and effectiveness of our approach.
Multi-View Clustering from the Perspective of Mutual Information
Feb 17, 2023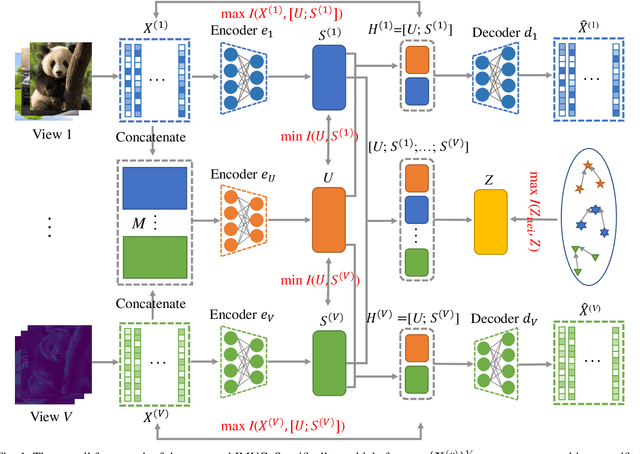



Exploring the complementary information of multi-view data to improve clustering effects is a crucial issue in multi-view clustering. In this paper, we propose a novel model based on information theory termed Informative Multi-View Clustering (IMVC), which extracts the common and view-specific information hidden in multi-view data and constructs a clustering-oriented comprehensive representation. More specifically, we concatenate multiple features into a unified feature representation, then pass it through a encoder to retrieve the common representation across views. Simultaneously, the features of each view are sent to a encoder to produce a compact view-specific representation, respectively. Thus, we constrain the mutual information between the common representation and view-specific representations to be minimal for obtaining multi-level information. Further, the common representation and view-specific representation are spliced to model the refined representation of each view, which is fed into a decoder to reconstruct the initial data with maximizing their mutual information. In order to form a comprehensive representation, the common representation and all view-specific representations are concatenated. Furthermore, to accommodate the comprehensive representation better for the clustering task, we maximize the mutual information between an instance and its k-nearest neighbors to enhance the intra-cluster aggregation, thus inducing well separation of different clusters at the overall aspect. Finally, we conduct extensive experiments on six benchmark datasets, and the experimental results indicate that the proposed IMVC outperforms other methods.
Subspace-Contrastive Multi-View Clustering
Oct 13, 2022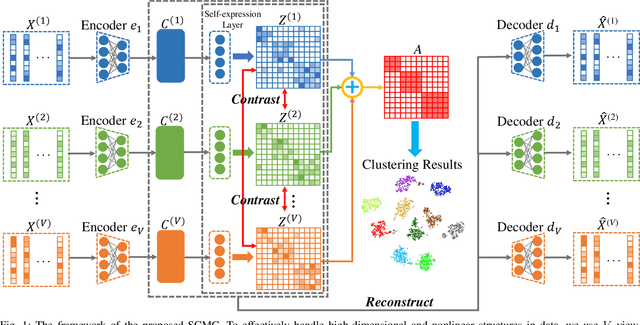
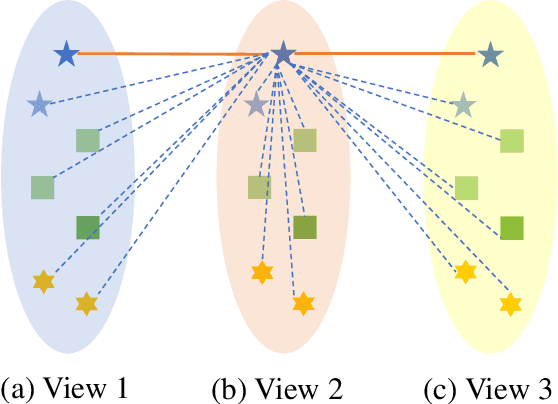
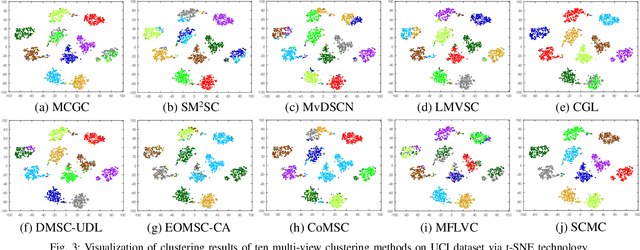
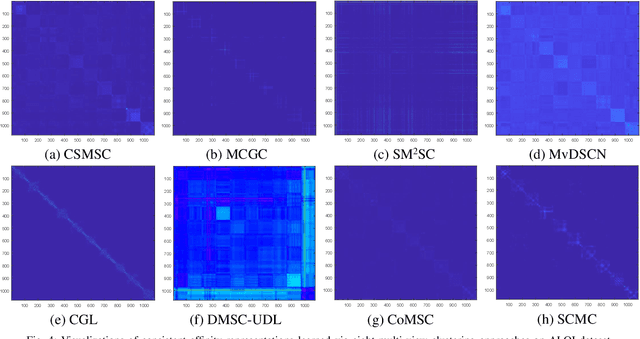
Most multi-view clustering methods are limited by shallow models without sound nonlinear information perception capability, or fail to effectively exploit complementary information hidden in different views. To tackle these issues, we propose a novel Subspace-Contrastive Multi-View Clustering (SCMC) approach. Specifically, SCMC utilizes view-specific auto-encoders to map the original multi-view data into compact features perceiving its nonlinear structures. Considering the large semantic gap of data from different modalities, we employ subspace learning to unify the multi-view data into a joint semantic space, namely the embedded compact features are passed through multiple self-expression layers to learn the subspace representations, respectively. In order to enhance the discriminability and efficiently excavate the complementarity of various subspace representations, we use the contrastive strategy to maximize the similarity between positive pairs while differentiate negative pairs. Thus, a weighted fusion scheme is developed to initially learn a consistent affinity matrix. Furthermore, we employ the graph regularization to encode the local geometric structure within varying subspaces for further fine-tuning the appropriate affinities between instances. To demonstrate the effectiveness of the proposed model, we conduct a large number of comparative experiments on eight challenge datasets, the experimental results show that SCMC outperforms existing shallow and deep multi-view clustering methods.
ADEPOS: A Novel Approximate Computing Framework for Anomaly Detection Systems and its Implementation in 65nm CMOS
Dec 04, 2019
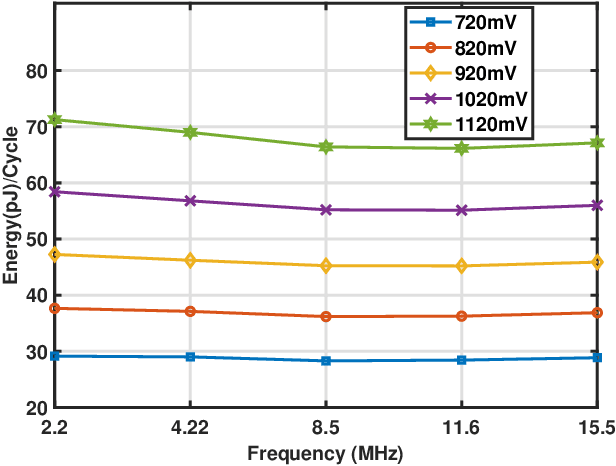
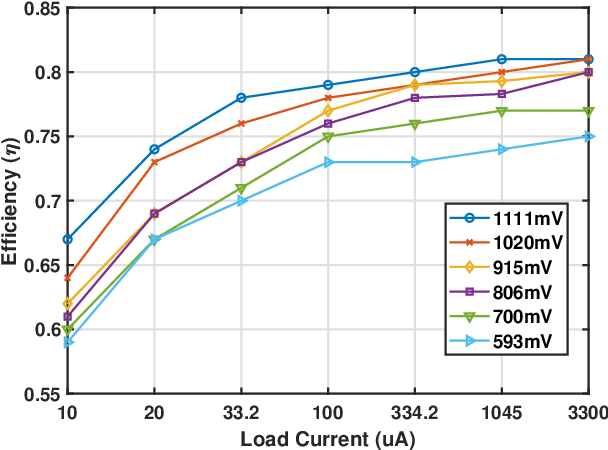
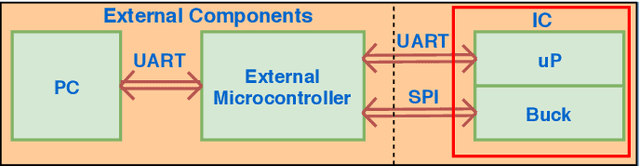
To overcome the energy and bandwidth limitations of traditional IoT systems, edge computing or information extraction at the sensor node has become popular. However, now it is important to create very low energy information extraction or pattern recognition systems. In this paper, we present an approximate computing method to reduce the computation energy of a specific type of IoT system used for anomaly detection (e.g. in predictive maintenance, epileptic seizure detection, etc). Termed as Anomaly Detection Based Power Savings (ADEPOS), our proposed method uses low precision computing and low complexity neural networks at the beginning when it is easy to distinguish healthy data. However, on the detection of anomalies, the complexity of the network and computing precision are adaptively increased for accurate predictions. We show that ensemble approaches are well suited for adaptively changing network size. To validate our proposed scheme, a chip has been fabricated in UMC65nm process that includes an MSP430 microprocessor along with an on-chip switching mode DC-DC converter for dynamic voltage and frequency scaling. Using NASA bearing dataset for machine health monitoring, we show that using ADEPOS we can achieve 8.95X saving of energy along the lifetime without losing any detection accuracy. The energy savings are obtained by reducing the execution time of the neural network on the microprocessor.
* 14 pages
Simultaneous Implementation Features Extraction and Recognition Using C3D Network for WiFi-based Human Activity Recognition
Nov 21, 2019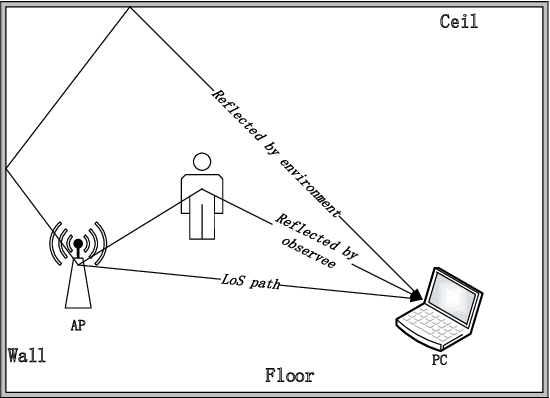

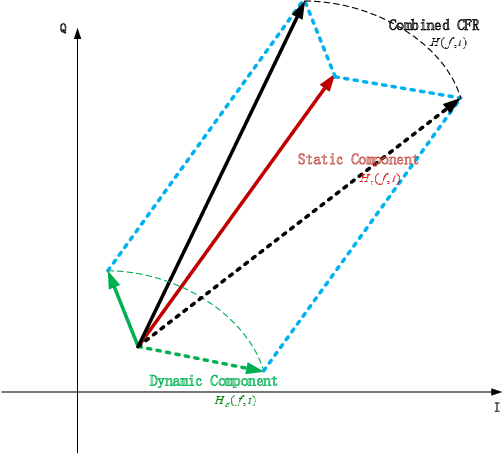
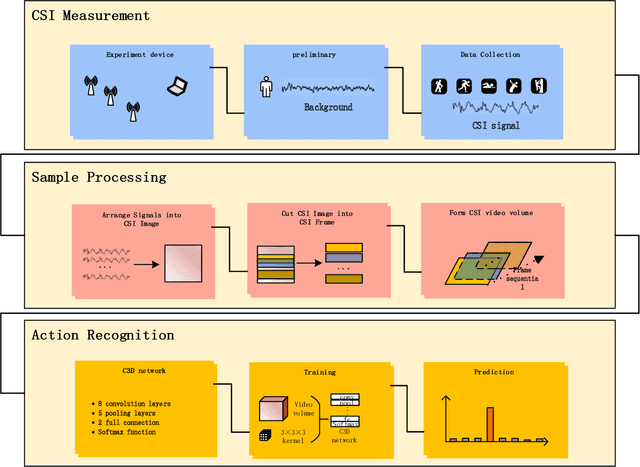
Human actions recognition has attracted more and more people's attention. Many technology have been developed to express human action's features, such as image, skeleton-based, and channel state information(CSI). Among them, on account of CSI's easy to be equipped and undemanding for light, and it has gained more and more attention in some special scene. However, the relationship between CSI signal and human actions is very complex, and some preliminary work must be done to make CSI features easy to understand for computer. Nowadays, many work departed CSI-based features' action dealing into two parts. One part is for features extraction and dimension reduce, and the other part is for time series problems. Some of them even omitted one of the two part work. Therefore, the accuracies of current recognition systems are far from satisfactory. In this paper, we propose a new deep learning based approach, i.e. C3D network and C3D network with attention mechanism, for human actions recognition using CSI signals. This kind of network can make feature extraction from spatial convolution and temporal convolution simultaneously, and through this network the two part of CSI-based human actions recognition mentioned above can be realized at the same time. The entire algorithm structure is simplified. The experimental results show that our proposed C3D network is able to achieve the best recognition performance for all activities when compared with some benchmark approaches.
Sparse, Collaborative, or Nonnegative Representation: Which Helps Pattern Classification?
Jun 12, 2018



The use of sparse representation (SR) and collaborative representation (CR) for pattern classification has been widely studied in tasks such as face recognition and object categorization. Despite the success of SR/CR based classifiers, it is still arguable whether it is the $\ell_{1}$-norm sparsity or the $\ell_{2}$-norm collaborative property that brings the success of SR/CR based classification. In this paper, we investigate the use of nonnegative representation (NR) for pattern classification, which is largely ignored by previous work. Our analyses reveal that NR can boost the representation power of homogeneous samples while limiting the representation power of heterogeneous samples, making the representation sparse and discriminative simultaneously and thus providing a more effective solution to representation based classification than SR/CR. Our experiments demonstrate that the proposed NR based classifier (NRC) outperforms previous representation based classifiers. With deep features as inputs, it also achieves state-of-the-art performance on various visual classification tasks.