 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace-Contrastive Multi-View Clustering
Oct 13, 2022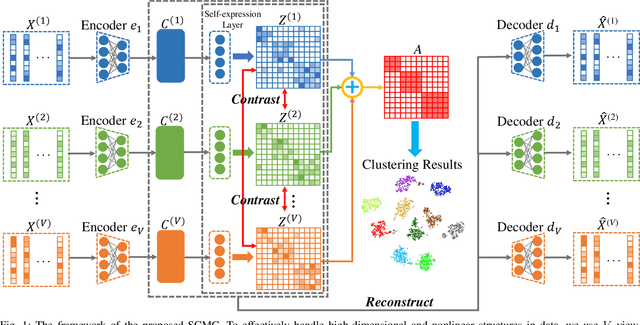
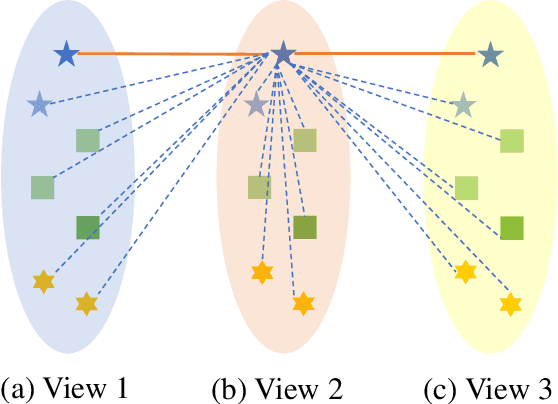
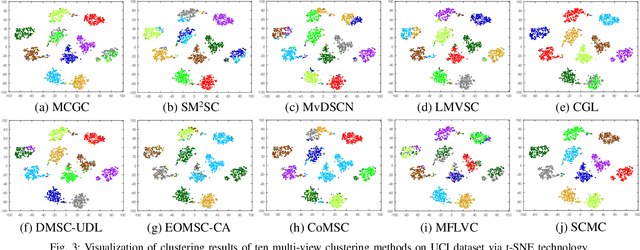
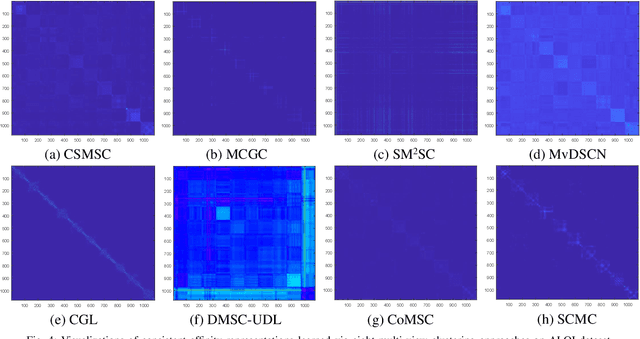
Most multi-view clustering methods are limited by shallow models without sound nonlinear information perception capability, or fail to effectively exploit complementary information hidden in different views. To tackle these issues, we propose a novel Subspace-Contrastive Multi-View Clustering (SCMC) approach. Specifically, SCMC utilizes view-specific auto-encoders to map the original multi-view data into compact features perceiving its nonlinear structures. Considering the large semantic gap of data from different modalities, we employ subspace learning to unify the multi-view data into a joint semantic space, namely the embedded compact features are passed through multiple self-expression layers to learn the subspace representations, respectively. In order to enhance the discriminability and efficiently excavate the complementarity of various subspace representations, we use the contrastive strategy to maximize the similarity between positive pairs while differentiate negative pairs. Thus, a weighted fusion scheme is developed to initially learn a consistent affinity matrix. Furthermore, we employ the graph regularization to encode the local geometric structure within varying subspaces for further fine-tuning the appropriate affinities between instances. To demonstrate the effectiveness of the proposed model, we conduct a large number of comparative experiments on eight challenge datasets, the experimental results show that SCMC outperforms existing shallow and deep multi-view clustering methods.