 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQB-LIF: Learnable-Scale Quantized Burst Neurons for Efficient SNNs
Apr 28, 2026Binary spike coding enables sparse and event-driven computation in spiking neural networks (SNNs), yet its 1-bit-per-timestep representation fundamentally limits information throughput. This bottleneck becomes increasingly restrictive in deep architectures under short simulation horizons. We propose the Quantized Burst-LIF (QB-LIF) neuron, which reformulates burst spiking as a saturated uniform quantization of membrane potentials with a learnable scale. Instead of relying on predefined multi-threshold structures, QB-LIF treats the quantization scale as a trainable parameter, allowing each layer to autonomously adapt its spiking resolution to the underlying membrane-potential statistics. To preserve hardware efficiency, we introduce an absorbable scale strategy that folds the learned quantized scale into synaptic weights during inference, maintaining a strict accumulate-only (AC) execution paradigm. To enable stable optimization in the discrete multi-level space, we further design ReLSG-ET, a rectified-linear surrogate gradient with exponential tails that sustains gradient flow across burst intervals. Extensive experiments on static (CIFAR-10/100, ImageNet) and event-driven (CIFAR10-DVS, DVS128-Gesture) benchmarks demonstrate that QB-LIF consistently outperforms binary and fixed-burst SNNs, achieving higher accuracy under ultra-low latency while preserving neuromorphic compatibility.
Unconstrained Multi-view Human Pose Estimation with Algebraic Priors
Apr 27, 2026Recovering 3D human pose from multi-view imagery typically relies on precise camera calibration, which is often unavailable in real-world scenarios, thereby severely limiting the applicability of existing methods. To overcome this challenge, we propose an unconstrained framework that synergizes deep neural networks, algebraic priors, and temporal dynamics for uncalibrated multi-view human pose estimation. First, we introduce the Triangulation with Transformer Regressor (TTR), which reformulates classical triangulation into a data-driven token fusion process to bypass the dependency on explicit camera parameters. Second, to explicitly embed the inherent algebraic relations of the multi-view variety into the learning process, we propose the Gröbner basis Corrector (GC). This pioneering loss formulation enforces constraints derived from the multi-view variety to ensure the neural predictions strictly adhere to the laws of projective geometry. Finally, we devise the Temporal Equivariant Rectifier (TER), which exploits the equivariance property of human motion to impose temporal coherence and structural consistency, effectively mitigating scale ambiguity in uncalibrated settings. Extensive evaluations on standard benchmarks demonstrate that our framework establishes a new state-of-the-art for uncalibrated multi-view human pose estimation. Notably, our approach significantly closes the performance gap between calibration-free methods and fully calibrated oracles.
Class Incremental Medical Image Segmentation via Prototype-Guided Calibration and Dual-Aligned Distillation
Nov 11, 2025



Class incremental medical image segmentation (CIMIS) aims to preserve knowledge of previously learned classes while learning new ones without relying on old-class labels. However, existing methods 1) either adopt one-size-fits-all strategies that treat all spatial regions and feature channels equally, which may hinder the preservation of accurate old knowledge, 2) or focus solely on aligning local prototypes with global ones for old classes while overlooking their local representations in new data, leading to knowledge degradation. To mitigate the above issues, we propose Prototype-Guided Calibration Distillation (PGCD) and Dual-Aligned Prototype Distillation (DAPD) for CIMIS in this paper. Specifically, PGCD exploits prototype-to-feature similarity to calibrate class-specific distillation intensity in different spatial regions, effectively reinforcing reliable old knowledge and suppressing misleading information from old classes. Complementarily, DAPD aligns the local prototypes of old classes extracted from the current model with both global prototypes and local prototypes, further enhancing segmentation performance on old categories. Comprehensive evaluations on two widely used multi-organ segmentation benchmarks demonstrate that our method outperforms state-of-the-art methods, highlighting its robustness and generalization capabilities.
Exploiting Unlabeled Structures through Task Consistency Training for Versatile Medical Image Segmentation
Sep 05, 2025



Versatile medical image segmentation (VMIS) targets the segmentation of multiple classes, while obtaining full annotations for all classes is often impractical due to the time and labor required. Leveraging partially labeled datasets (PLDs) presents a promising alternative; however, current VMIS approaches face significant class imbalance due to the unequal category distribution in PLDs. Existing methods attempt to address this by generating pseudo-full labels. Nevertheless, these typically require additional models and often result in potential performance degradation from label noise. In this work, we introduce a Task Consistency Training (TCT) framework to address class imbalance without requiring extra models. TCT includes a backbone network with a main segmentation head (MSH) for multi-channel predictions and multiple auxiliary task heads (ATHs) for task-specific predictions. By enforcing a consistency constraint between the MSH and ATH predictions, TCT effectively utilizes unlabeled anatomical structures. To avoid error propagation from low-consistency, potentially noisy data, we propose a filtering strategy to exclude such data. Additionally, we introduce a unified auxiliary uncertainty-weighted loss (UAUWL) to mitigate segmentation quality declines caused by the dominance of specific tasks. Extensive experiments on eight abdominal datasets from diverse clinical sites demonstrate our approach's effectiveness.
EAUWSeg: Eliminating annotation uncertainty in weakly-supervised medical image segmentation
Jan 03, 2025



Weakly-supervised medical image segmentation is gaining traction as it requires only rough annotations rather than accurate pixel-to-pixel labels, thereby reducing the workload for specialists. Although some progress has been made, there is still a considerable performance gap between the label-efficient methods and fully-supervised one, which can be attributed to the uncertainty nature of these weak labels. To address this issue, we propose a novel weak annotation method coupled with its learning framework EAUWSeg to eliminate the annotation uncertainty. Specifically, we first propose the Bounded Polygon Annotation (BPAnno) by simply labeling two polygons for a lesion. Then, the tailored learning mechanism that explicitly treat bounded polygons as two separated annotations is proposed to learn invariant feature by providing adversarial supervision signal for model training. Subsequently, a confidence-auxiliary consistency learner incorporates with a classification-guided confidence generator is designed to provide reliable supervision signal for pixels in uncertain region by leveraging the feature presentation consistency across pixels within the same category as well as class-specific information encapsulated in bounded polygons annotation. Experimental results demonstrate that EAUWSeg outperforms existing weakly-supervised segmentation methods. Furthermore, compared to fully-supervised counterparts, the proposed method not only delivers superior performance but also costs much less annotation workload. This underscores the superiority and effectiveness of our approach.
SegKAN: High-Resolution Medical Image Segmentation with Long-Distance Dependencies
Dec 28, 2024Hepatic vessels in computed tomography scans often suffer from image fragmentation and noise interference, making it difficult to maintain vessel integrity and posing significant challenges for vessel segmentation. To address this issue, we propose an innovative model: SegKAN. First, we improve the conventional embedding module by adopting a novel convolutional network structure for image embedding, which smooths out image noise and prevents issues such as gradient explosion in subsequent stages. Next, we transform the spatial relationships between Patch blocks into temporal relationships to solve the problem of capturing positional relationships between Patch blocks in traditional Vision Transformer models. We conducted experiments on a Hepatic vessel dataset, and compared to the existing state-of-the-art model, the Dice score improved by 1.78%. These results demonstrate that the proposed new structure effectively enhances the segmentation performance of high-resolution extended objects. Code will be available at https://github.com/goblin327/SegKAN
A Lightweight U-like Network Utilizing Neural Memory Ordinary Differential Equations for Slimming the Decoder
Dec 09, 2024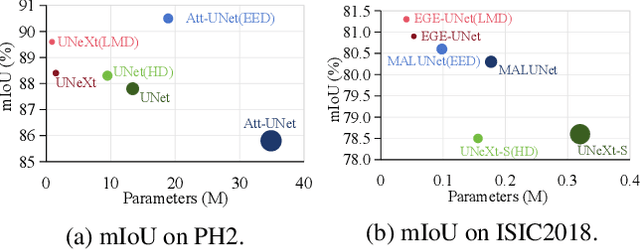
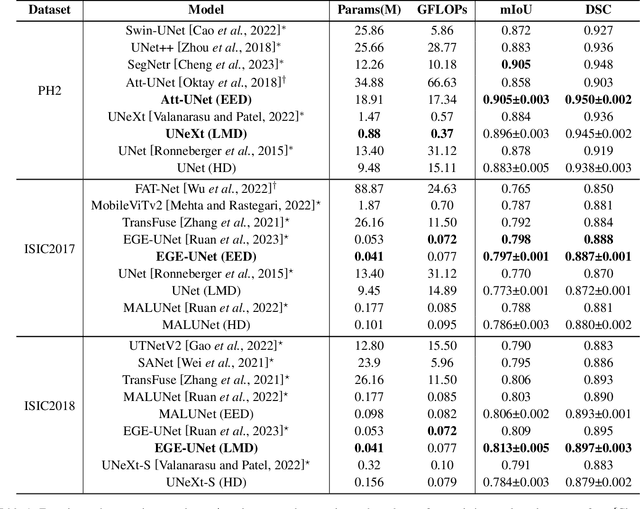
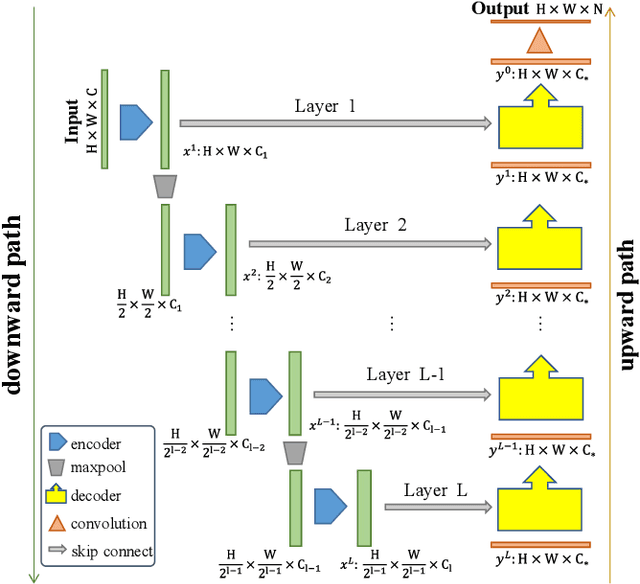
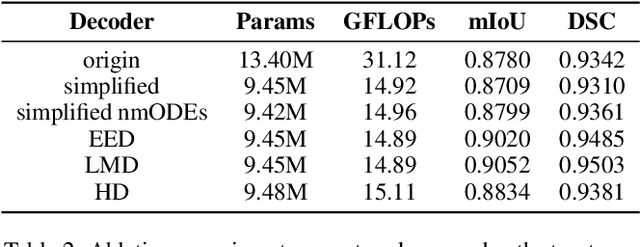
In recent years, advanced U-like networks have demonstrated remarkable performance in medical image segmentation tasks. However, their drawbacks, including excessive parameters, high computational complexity, and slow inference speed, pose challenges for practical implementation in scenarios with limited computational resources. Existing lightweight U-like networks have alleviated some of these problems, but they often have pre-designed structures and consist of inseparable modules, limiting their application scenarios. In this paper, we propose three plug-and-play decoders by employing different discretization methods of the neural memory Ordinary Differential Equations (nmODEs). These decoders integrate features at various levels of abstraction by processing information from skip connections and performing numerical operations on upward path. Through experiments on the PH2, ISIC2017, and ISIC2018 datasets, we embed these decoders into different U-like networks, demonstrating their effectiveness in significantly reducing the number of parameters and FLOPs while maintaining performance. In summary, the proposed discretized nmODEs decoders are capable of reducing the number of parameters by about 20% ~ 50% and FLOPs by up to 74%, while possessing the potential to adapt to all U-like networks. Our code is available at https://github.com/nayutayuki/Lightweight-nmODE-Decoders-For-U-like-networks.
MedDet: Generative Adversarial Distillation for Efficient Cervical Disc Herniation Detection
Aug 30, 2024Cervical disc herniation (CDH) is a prevalent musculoskeletal disorder that significantly impacts health and requires labor-intensive analysis from experts. Despite advancements in automated detection of medical imaging, two significant challenges hinder the real-world application of these methods. First, the computational complexity and resource demands present a significant gap for real-time application. Second, noise in MRI reduces the effectiveness of existing methods by distorting feature extraction. To address these challenges, we propose three key contributions: Firstly, we introduced MedDet, which leverages the multi-teacher single-student knowledge distillation for model compression and efficiency, meanwhile integrating generative adversarial training to enhance performance. Additionally, we customize the second-order nmODE to improve the model's resistance to noise in MRI. Lastly, we conducted comprehensive experiments on the CDH-1848 dataset, achieving up to a 5% improvement in mAP compared to previous methods. Our approach also delivers over 5 times faster inference speed, with approximately 67.8% reduction in parameters and 36.9% reduction in FLOPs compared to the teacher model. These advancements significantly enhance the performance and efficiency of automated CDH detection, demonstrating promising potential for future application in clinical practice. See project website https://steve-zeyu-zhang.github.io/MedDet
Strengthening Layer Interaction via Dynamic Layer Attention
Jun 19, 2024In recent years, employing layer attention to enhance interaction among hierarchical layers has proven to be a significant advancement in building network structures. In this paper, we delve into the distinction between layer attention and the general attention mechanism, noting that existing layer attention methods achieve layer interaction on fixed feature maps in a static manner. These static layer attention methods limit the ability for context feature extraction among layers. To restore the dynamic context representation capability of the attention mechanism, we propose a Dynamic Layer Attention (DLA) architecture. The DLA comprises dual paths, where the forward path utilizes an improved recurrent neural network block, named Dynamic Sharing Unit (DSU), for context feature extraction. The backward path updates features using these shared context representations. Finally, the attention mechanism is applied to these dynamically refreshed feature maps among layers. Experimental results demonstrate the effectiveness of the proposed DLA architecture, outperforming other state-of-the-art methods in image recognition and object detection tasks. Additionally, the DSU block has been evaluated as an efficient plugin in the proposed DLA architecture.The code is available at https://github.com/tunantu/Dynamic-Layer-Attention.
Fourier Boundary Features Network with Wider Catchers for Glass Segmentation
May 15, 2024



Glass largely blurs the boundary between the real world and the reflection. The special transmittance and reflectance quality have confused the semantic tasks related to machine vision. Therefore, how to clear the boundary built by glass, and avoid over-capturing features as false positive information in deep structure, matters for constraining the segmentation of reflection surface and penetrating glass. We proposed the Fourier Boundary Features Network with Wider Catchers (FBWC), which might be the first attempt to utilize sufficiently wide horizontal shallow branches without vertical deepening for guiding the fine granularity segmentation boundary through primary glass semantic information. Specifically, we designed the Wider Coarse-Catchers (WCC) for anchoring large area segmentation and reducing excessive extraction from a structural perspective. We embed fine-grained features by Cross Transpose Attention (CTA), which is introduced to avoid the incomplete area within the boundary caused by reflection noise. For excavating glass features and balancing high-low layers context, a learnable Fourier Convolution Controller (FCC) is proposed to regulate information integration robustly. The proposed method has been validated on three different public glass segmentation datasets. Experimental results reveal that the proposed method yields better segmentation performance compared with the state-of-the-art (SOTA) methods in glass image segmentation.