 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Dictionary Learning with An Intra-class Constraint
Jul 14, 2022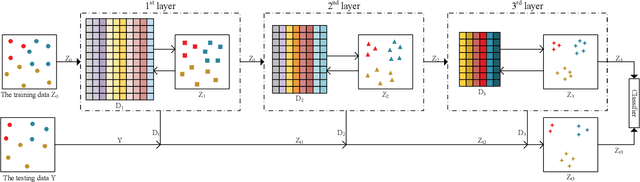
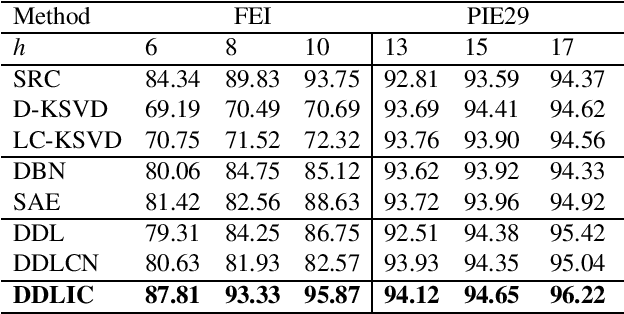
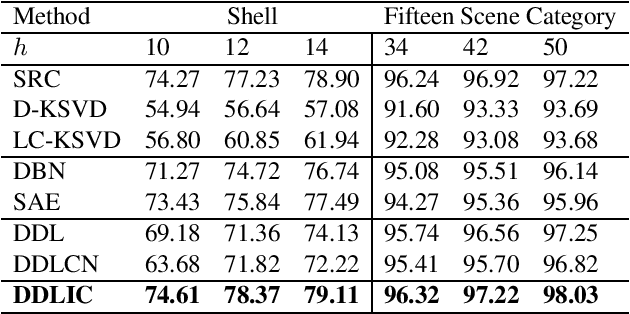
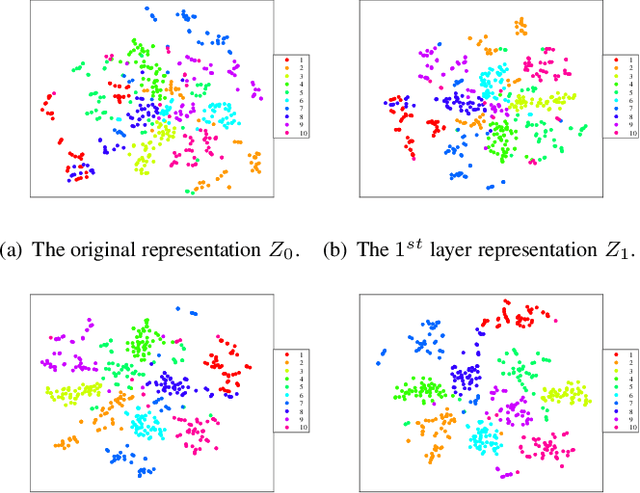
In recent years, deep dictionary learning (DDL)has attracted a great amount of attention due to its effectiveness for representation learning and visual recognition.~However, most existing methods focus on unsupervised deep dictionary learning, failing to further explore the category information.~To make full use of the category information of different samples, we propose a novel deep dictionary learning model with an intra-class constraint (DDLIC) for visual classification. Specifically, we design the intra-class compactness constraint on the intermediate representation at different levels to encourage the intra-class representations to be closer to each other, and eventually the learned representation becomes more discriminative.~Unlike the traditional DDL methods, during the classification stage, our DDLIC performs a layer-wise greedy optimization in a similar way to the training stage. Experimental results on four image datasets show that our method is superior to the state-of-the-art methods.
HAWQV3: Dyadic Neural Network Quantization
Nov 20, 2020
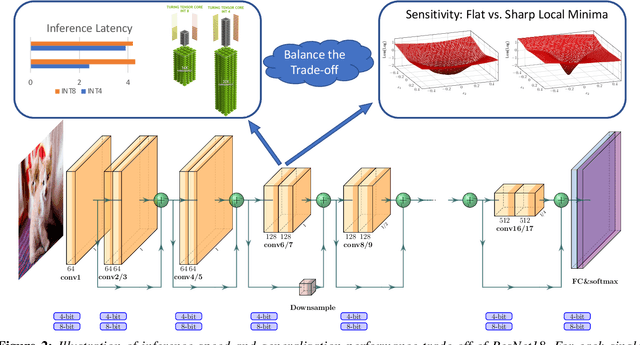
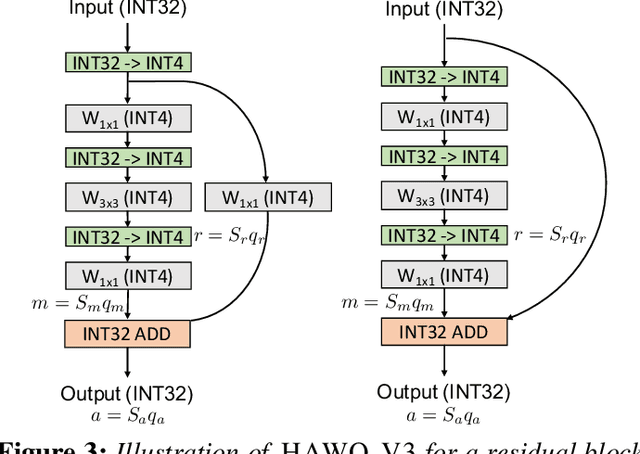
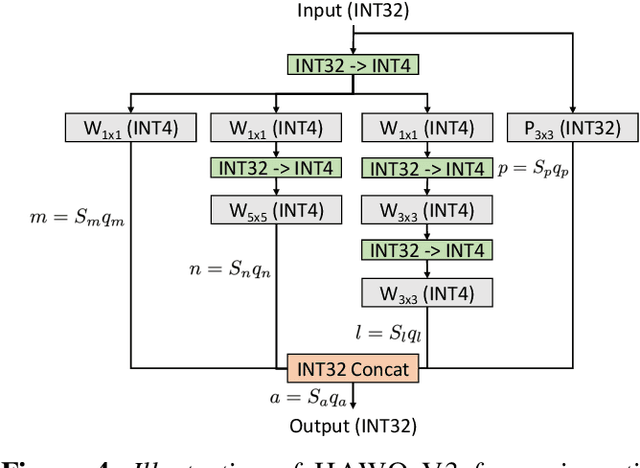
Quantization is one of the key techniques used to make Neural Networks (NNs) faster and more energy efficient. However, current low precision quantization algorithms often have the hidden cost of conversion back and forth from floating point to quantized integer values. This hidden cost limits the latency improvement realized by quantizing NNs. To address this, we present HAWQV3, a novel dyadic quantization framework. The contributions of HAWQV3 are the following. (i) The entire inference process consists of only integer multiplication, addition, and bit shifting in INT4/8 mixed precision, without any floating point operations/casting or even integer division. (ii) We pose the mixed-precision quantization as an integer linear programming problem, where the bit precision setting is computed to minimize model perturbation, while observing application specific constraints on memory footprint, latency, and BOPS. (iii) To verify our approach, we develop the first open source 4-bit mixed-precision quantization in TVM, and we directly deploy the quantized models to T4 GPUs using only the Turing Tensor Cores. We observe an average speed up of $1.45\times$ for uniform 4-bit, as compared to uniform 8-bit, precision for ResNet50. (iv) We extensively test the proposed dyadic quantization approach on multiple different NNs, including ResNet18/50 and InceptionV3, for various model compression levels with/without mixed precision. For instance, we achieve an accuracy of $78.50\%$ with dyadic INT8 quantization, which is more than $4\%$ higher than prior integer-only work for InceptionV3. Furthermore, we show that mixed-precision INT4/8 quantization can be used to achieve higher speed ups, as compared to INT8 inference, with minimal impact on accuracy. For example, for ResNet50 we can reduce INT8 latency by $23\%$ with mixed precision and still achieve $76.73\%$ accuracy.
FeatGraph: A Flexible and Efficient Backend for Graph Neural Network Systems
Sep 29, 2020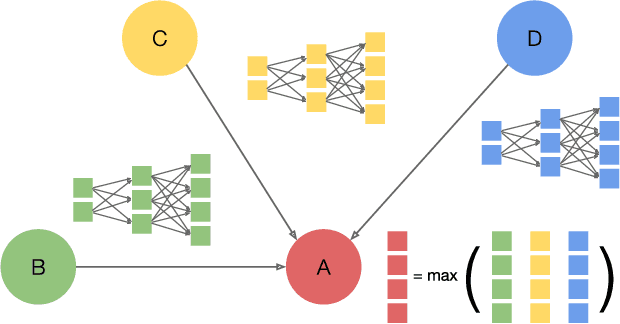
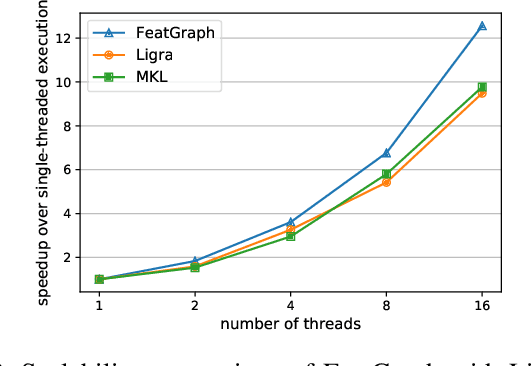
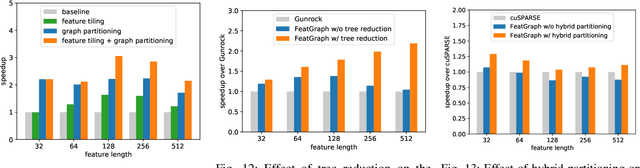
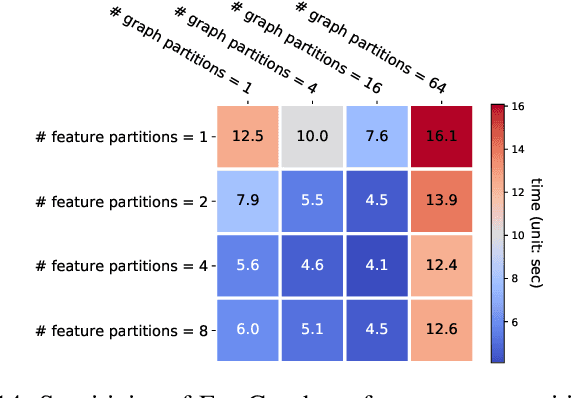
Graph neural networks (GNNs) are gaining increasing popularity as a promising approach to machine learning on graphs. Unlike traditional graph workloads where each vertex/edge is associated with a scalar, GNNs attach a feature tensor to each vertex/edge. This additional feature dimension, along with consequently more complex vertex- and edge-wise computations, has enormous implications on locality and parallelism, which existing graph processing systems fail to exploit. This paper proposes FeatGraph to accelerate GNN workloads by co-optimizing graph traversal and feature dimension computation. FeatGraph provides a flexible programming interface to express diverse GNN models by composing coarse-grained sparse templates with fine-grained user-defined functions (UDFs) on each vertex/edge. FeatGraph incorporates optimizations for graph traversal into the sparse templates and allows users to specify optimizations for UDFs with a feature dimension schedule (FDS). FeatGraph speeds up end-to-end GNN training and inference by up to 32x on CPU and 7x on GPU.