 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dual-Domain Multi-Scale Representations for Single Image Deraining
Mar 15, 2025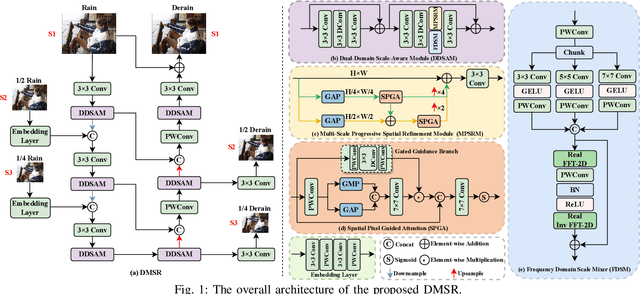
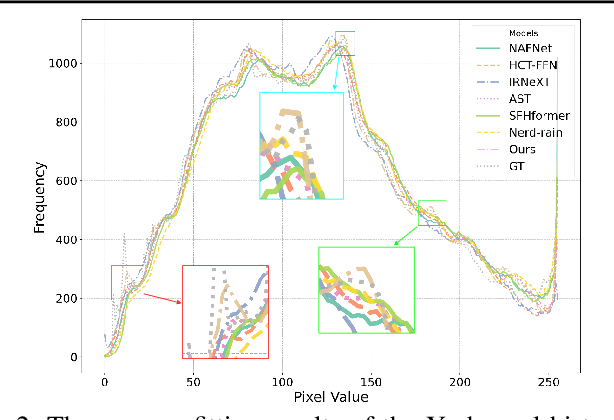

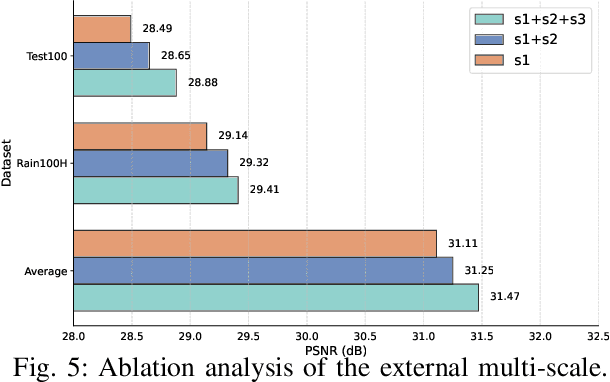
Existing image deraining methods typically rely on single-input, single-output, and single-scale architectures, which overlook the joint multi-scale information between external and internal features. Furthermore, single-domain representations are often too restrictive, limiting their ability to handle the complexities of real-world rain scenarios. To address these challenges, we propose a novel Dual-Domain Multi-Scale Representation Network (DMSR). The key idea is to exploit joint multi-scale representations from both external and internal domains in parallel while leveraging the strengths of both spatial and frequency domains to capture more comprehensive properties. Specifically, our method consists of two main components: the Multi-Scale Progressive Spatial Refinement Module (MPSRM) and the Frequency Domain Scale Mixer (FDSM). The MPSRM enables the interaction and coupling of multi-scale expert information within the internal domain using a hierarchical modulation and fusion strategy. The FDSM extracts multi-scale local information in the spatial domain, while also modeling global dependencies in the frequency domain. Extensive experiments show that our model achieves state-of-the-art performance across six benchmark datasets.
Fraesormer: Learning Adaptive Sparse Transformer for Efficient Food Recognition
Mar 15, 2025In recent years, Transformer has witnessed significant progress in food recognition. However, most existing approaches still face two critical challenges in lightweight food recognition: (1) the quadratic complexity and redundant feature representation from interactions with irrelevant tokens; (2) static feature recognition and single-scale representation, which overlook the unstructured, non-fixed nature of food images and the need for multi-scale features. To address these, we propose an adaptive and efficient sparse Transformer architecture (Fraesormer) with two core designs: Adaptive Top-k Sparse Partial Attention (ATK-SPA) and Hierarchical Scale-Sensitive Feature Gating Network (HSSFGN). ATK-SPA uses a learnable Gated Dynamic Top-K Operator (GDTKO) to retain critical attention scores, filtering low query-key matches that hinder feature aggregation. It also introduces a partial channel mechanism to reduce redundancy and promote expert information flow, enabling local-global collaborative modeling. HSSFGN employs gating mechanism to achieve multi-scale feature representation, enhancing contextual semantic information. Extensive experiments show that Fraesormer outperforms state-of-the-art methods. code is available at https://zs1314.github.io/Fraesormer.
SegKAN: High-Resolution Medical Image Segmentation with Long-Distance Dependencies
Dec 28, 2024Hepatic vessels in computed tomography scans often suffer from image fragmentation and noise interference, making it difficult to maintain vessel integrity and posing significant challenges for vessel segmentation. To address this issue, we propose an innovative model: SegKAN. First, we improve the conventional embedding module by adopting a novel convolutional network structure for image embedding, which smooths out image noise and prevents issues such as gradient explosion in subsequent stages. Next, we transform the spatial relationships between Patch blocks into temporal relationships to solve the problem of capturing positional relationships between Patch blocks in traditional Vision Transformer models. We conducted experiments on a Hepatic vessel dataset, and compared to the existing state-of-the-art model, the Dice score improved by 1.78%. These results demonstrate that the proposed new structure effectively enhances the segmentation performance of high-resolution extended objects. Code will be available at https://github.com/goblin327/SegKAN