 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLSI Extreme Learning Machine: A Design Space Exploration
May 03, 2016



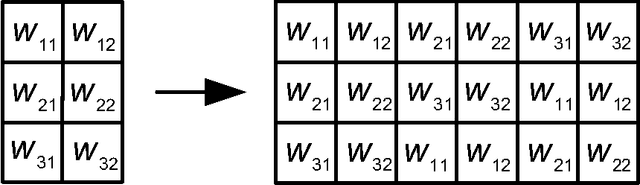
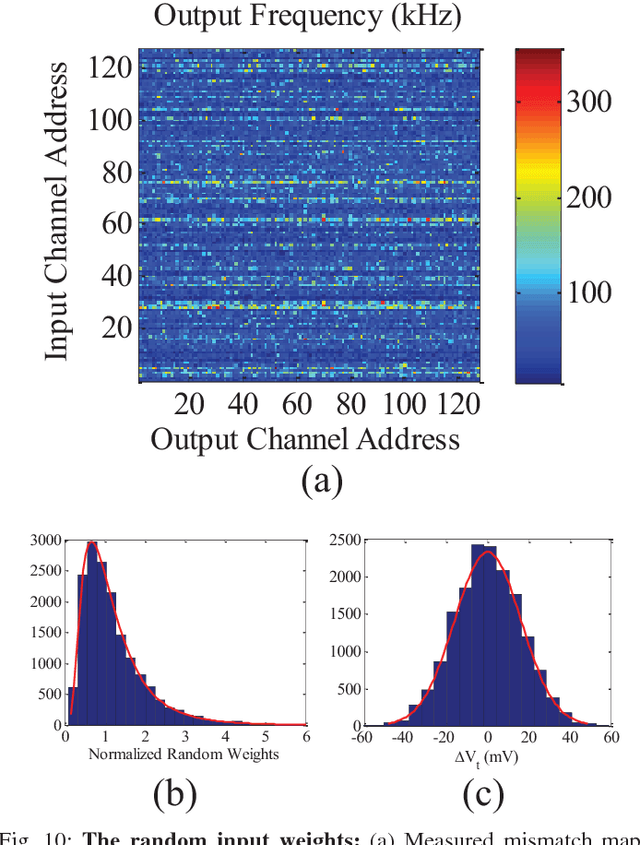
In this paper, we describe a compact low-power, high performance hardware implementation of the extreme learning machine (ELM) for machine learning applications. Mismatch in current mirrors are used to perform the vector-matrix multiplication that forms the first stage of this classifier and is the most computationally intensive. Both regression and classification (on UCI data sets) are demonstrated and a design space trade-off between speed, power and accuracy is explored. Our results indicate that for a wide set of problems, $\sigma V_T$ in the range of $15-25$mV gives optimal results. An input weight matrix rotation method to extend the input dimension and hidden layer size beyond the physical limits imposed by the chip is also described. This allows us to overcome a major limit imposed on most hardware machine learners. The chip is implemented in a $0.35 \mu$m CMOS process and occupies a die area of around 5 mm $\times$ 5 mm. Operating from a $1$ V power supply, it achieves an energy efficiency of $0.47$ pJ/MAC at a classification rate of $31.6$ kHz.
Hardware Architecture for Large Parallel Array of Random Feature Extractors applied to Image Recognition
Dec 24, 2015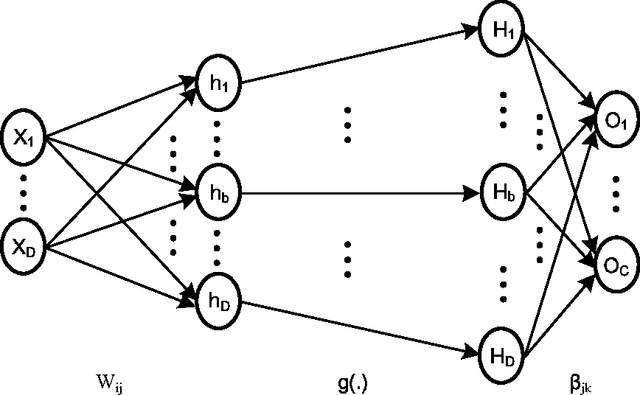


We demonstrate a low-power and compact hardware implementation of Random Feature Extractor (RFE) core. With complex tasks like Image Recognition requiring a large set of features, we show how weight reuse technique can allow to virtually expand the random features available from RFE core. Further, we show how to avoid computation cost wasted for propagating "incognizant" or redundant random features. For proof of concept, we validated our approach by using our RFE core as the first stage of Extreme Learning Machine (ELM)--a two layer neural network--and were able to achieve $>97\%$ accuracy on MNIST database of handwritten digits. ELM's first stage of RFE is done on an analog ASIC occupying $5$mm$\times5$mm area in $0.35\mu$m CMOS and consuming $5.95$ $\mu$J/classify while using $\approx 5000$ effective hidden neurons. The ELM second stage consisting of just adders can be implemented as digital circuit with estimated power consumption of $20.9$ nJ/classify. With a total energy consumption of only $5.97$ $\mu$J/classify, this low-power mixed signal ASIC can act as a co-processor in portable electronic gadgets with cameras.
A 128 channel Extreme Learning Machine based Neural Decoder for Brain Machine Interfaces
Sep 27, 2015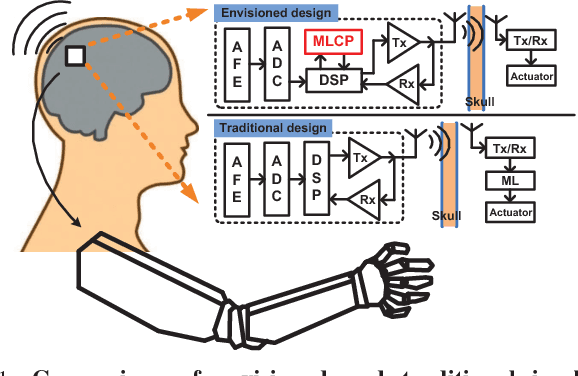
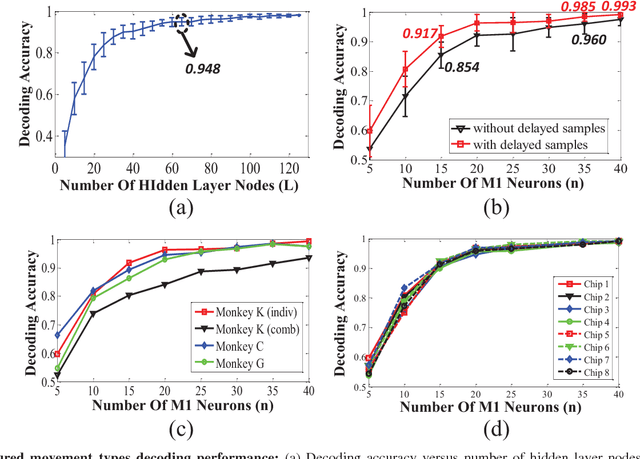
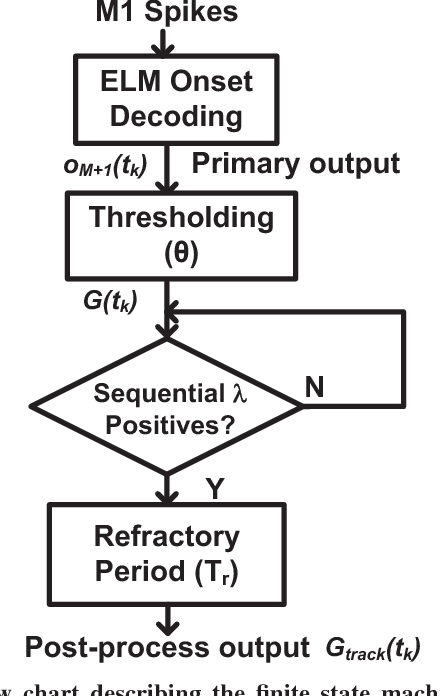
Currently, state-of-the-art motor intention decoding algorithms in brain-machine interfaces are mostly implemented on a PC and consume significant amount of power. A machine learning co-processor in 0.35um CMOS for motor intention decoding in brain-machine interfaces is presented in this paper. Using Extreme Learning Machine algorithm and low-power analog processing, it achieves an energy efficiency of 290 GMACs/W at a classification rate of 50 Hz. The learning in second stage and corresponding digitally stored coefficients are used to increase robustness of the core analog processor. The chip is verified with neural data recorded in monkey finger movements experiment, achieving a decoding accuracy of 99.3% for movement type. The same co-processor is also used to decode time of movement from asynchronous neural spikes. With time-delayed feature dimension enhancement, the classification accuracy can be increased by 5% with limited number of input channels. Further, a sparsity promoting training scheme enables reduction of number of programmable weights by ~2X.