 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-visual video face hallucination with frequency supervision and cross modality support by speech based lip reading loss
Nov 20, 2022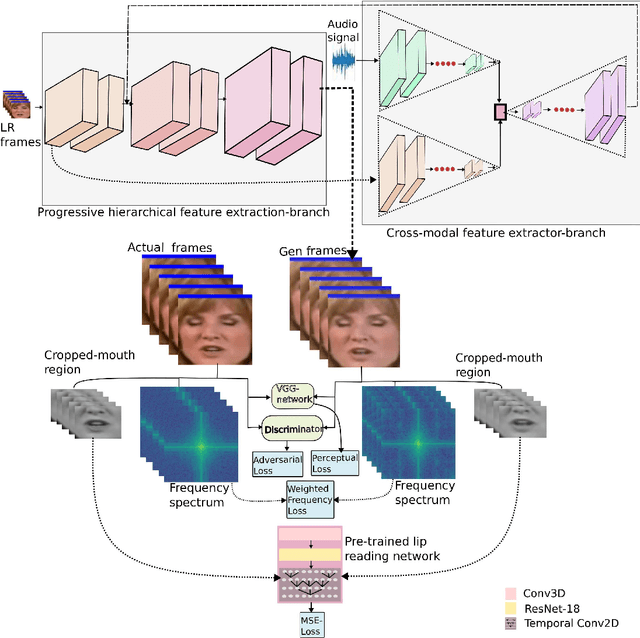
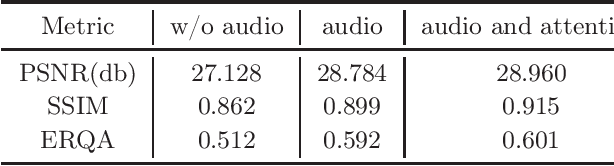


Recently, there has been numerous breakthroughs in face hallucination tasks. However, the task remains rather challenging in videos in comparison to the images due to inherent consistency issues. The presence of extra temporal dimension in video face hallucination makes it non-trivial to learn the facial motion through out the sequence. In order to learn these fine spatio-temporal motion details, we propose a novel cross-modal audio-visual Video Face Hallucination Generative Adversarial Network (VFH-GAN). The architecture exploits the semantic correlation of between the movement of the facial structure and the associated speech signal. Another major issue in present video based approaches is the presence of blurriness around the key facial regions such as mouth and lips - where spatial displacement is much higher in comparison to other areas. The proposed approach explicitly defines a lip reading loss to learn the fine grain motion in these facial areas. During training, GANs have potential to fit frequencies from low to high, which leads to miss the hard to synthesize frequencies. Therefore, to add salient frequency features to the network we add a frequency based loss function. The visual and the quantitative comparison with state-of-the-art shows a significant improvement in performance and efficacy.
Variational Approach for Intensity Domain Multi-exposure Image Fusion
Jul 09, 2022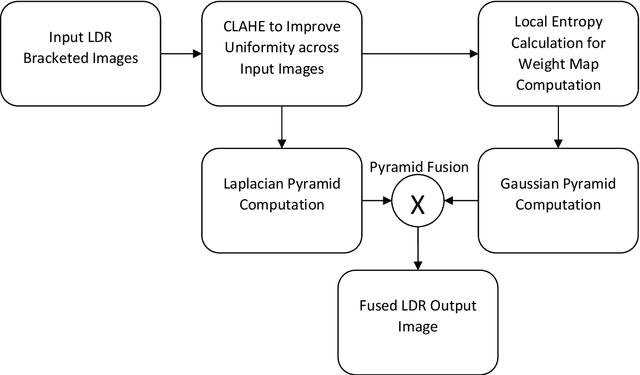



Recent innovations shows that blending of details captured by single Low Dynamic Range (LDR) sensor overcomes the limitations of standard digital cameras to capture details from high dynamic range scene. We present a method to produce well-exposed fused image that can be displayed directly on conventional display devices. The ambition is to preserve details in poorly illuminated and brightly illuminated regions. Proposed approach does not require true radiance reconstruction and tone manipulation steps. The aforesaid objective is achieved by taking into account local information measure that select well-exposed regions across input exposures. In addition, Contrast Limited Adaptive Histogram equalization (CLAHE) is introduced to improve uniformity of input multi-exposure image prior to fusion.
From Convolutions towards Spikes: The Environmental Metric that the Community currently Misses
Nov 16, 2021Today, the AI community is obsessed with 'state-of-the-art' scores (80% papers in NeurIPS) as the major performance metrics, due to which an important parameter, i.e., the environmental metric, remains unreported. Computational capabilities were a limiting factor a decade ago; however, in foreseeable future circumstances, the challenge will be to develop environment-friendly and power-efficient algorithms. The human brain, which has been optimizing itself for almost a million years, consumes the same amount of power as a typical laptop. Therefore, developing nature-inspired algorithms is one solution to it. In this study, we show that currently used ANNs are not what we find in nature, and why, although having lower performance, spiking neural networks, which mirror the mammalian visual cortex, have attracted much interest. We further highlight the hardware gaps restricting the researchers from using spike-based computation for developing neuromorphic energy-efficient microchips on a large scale. Using neuromorphic processors instead of traditional GPUs might be more environment friendly and efficient. These processors will turn SNNs into an ideal solution for the problem. This paper presents in-depth attention highlighting the current gaps, the lack of comparative research, while proposing new research directions at the intersection of two fields -- neuroscience and deep learning. Further, we define a new evaluation metric 'NATURE' for reporting the carbon footprint of AI models.
Entropy optimized semi-supervised decomposed vector-quantized variational autoencoder model based on transfer learning for multiclass text classification and generation
Nov 10, 2021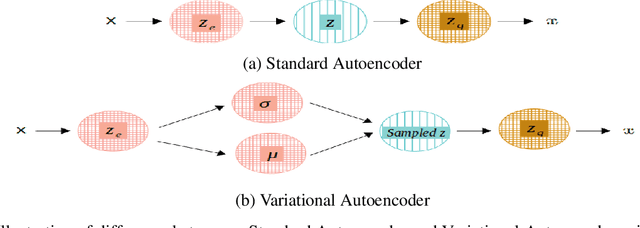

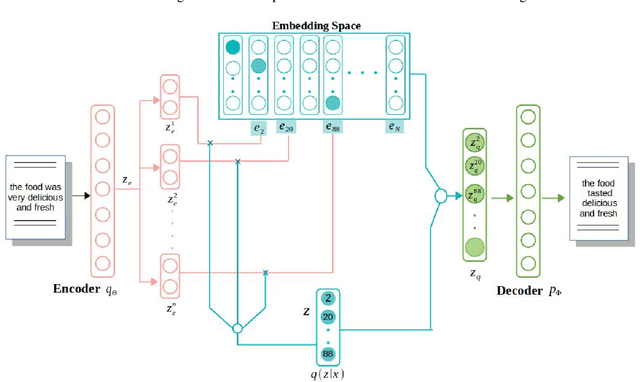

Semisupervised text classification has become a major focus of research over the past few years. Hitherto, most of the research has been based on supervised learning, but its main drawback is the unavailability of labeled data samples in practical applications. It is still a key challenge to train the deep generative models and learn comprehensive representations without supervision. Even though continuous latent variables are employed primarily in deep latent variable models, discrete latent variables, with their enhanced understandability and better compressed representations, are effectively used by researchers. In this paper, we propose a semisupervised discrete latent variable model for multi-class text classification and text generation. The proposed model employs the concept of transfer learning for training a quantized transformer model, which is able to learn competently using fewer labeled instances. The model applies decomposed vector quantization technique to overcome problems like posterior collapse and index collapse. Shannon entropy is used for the decomposed sub-encoders, on which a variable DropConnect is applied, to retain maximum information. Moreover, gradients of the Loss function are adaptively modified during backpropagation from decoder to encoder to enhance the performance of the model. Three conventional datasets of diversified range have been used for validating the proposed model on a variable number of labeled instances. Experimental results indicate that the proposed model has surpassed the state-of-the-art models remarkably.
Frequency Aware Face Hallucination Generative Adversarial Network with Semantic Structural Constraint
Oct 05, 2021



In this paper, we address the issue of face hallucination. Most current face hallucination methods rely on two-dimensional facial priors to generate high resolution face images from low resolution face images. These methods are only capable of assimilating global information into the generated image. Still there exist some inherent problems in these methods; such as, local features, subtle structural details and missing depth information in final output image. Present work proposes a Generative Adversarial Network (GAN) based novel progressive Face Hallucination (FH) network to address these issues present among current methods. The generator of the proposed model comprises of FH network and two sub-networks, assisting FH network to generate high resolution images. The first sub-network leverages on explicitly adding high frequency components into the model. To explicitly encode the high frequency components, an auto encoder is proposed to generate high resolution coefficients of Discrete Cosine Transform (DCT). To add three dimensional parametric information into the network, second sub-network is proposed. This network uses a shape model of 3D Morphable Models (3DMM) to add structural constraint to the FH network. Extensive experimentation results in the paper shows that the proposed model outperforms the state-of-the-art methods.
A complete character recognition and transliteration technique for Devanagari script
Sep 28, 2020
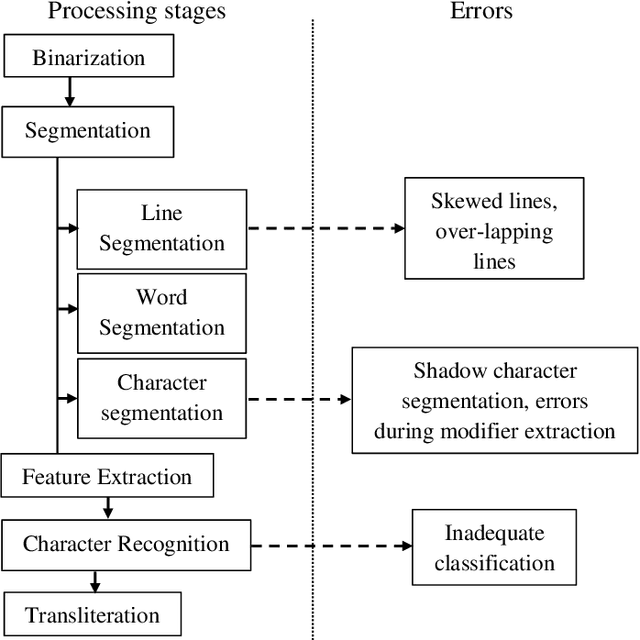


Transliteration involves transformation of one script to another based on phonetic similarities between the characters of two distinctive scripts. In this paper, we present a novel technique for automatic transliteration of Devanagari script using character recognition. One of the first tasks performed to isolate the constituent characters is segmentation. Line segmentation methodology in this manuscript discusses the case of overlapping lines. Character segmentation algorithm is designed to segment conjuncts and separate shadow characters. Presented shadow character segmentation scheme employs connected component method to isolate the character, keeping the constituent characters intact. Statistical features namely different order moments like area, variance, skewness and kurtosis along with structural features of characters are employed in two phase recognition process. After recognition, constituent Devanagari characters are mapped to corresponding roman alphabets in way that resulting roman alphabets have similar pronunciation to source characters.
No reference image quality assessment metric based on regional mutual information among images
Jan 17, 2019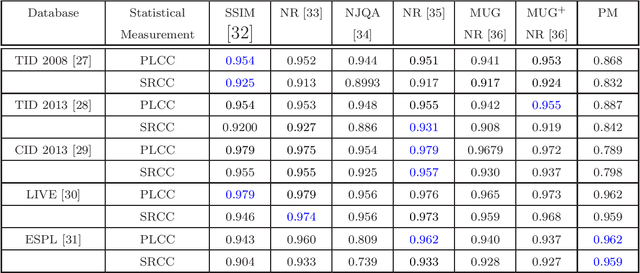
With the inclusion of camera in daily life, an automatic no reference image quality evaluation index is required for automatic classification of images. The present manuscripts proposes a new No Reference Regional Mutual Information based technique for evaluating the quality of an image. We use regional mutual information on subsets of the complete image. Proposed technique is tested on four benchmark natural image databases, and one benchmark synthetic database. A comparative analysis with classical and state-of-art methods indicate superiority of the present technique for high quality images and comparable for other images of the respective databases.
A Software-equivalent SNN Hardware using RRAM-array for Asynchronous Real-time Learning
Apr 06, 2017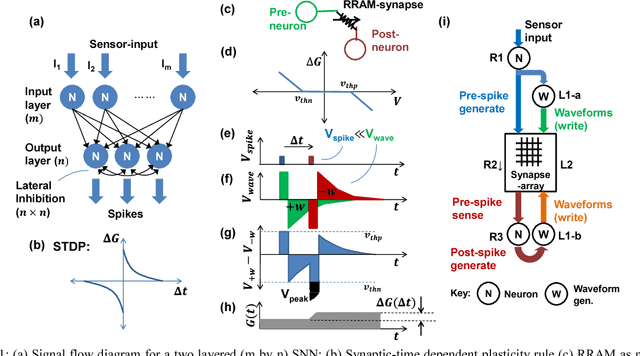
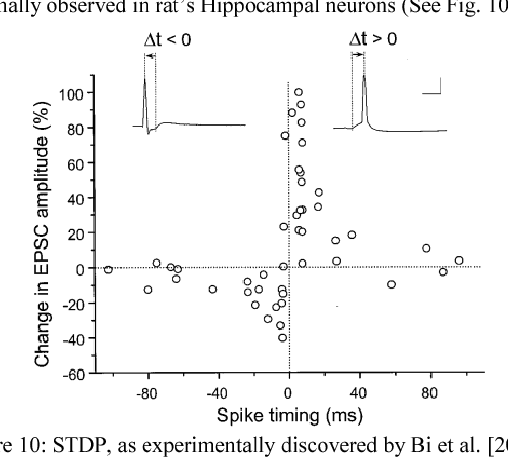
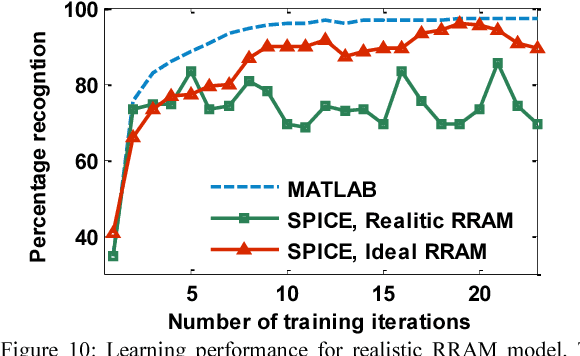
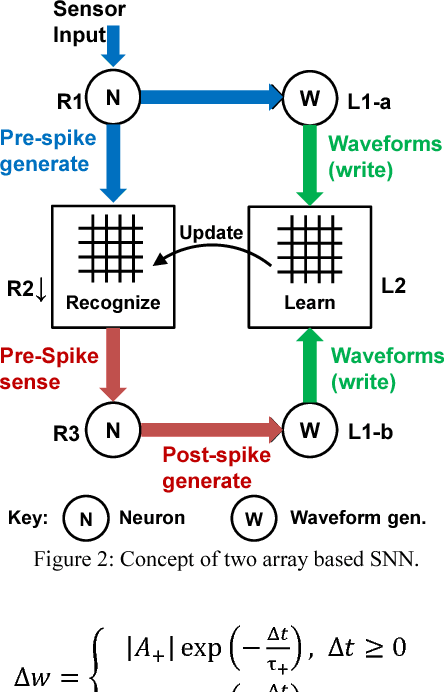
Spiking Neural Network (SNN) naturally inspires hardware implementation as it is based on biology. For learning, spike time dependent plasticity (STDP) may be implemented using an energy efficient waveform superposition on memristor based synapse. However, system level implementation has three challenges. First, a classic dilemma is that recognition requires current reading for short voltage$-$spikes which is disturbed by large voltage$-$waveforms that are simultaneously applied on the same memristor for real$-$time learning i.e. the simultaneous read$-$write dilemma. Second, the hardware needs to exactly replicate software implementation for easy adaptation of algorithm to hardware. Third, the devices used in hardware simulations must be realistic. In this paper, we present an approach to address the above concerns. First, the learning and recognition occurs in separate arrays simultaneously in real$-$time, asynchronously $-$ avoiding non$-$biomimetic clocking based complex signal management. Second, we show that the hardware emulates software at every stage by comparison of SPICE (circuit$-$simulator) with MATLAB (mathematical SNN algorithm implementation in software) implementations. As an example, the hardware shows 97.5 per cent accuracy in classification which is equivalent to software for a Fisher$-$Iris dataset. Third, the STDP is implemented using a model of synaptic device implemented using HfO2 memristor. We show that an increasingly realistic memristor model slightly reduces the hardware performance (85 per cent), which highlights the need to engineer RRAM characteristics specifically for SNN.
Anisotropic Diffusion for Details Enhancement in Multi-Exposure Image Fusion
Jul 10, 2013
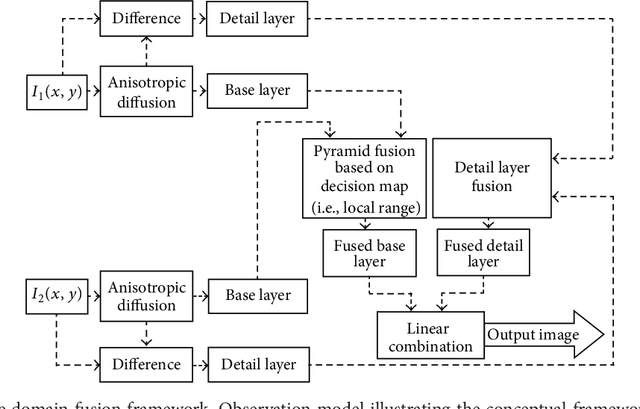
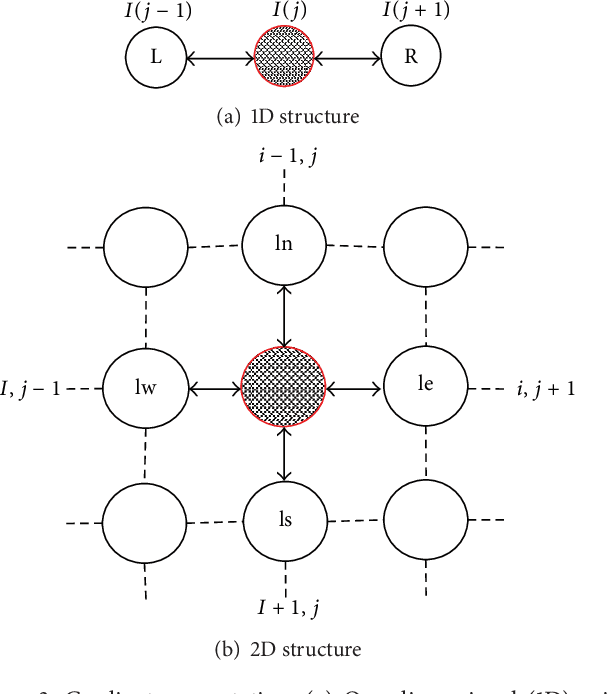
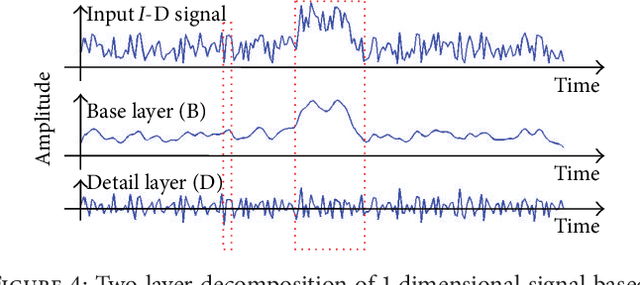
We develop a multiexposure image fusion method based on texture features, which exploits the edge preserving and intraregion smoothing property of nonlinear diffusion filters based on partial differential equations (PDE). With the captured multiexposure image series, we first decompose images into base layers and detail layers to extract sharp details and fine details, respectively. The magnitude of the gradient of the image intensity is utilized to encourage smoothness at homogeneous regions in preference to inhomogeneous regions. Then, we have considered texture features of the base layer to generate a mask (i.e., decision mask) that guides the fusion of base layers in multiresolution fashion. Finally, well-exposed fused image is obtained that combines fused base layer and the detail layers at each scale across all the input exposures. Proposed algorithm skipping complex High Dynamic Range Image (HDRI) generation and tone mapping steps to produce detail preserving image for display on standard dynamic range display devices. Moreover, our technique is effective for blending flash/no-flash image pair and multifocus images, that is, images focused on different targets.
* 30 pages