 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy optimized semi-supervised decomposed vector-quantized variational autoencoder model based on transfer learning for multiclass text classification and generation
Nov 10, 2021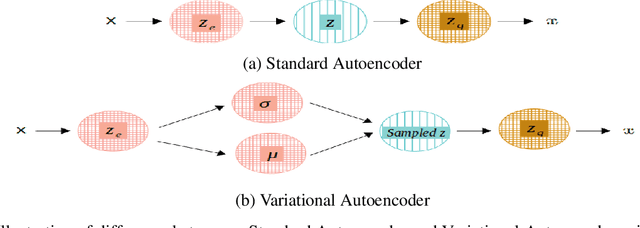

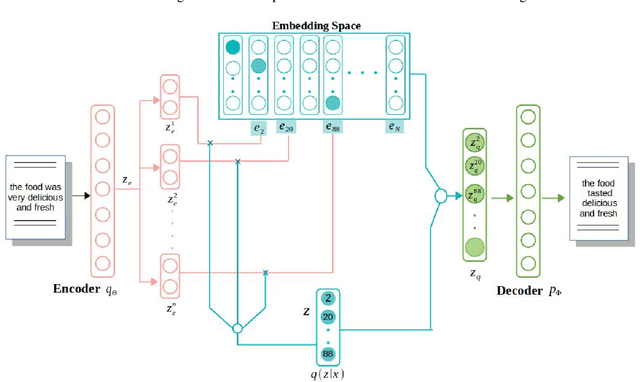

Semisupervised text classification has become a major focus of research over the past few years. Hitherto, most of the research has been based on supervised learning, but its main drawback is the unavailability of labeled data samples in practical applications. It is still a key challenge to train the deep generative models and learn comprehensive representations without supervision. Even though continuous latent variables are employed primarily in deep latent variable models, discrete latent variables, with their enhanced understandability and better compressed representations, are effectively used by researchers. In this paper, we propose a semisupervised discrete latent variable model for multi-class text classification and text generation. The proposed model employs the concept of transfer learning for training a quantized transformer model, which is able to learn competently using fewer labeled instances. The model applies decomposed vector quantization technique to overcome problems like posterior collapse and index collapse. Shannon entropy is used for the decomposed sub-encoders, on which a variable DropConnect is applied, to retain maximum information. Moreover, gradients of the Loss function are adaptively modified during backpropagation from decoder to encoder to enhance the performance of the model. Three conventional datasets of diversified range have been used for validating the proposed model on a variable number of labeled instances. Experimental results indicate that the proposed model has surpassed the state-of-the-art models remarkably.