 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA complete character recognition and transliteration technique for Devanagari script
Sep 28, 2020
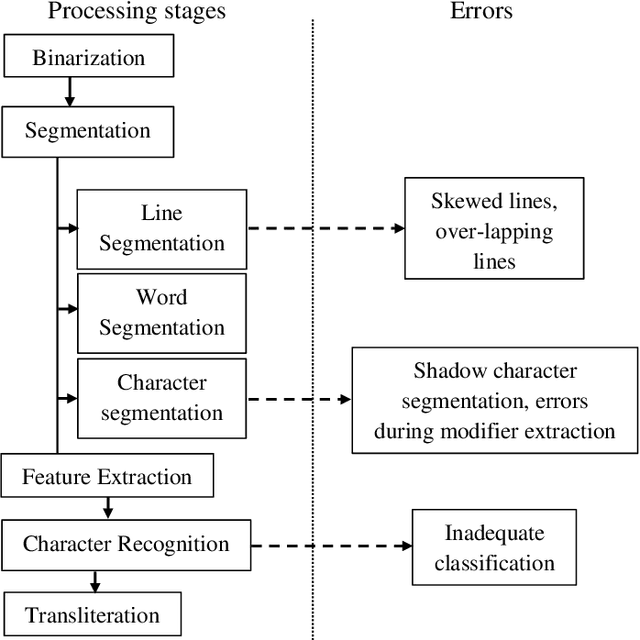


Transliteration involves transformation of one script to another based on phonetic similarities between the characters of two distinctive scripts. In this paper, we present a novel technique for automatic transliteration of Devanagari script using character recognition. One of the first tasks performed to isolate the constituent characters is segmentation. Line segmentation methodology in this manuscript discusses the case of overlapping lines. Character segmentation algorithm is designed to segment conjuncts and separate shadow characters. Presented shadow character segmentation scheme employs connected component method to isolate the character, keeping the constituent characters intact. Statistical features namely different order moments like area, variance, skewness and kurtosis along with structural features of characters are employed in two phase recognition process. After recognition, constituent Devanagari characters are mapped to corresponding roman alphabets in way that resulting roman alphabets have similar pronunciation to source characters.