 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature boosting with efficient attention for scene parsing
Feb 29, 2024The complexity of scene parsing grows with the number of object and scene classes, which is higher in unrestricted open scenes. The biggest challenge is to model the spatial relation between scene elements while succeeding in identifying objects at smaller scales. This paper presents a novel feature-boosting network that gathers spatial context from multiple levels of feature extraction and computes the attention weights for each level of representation to generate the final class labels. A novel `channel attention module' is designed to compute the attention weights, ensuring that features from the relevant extraction stages are boosted while the others are attenuated. The model also learns spatial context information at low resolution to preserve the abstract spatial relationships among scene elements and reduce computation cost. Spatial attention is subsequently concatenated into a final feature set before applying feature boosting. Low-resolution spatial attention features are trained using an auxiliary task that helps learning a coarse global scene structure. The proposed model outperforms all state-of-the-art models on both the ADE20K and the Cityscapes datasets.
Audio-visual video face hallucination with frequency supervision and cross modality support by speech based lip reading loss
Nov 20, 2022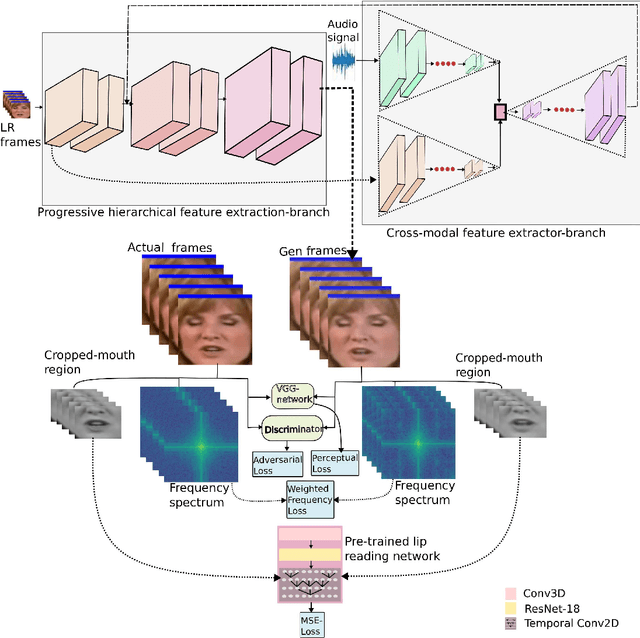
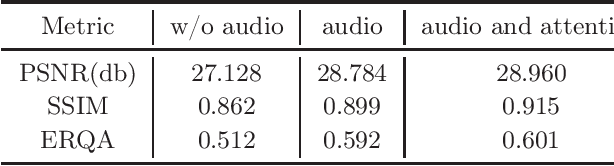


Recently, there has been numerous breakthroughs in face hallucination tasks. However, the task remains rather challenging in videos in comparison to the images due to inherent consistency issues. The presence of extra temporal dimension in video face hallucination makes it non-trivial to learn the facial motion through out the sequence. In order to learn these fine spatio-temporal motion details, we propose a novel cross-modal audio-visual Video Face Hallucination Generative Adversarial Network (VFH-GAN). The architecture exploits the semantic correlation of between the movement of the facial structure and the associated speech signal. Another major issue in present video based approaches is the presence of blurriness around the key facial regions such as mouth and lips - where spatial displacement is much higher in comparison to other areas. The proposed approach explicitly defines a lip reading loss to learn the fine grain motion in these facial areas. During training, GANs have potential to fit frequencies from low to high, which leads to miss the hard to synthesize frequencies. Therefore, to add salient frequency features to the network we add a frequency based loss function. The visual and the quantitative comparison with state-of-the-art shows a significant improvement in performance and efficacy.
Frequency Aware Face Hallucination Generative Adversarial Network with Semantic Structural Constraint
Oct 05, 2021



In this paper, we address the issue of face hallucination. Most current face hallucination methods rely on two-dimensional facial priors to generate high resolution face images from low resolution face images. These methods are only capable of assimilating global information into the generated image. Still there exist some inherent problems in these methods; such as, local features, subtle structural details and missing depth information in final output image. Present work proposes a Generative Adversarial Network (GAN) based novel progressive Face Hallucination (FH) network to address these issues present among current methods. The generator of the proposed model comprises of FH network and two sub-networks, assisting FH network to generate high resolution images. The first sub-network leverages on explicitly adding high frequency components into the model. To explicitly encode the high frequency components, an auto encoder is proposed to generate high resolution coefficients of Discrete Cosine Transform (DCT). To add three dimensional parametric information into the network, second sub-network is proposed. This network uses a shape model of 3D Morphable Models (3DMM) to add structural constraint to the FH network. Extensive experimentation results in the paper shows that the proposed model outperforms the state-of-the-art methods.