 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-visual video face hallucination with frequency supervision and cross modality support by speech based lip reading loss
Paper and Code
Nov 20, 2022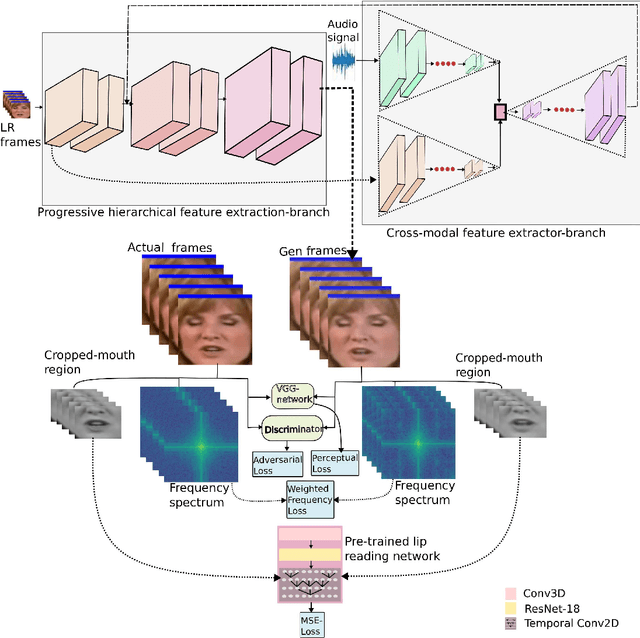
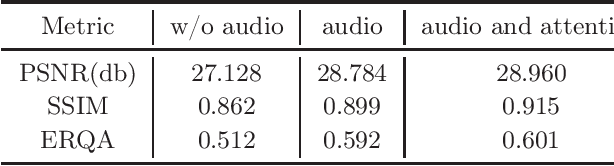


Recently, there has been numerous breakthroughs in face hallucination tasks. However, the task remains rather challenging in videos in comparison to the images due to inherent consistency issues. The presence of extra temporal dimension in video face hallucination makes it non-trivial to learn the facial motion through out the sequence. In order to learn these fine spatio-temporal motion details, we propose a novel cross-modal audio-visual Video Face Hallucination Generative Adversarial Network (VFH-GAN). The architecture exploits the semantic correlation of between the movement of the facial structure and the associated speech signal. Another major issue in present video based approaches is the presence of blurriness around the key facial regions such as mouth and lips - where spatial displacement is much higher in comparison to other areas. The proposed approach explicitly defines a lip reading loss to learn the fine grain motion in these facial areas. During training, GANs have potential to fit frequencies from low to high, which leads to miss the hard to synthesize frequencies. Therefore, to add salient frequency features to the network we add a frequency based loss function. The visual and the quantitative comparison with state-of-the-art shows a significant improvement in performance and efficacy.