 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNGAME: Negative Mining-aware Mini-batching for Extreme Classification
Jul 10, 2022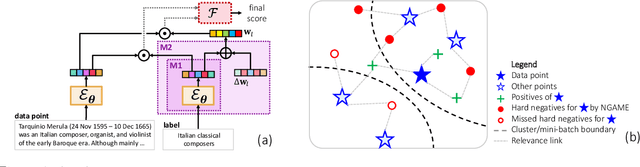
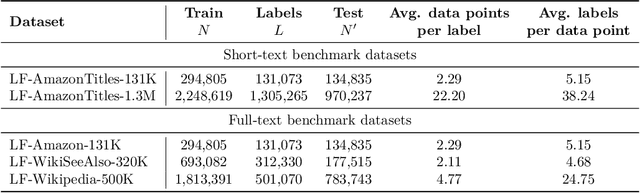
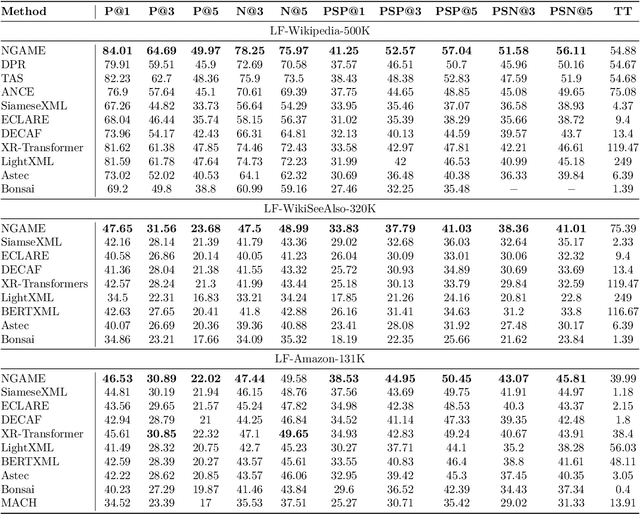
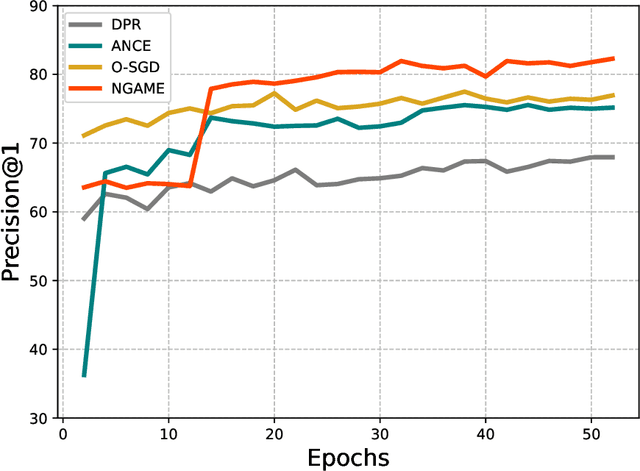
Extreme Classification (XC) seeks to tag data points with the most relevant subset of labels from an extremely large label set. Performing deep XC with dense, learnt representations for data points and labels has attracted much attention due to its superiority over earlier XC methods that used sparse, hand-crafted features. Negative mining techniques have emerged as a critical component of all deep XC methods that allow them to scale to millions of labels. However, despite recent advances, training deep XC models with large encoder architectures such as transformers remains challenging. This paper identifies that memory overheads of popular negative mining techniques often force mini-batch sizes to remain small and slow training down. In response, this paper introduces NGAME, a light-weight mini-batch creation technique that offers provably accurate in-batch negative samples. This allows training with larger mini-batches offering significantly faster convergence and higher accuracies than existing negative sampling techniques. NGAME was found to be up to 16% more accurate than state-of-the-art methods on a wide array of benchmark datasets for extreme classification, as well as 3% more accurate at retrieving search engine queries in response to a user webpage visit to show personalized ads. In live A/B tests on a popular search engine, NGAME yielded up to 23% gains in click-through-rates.
HyperTeNet: Hypergraph and Transformer-based Neural Network for Personalized List Continuation
Oct 07, 2021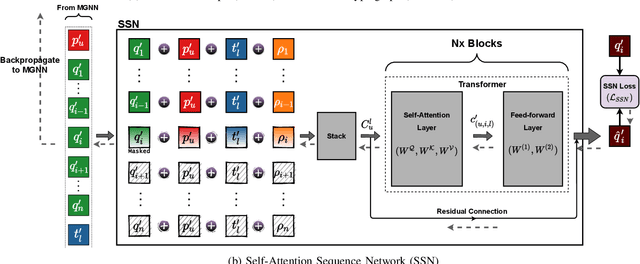
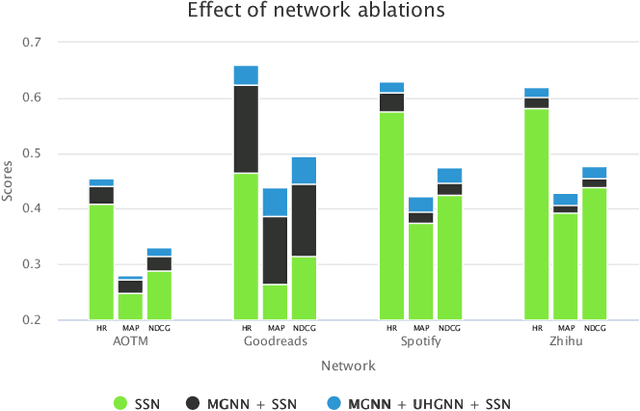
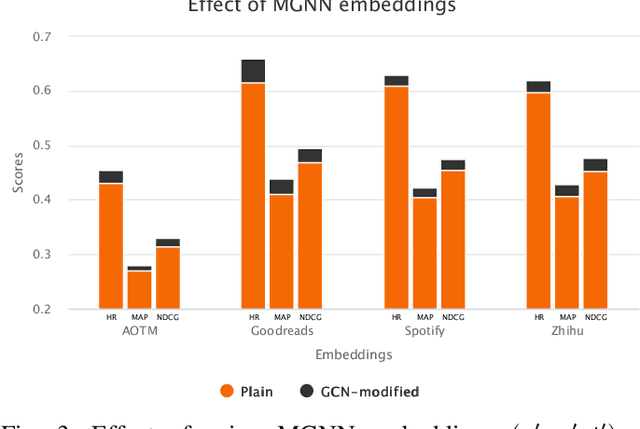
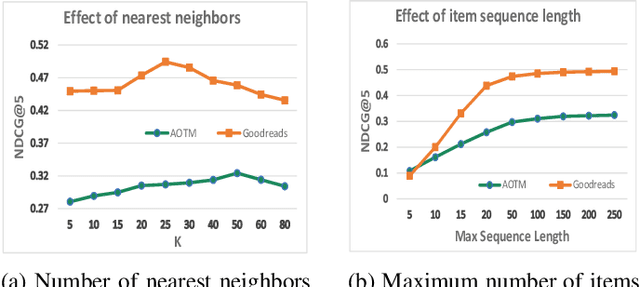
The personalized list continuation (PLC) task is to curate the next items to user-generated lists (ordered sequence of items) in a personalized way. The main challenge in this task is understanding the ternary relationships among the interacting entities (users, items, and lists) that the existing works do not consider. Further, they do not take into account the multi-hop relationships among entities of the same type. In addition, capturing the sequential information amongst the items already present in the list also plays a vital role in determining the next relevant items that get curated. In this work, we propose HyperTeNet -- a self-attention hypergraph and Transformer-based neural network architecture for the personalized list continuation task to address the challenges mentioned above. We use graph convolutions to learn the multi-hop relationship among the entities of the same type and leverage a self-attention-based hypergraph neural network to learn the ternary relationships among the interacting entities via hyperlink prediction in a 3-uniform hypergraph. Further, the entity embeddings are shared with a Transformer-based architecture and are learned through an alternating optimization procedure. As a result, this network also learns the sequential information needed to curate the next items to be added to the list. Experimental results demonstrate that HyperTeNet significantly outperforms the other state-of-the-art models on real-world datasets. Our implementation and datasets are available at https://github.com/mvijaikumar/HyperTeNet.