 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Quantization of Mixture-of-Experts with Theoretical Generalization Guarantees
Apr 07, 2026Sparse Mixture-of-Experts (MoE) allows scaling of language and vision models efficiently by activating only a small subset of experts per input. While this reduces computation, the large number of parameters still incurs substantial memory overhead during inference. Post-training quantization has been explored to address this issue. Because uniform quantization suffers from significant accuracy loss at low bit-widths, mixed-precision methods have been recently explored; however, they often require substantial computation for bit-width allocation and overlook the varying sensitivity of model performance to the quantization of different experts. We propose a theoretically grounded expert-wise mixed precision strategy that assigns bit-width to each expert primarily based on their change in routers l2 norm during training. Experts with smaller changes are shown to capture less frequent but critical features, and model performance is more sensitive to the quantization of these experts, thus requiring higher precision. Furthermore, to avoid allocating experts to lower precision that inject high quantization noise, experts with large maximum intra-neuron variance are also allocated higher precision. Experiments on large-scale MoE models, including Switch Transformer and Mixtral, show that our method achieves higher accuracy than existing approaches, while also reducing inference cost and incurring only negligible overhead for bit-width assignment.
CODMAS: A Dialectic Multi-Agent Collaborative Framework for Structured RTL Optimization
Mar 17, 2026Optimizing Register Transfer Level (RTL) code is a critical step in Electronic Design Automation (EDA) for improving power, performance, and area (PPA). We present CODMAS (Collaborative Optimization via a Dialectic Multi-Agent System), a framework that combines structured dialectic reasoning with domain-aware code generation and deterministic evaluation to automate RTL optimization. At the core of CODMAS are two dialectic agents: the Articulator, inspired by rubber-duck debugging, which articulates stepwise transformation plans and exposes latent assumptions; and the Hypothesis Partner, which predicts outcomes and reconciles deviations between expected and actual behavior to guide targeted refinements. These agents direct a Domain-Specific Coding Agent (DCA) to generate architecture-aware Verilog edits and a Code Evaluation Agent (CEA) to verify syntax, functionality, and PPA metrics. We introduce RTLOPT, a benchmark of 120 Verilog triples (unoptimized, optimized, testbench) for pipelining and clock-gating transformations. Across proprietary and open LLMs, CODMAS achieves ~25% reduction in critical path delay for pipelining and ~22% power reduction for clock gating, while reducing functional and compilation failures compared to strong prompting and agentic baselines. These results demonstrate that structured multi-agent reasoning can significantly enhance automated RTL optimization and scale to more complex designs and broader optimization tasks.
Robust Heterogeneous Analog-Digital Computing for Mixture-of-Experts Models with Theoretical Generalization Guarantees
Mar 03, 2026Sparse Mixture-of-Experts (MoE) models enable efficient scalability by activating only a small sub-set of experts per input, yet their massive parameter counts lead to substantial memory and energy inefficiency during inference. Analog in-memory computing (AIMC) offers a promising solution by eliminating frequent data movement between memory and compute units. However, mitigating hardware nonidealities of AIMC typically requires noise-aware retraining, which is infeasible for large MoE models. In this paper, we propose a retraining-free heterogeneous computation framework in which noise-sensitive experts, which are provably identifiable by their maximum neuron norm, are computed digitally while the majority of the experts are executed on AIMC hardware. We further assign densely activated modules, such as attention layers, to digital computation due to their high noise sensitivity despite comprising a small fraction of parameters. Extensive experiments on large MoE language models, including DeepSeekMoE and OLMoE, across multiple benchmark tasks validate the robustness of our approach in maintaining accuracy under analog nonidealities.
Pipeline Gradient-based Model Training on Analog In-memory Accelerators
Oct 19, 2024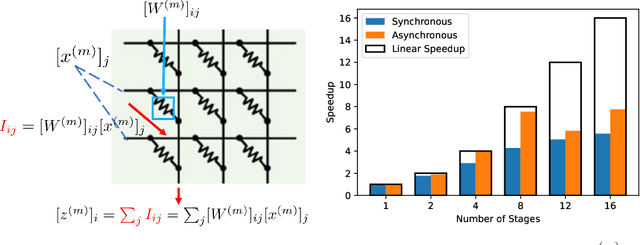

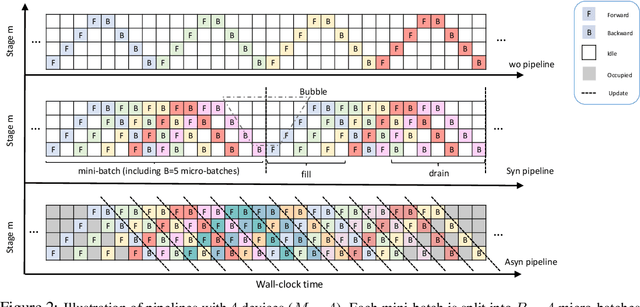
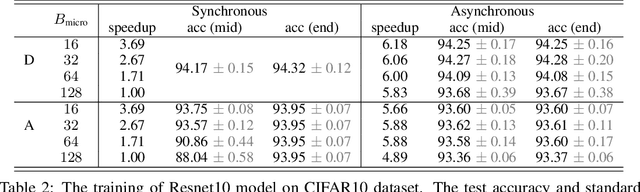
Aiming to accelerate the training of large deep neural models (DNN) in an energy-efficient way, an analog in-memory computing (AIMC) accelerator emerges as a solution with immense potential. In AIMC accelerators, trainable weights are kept in memory without the need to move from memory to processors during the training, reducing a bunch of overhead. However, although the in-memory feature enables efficient computation, it also constrains the use of data parallelism since copying weights from one AIMC to another is expensive. To enable parallel training using AIMC, we propose synchronous and asynchronous pipeline parallelism for AIMC accelerators inspired by the pipeline in digital domains. This paper provides a theoretical convergence guarantee for both synchronous and asynchronous pipelines in terms of both sampling and clock cycle complexity, which is non-trivial since the physical characteristic of AIMC accelerators leads to analog updates that suffer from asymmetric bias. The simulations of training DNN on real datasets verify the efficiency of pipeline training.
Using the IBM Analog In-Memory Hardware Acceleration Kit for Neural Network Training and Inference
Jul 18, 2023

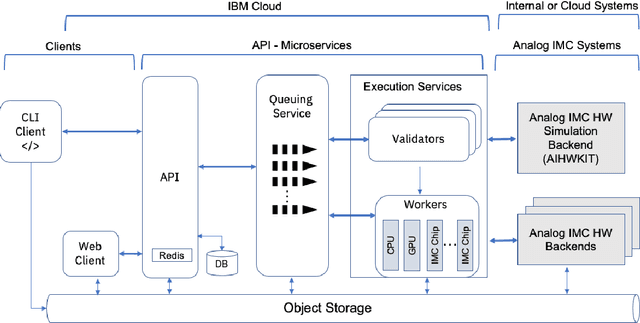

Analog In-Memory Computing (AIMC) is a promising approach to reduce the latency and energy consumption of Deep Neural Network (DNN) inference and training. However, the noisy and non-linear device characteristics, and the non-ideal peripheral circuitry in AIMC chips, require adapting DNNs to be deployed on such hardware to achieve equivalent accuracy to digital computing. In this tutorial, we provide a deep dive into how such adaptations can be achieved and evaluated using the recently released IBM Analog Hardware Acceleration Kit (AIHWKit), freely available at https://github.com/IBM/aihwkit. The AIHWKit is a Python library that simulates inference and training of DNNs using AIMC. We present an in-depth description of the AIHWKit design, functionality, and best practices to properly perform inference and training. We also present an overview of the Analog AI Cloud Composer, that provides the benefits of using the AIHWKit simulation platform in a fully managed cloud setting. Finally, we show examples on how users can expand and customize AIHWKit for their own needs. This tutorial is accompanied by comprehensive Jupyter Notebook code examples that can be run using AIHWKit, which can be downloaded from https://github.com/IBM/aihwkit/tree/master/notebooks/tutorial.
AnalogNAS: A Neural Network Design Framework for Accurate Inference with Analog In-Memory Computing
May 17, 2023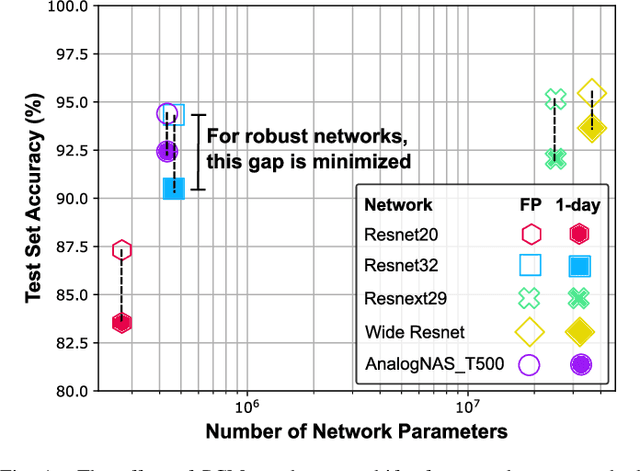
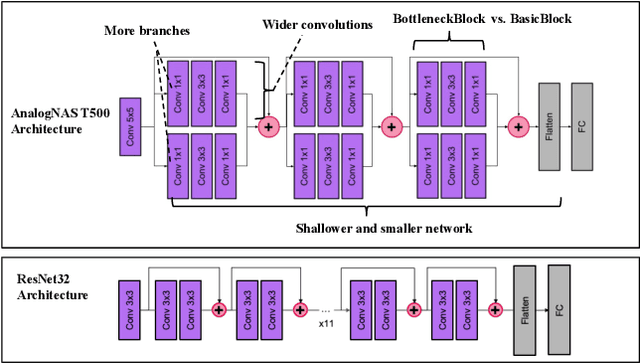
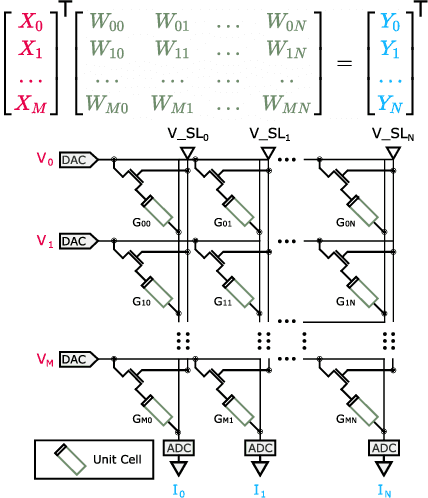
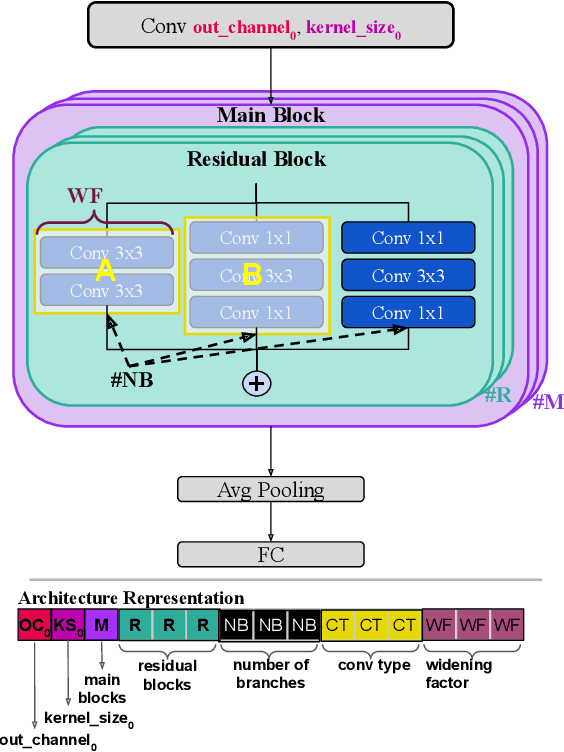
The advancement of Deep Learning (DL) is driven by efficient Deep Neural Network (DNN) design and new hardware accelerators. Current DNN design is primarily tailored for general-purpose use and deployment on commercially viable platforms. Inference at the edge requires low latency, compact and power-efficient models, and must be cost-effective. Digital processors based on typical von Neumann architectures are not conducive to edge AI given the large amounts of required data movement in and out of memory. Conversely, analog/mixed signal in-memory computing hardware accelerators can easily transcend the memory wall of von Neuman architectures when accelerating inference workloads. They offer increased area and power efficiency, which are paramount in edge resource-constrained environments. In this paper, we propose AnalogNAS, a framework for automated DNN design targeting deployment on analog In-Memory Computing (IMC) inference accelerators. We conduct extensive hardware simulations to demonstrate the performance of AnalogNAS on State-Of-The-Art (SOTA) models in terms of accuracy and deployment efficiency on various Tiny Machine Learning (TinyML) tasks. We also present experimental results that show AnalogNAS models achieving higher accuracy than SOTA models when implemented on a 64-core IMC chip based on Phase Change Memory (PCM). The AnalogNAS search code is released: https://github.com/IBM/analog-nas
Hardware-aware training for large-scale and diverse deep learning inference workloads using in-memory computing-based accelerators
Feb 16, 2023Analog in-memory computing (AIMC) -- a promising approach for energy-efficient acceleration of deep learning workloads -- computes matrix-vector multiplications (MVMs) but only approximately, due to nonidealities that often are non-deterministic or nonlinear. This can adversely impact the achievable deep neural network (DNN) inference accuracy as compared to a conventional floating point (FP) implementation. While retraining has previously been suggested to improve robustness, prior work has explored only a few DNN topologies, using disparate and overly simplified AIMC hardware models. Here, we use hardware-aware (HWA) training to systematically examine the accuracy of AIMC for multiple common artificial intelligence (AI) workloads across multiple DNN topologies, and investigate sensitivity and robustness to a broad set of nonidealities. By introducing a new and highly realistic AIMC crossbar-model, we improve significantly on earlier retraining approaches. We show that many large-scale DNNs of various topologies, including convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformers, can in fact be successfully retrained to show iso-accuracy on AIMC. Our results further suggest that AIMC nonidealities that add noise to the inputs or outputs, not the weights, have the largest impact on DNN accuracy, and that RNNs are particularly robust to all nonidealities.