 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Finer Better? The Limits of Microscaling Formats in Large Language Models
Jan 26, 2026Microscaling data formats leverage per-block tensor quantization to enable aggressive model compression with limited loss in accuracy. Unlocking their potential for efficient training and inference necessitates hardware-friendly implementations that handle matrix multiplications in a native format and adopt efficient error-mitigation strategies. Herein, we report the emergence of a surprising behavior associated with microscaling quantization, whereas the output of a quantized model degrades as block size is decreased below a given threshold. This behavior clashes with the expectation that a smaller block size should allow for a better representation of the tensor elements. We investigate this phenomenon both experimentally and theoretically, decoupling the sources of quantization error behind it. Experimentally, we analyze the distributions of several Large Language Models and identify the conditions driving the anomalous behavior. Theoretically, we lay down a framework showing remarkable agreement with experimental data from pretrained model distributions and ideal ones. Overall, we show that the anomaly is driven by the interplay between narrow tensor distributions and the limited dynamic range of the quantized scales. Based on these insights, we propose the use of FP8 unsigned E5M3 (UE5M3) as a novel hardware-friendly format for the scales in FP4 microscaling data types. We demonstrate that UE5M3 achieves comparable performance to the conventional FP8 unsigned E4M3 scales while obviating the need of global scaling operations on weights and activations.
Hardware-aware training for large-scale and diverse deep learning inference workloads using in-memory computing-based accelerators
Feb 16, 2023Analog in-memory computing (AIMC) -- a promising approach for energy-efficient acceleration of deep learning workloads -- computes matrix-vector multiplications (MVMs) but only approximately, due to nonidealities that often are non-deterministic or nonlinear. This can adversely impact the achievable deep neural network (DNN) inference accuracy as compared to a conventional floating point (FP) implementation. While retraining has previously been suggested to improve robustness, prior work has explored only a few DNN topologies, using disparate and overly simplified AIMC hardware models. Here, we use hardware-aware (HWA) training to systematically examine the accuracy of AIMC for multiple common artificial intelligence (AI) workloads across multiple DNN topologies, and investigate sensitivity and robustness to a broad set of nonidealities. By introducing a new and highly realistic AIMC crossbar-model, we improve significantly on earlier retraining approaches. We show that many large-scale DNNs of various topologies, including convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformers, can in fact be successfully retrained to show iso-accuracy on AIMC. Our results further suggest that AIMC nonidealities that add noise to the inputs or outputs, not the weights, have the largest impact on DNN accuracy, and that RNNs are particularly robust to all nonidealities.
Accelerating Inference and Language Model Fusion of Recurrent Neural Network Transducers via End-to-End 4-bit Quantization
Jun 16, 2022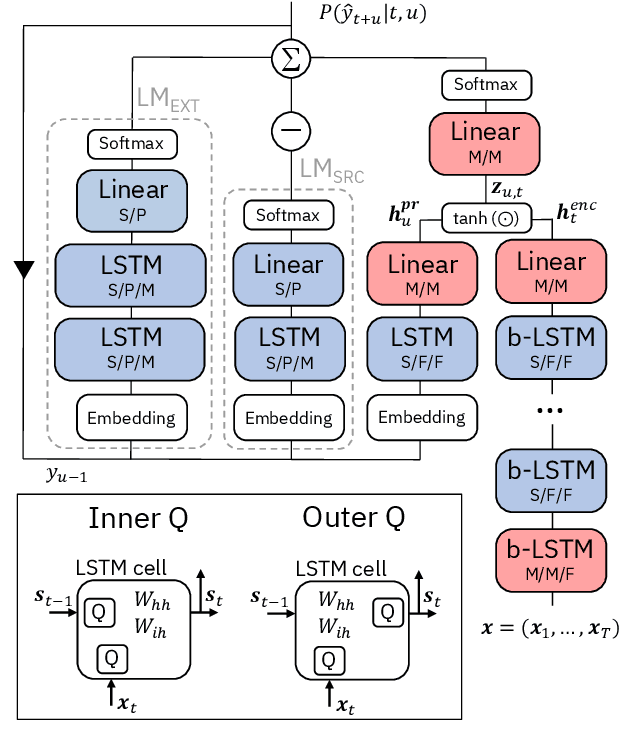
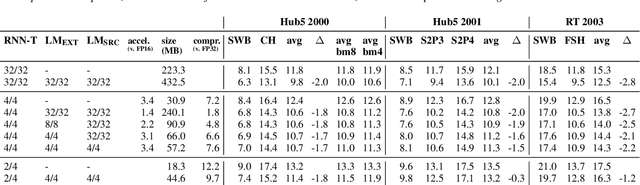
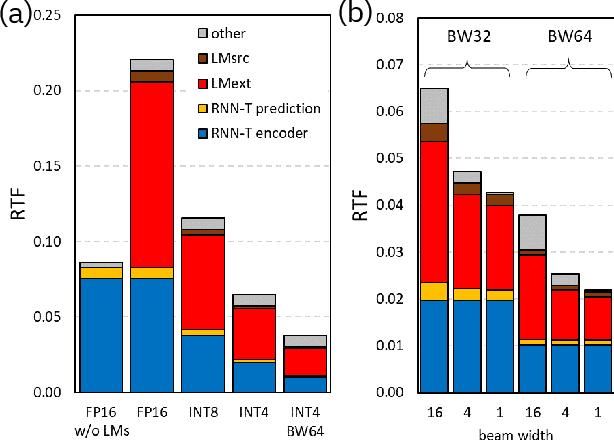
We report on aggressive quantization strategies that greatly accelerate inference of Recurrent Neural Network Transducers (RNN-T). We use a 4 bit integer representation for both weights and activations and apply Quantization Aware Training (QAT) to retrain the full model (acoustic encoder and language model) and achieve near-iso-accuracy. We show that customized quantization schemes that are tailored to the local properties of the network are essential to achieve good performance while limiting the computational overhead of QAT. Density ratio Language Model fusion has shown remarkable accuracy gains on RNN-T workloads but it severely increases the computational cost of inference. We show that our quantization strategies enable using large beam widths for hypothesis search while achieving streaming-compatible runtimes and a full model compression ratio of 7.6$\times$ compared to the full precision model. Via hardware simulations, we estimate a 3.4$\times$ acceleration from FP16 to INT4 for the end-to-end quantized RNN-T inclusive of LM fusion, resulting in a Real Time Factor (RTF) of 0.06. On the NIST Hub5 2000, Hub5 2001, and RT-03 test sets, we retain most of the gains associated with LM fusion, improving the average WER by $>$1.5%.
4-bit Quantization of LSTM-based Speech Recognition Models
Aug 27, 2021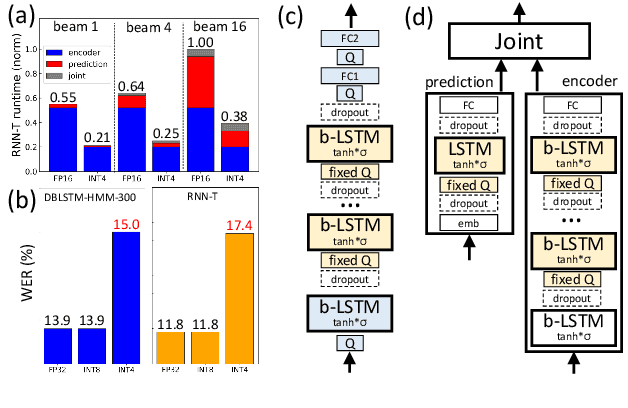
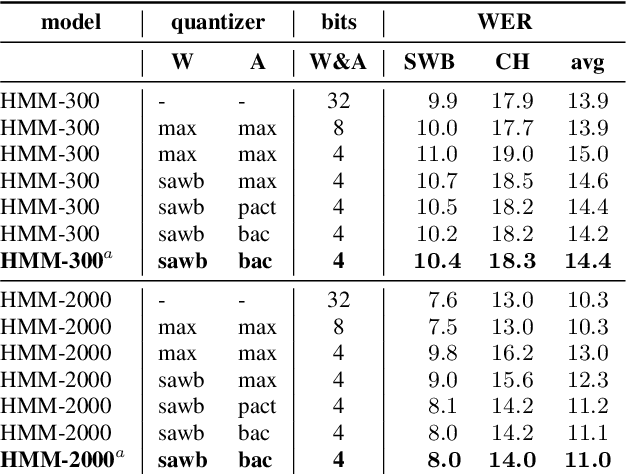
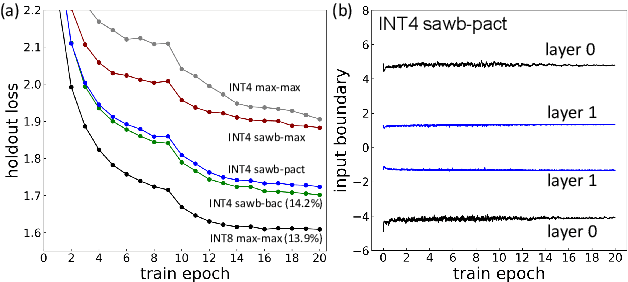
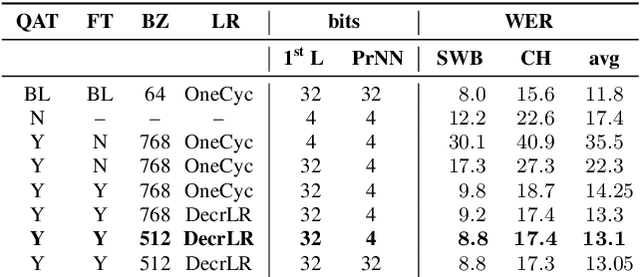
We investigate the impact of aggressive low-precision representations of weights and activations in two families of large LSTM-based architectures for Automatic Speech Recognition (ASR): hybrid Deep Bidirectional LSTM - Hidden Markov Models (DBLSTM-HMMs) and Recurrent Neural Network - Transducers (RNN-Ts). Using a 4-bit integer representation, a na\"ive quantization approach applied to the LSTM portion of these models results in significant Word Error Rate (WER) degradation. On the other hand, we show that minimal accuracy loss is achievable with an appropriate choice of quantizers and initializations. In particular, we customize quantization schemes depending on the local properties of the network, improving recognition performance while limiting computational time. We demonstrate our solution on the Switchboard (SWB) and CallHome (CH) test sets of the NIST Hub5-2000 evaluation. DBLSTM-HMMs trained with 300 or 2000 hours of SWB data achieves $<$0.5% and $<$1% average WER degradation, respectively. On the more challenging RNN-T models, our quantization strategy limits degradation in 4-bit inference to 1.3%.