 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Inference and Language Model Fusion of Recurrent Neural Network Transducers via End-to-End 4-bit Quantization
Paper and Code
Jun 16, 2022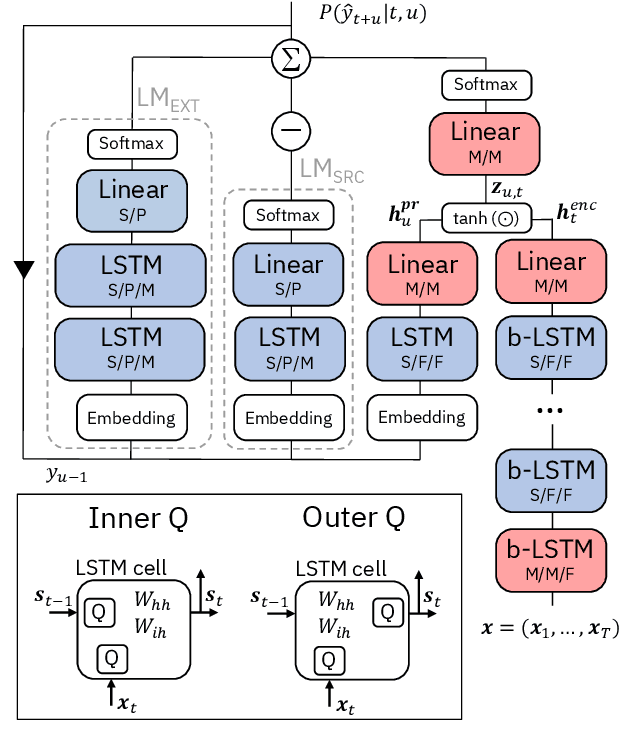
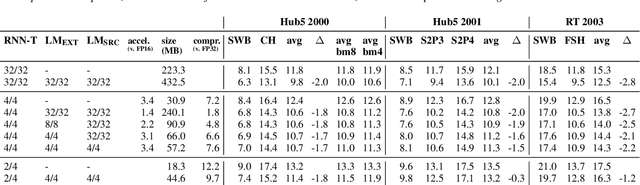
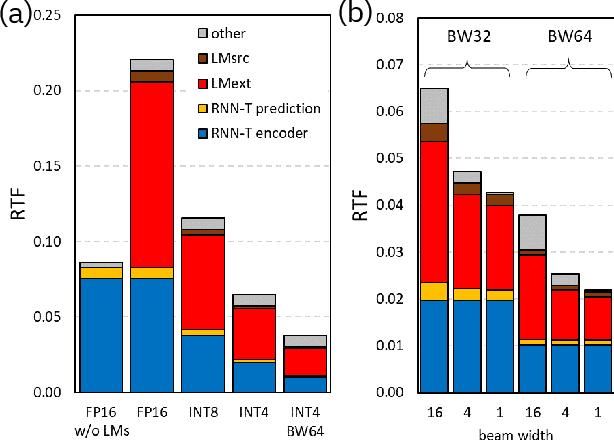
We report on aggressive quantization strategies that greatly accelerate inference of Recurrent Neural Network Transducers (RNN-T). We use a 4 bit integer representation for both weights and activations and apply Quantization Aware Training (QAT) to retrain the full model (acoustic encoder and language model) and achieve near-iso-accuracy. We show that customized quantization schemes that are tailored to the local properties of the network are essential to achieve good performance while limiting the computational overhead of QAT. Density ratio Language Model fusion has shown remarkable accuracy gains on RNN-T workloads but it severely increases the computational cost of inference. We show that our quantization strategies enable using large beam widths for hypothesis search while achieving streaming-compatible runtimes and a full model compression ratio of 7.6$\times$ compared to the full precision model. Via hardware simulations, we estimate a 3.4$\times$ acceleration from FP16 to INT4 for the end-to-end quantized RNN-T inclusive of LM fusion, resulting in a Real Time Factor (RTF) of 0.06. On the NIST Hub5 2000, Hub5 2001, and RT-03 test sets, we retain most of the gains associated with LM fusion, improving the average WER by $>$1.5%.