 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre training trajectories of deep single-spike and deep ReLU network equivalent?
Jun 14, 2023Communication by binary and sparse spikes is a key factor for the energy efficiency of biological brains. However, training deep spiking neural networks (SNNs) with backpropagation is harder than with artificial neural networks (ANNs), which is puzzling given that recent theoretical results provide exact mapping algorithms from ReLU to time-to-first-spike (TTFS) SNNs. Building upon these results, we analyze in theory and in simulation the learning dynamics of TTFS-SNNs. Our analysis highlights that even when an SNN can be mapped exactly to a ReLU network, it cannot always be robustly trained by gradient descent. The reason for that is the emergence of a specific instance of the vanishing-or-exploding gradient problem leading to a bias in the gradient descent trajectory in comparison with the equivalent ANN. After identifying this issue we derive a generic solution for the network initialization and SNN parameterization which guarantees that the SNN can be trained as robustly as its ANN counterpart. Our theoretical findings are illustrated in practice on image classification datasets. Our method achieves the same accuracy as deep ConvNets on CIFAR10 and enables fine-tuning on the much larger PLACES365 dataset without loss of accuracy compared to the ANN. We argue that the combined perspective of conversion and fine-tuning with robust gradient descent in SNN will be decisive to optimize SNNs for hardware implementations needing low latency and resilience to noise and quantization.
Factorizers for Distributed Sparse Block Codes
Mar 24, 2023



Distributed sparse block codes (SBCs) exhibit compact representations for encoding and manipulating symbolic data structures using fixed-with vectors. One major challenge however is to disentangle, or factorize, such data structures into their constituent elements without having to search through all possible combinations. This factorization becomes more challenging when queried by noisy SBCs wherein symbol representations are relaxed due to perceptual uncertainty and approximations made when modern neural networks are used to generate the query vectors. To address these challenges, we first propose a fast and highly accurate method for factorizing a more flexible and hence generalized form of SBCs, dubbed GSBCs. Our iterative factorizer introduces a threshold-based nonlinear activation, a conditional random sampling, and an $\ell_\infty$-based similarity metric. Its random sampling mechanism in combination with the search in superposition allows to analytically determine the expected number of decoding iterations, which matches the empirical observations up to the GSBC's bundling capacity. Secondly, the proposed factorizer maintains its high accuracy when queried by noisy product vectors generated using deep convolutional neural networks (CNNs). This facilitates its application in replacing the large fully connected layer (FCL) in CNNs, whereby C trainable class vectors, or attribute combinations, can be implicitly represented by our factorizer having F-factor codebooks, each with $\sqrt[\leftroot{-2}\uproot{2}F]{C}$ fixed codevectors. We provide a methodology to flexibly integrate our factorizer in the classification layer of CNNs with a novel loss function. We demonstrate the feasibility of our method on four deep CNN architectures over CIFAR-100, ImageNet-1K, and RAVEN datasets. In all use cases, the number of parameters and operations are significantly reduced compared to the FCL.
An Exact Mapping From ReLU Networks to Spiking Neural Networks
Dec 23, 2022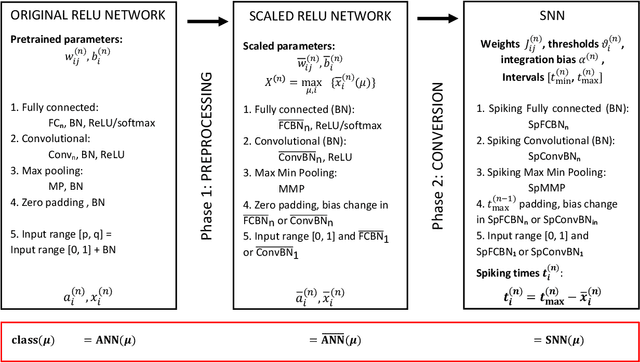
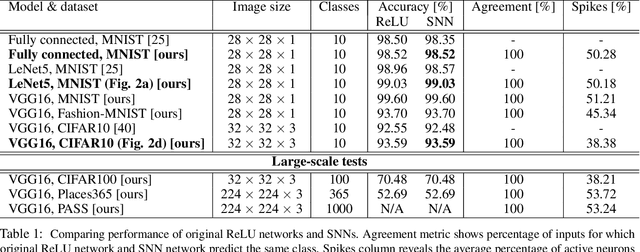
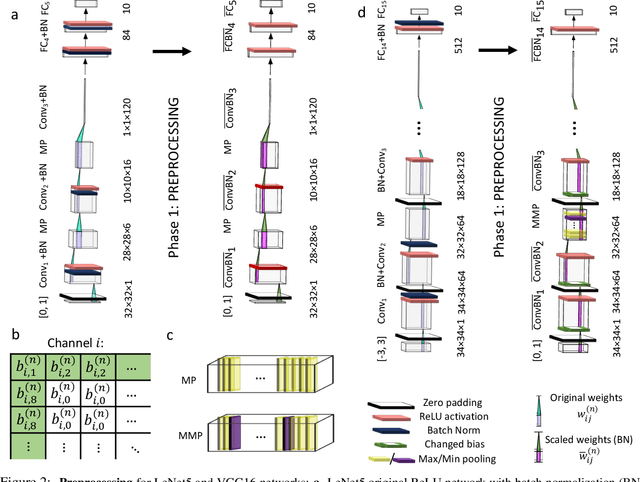
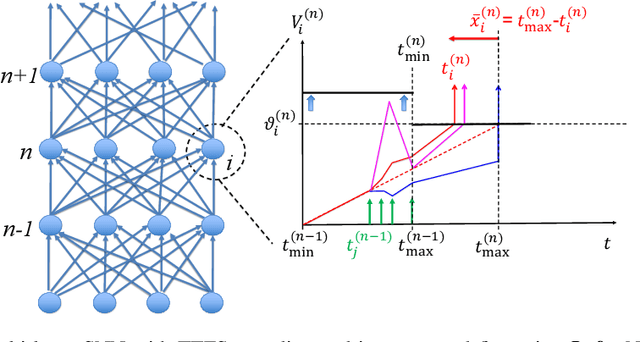
Deep spiking neural networks (SNNs) offer the promise of low-power artificial intelligence. However, training deep SNNs from scratch or converting deep artificial neural networks to SNNs without loss of performance has been a challenge. Here we propose an exact mapping from a network with Rectified Linear Units (ReLUs) to an SNN that fires exactly one spike per neuron. For our constructive proof, we assume that an arbitrary multi-layer ReLU network with or without convolutional layers, batch normalization and max pooling layers was trained to high performance on some training set. Furthermore, we assume that we have access to a representative example of input data used during training and to the exact parameters (weights and biases) of the trained ReLU network. The mapping from deep ReLU networks to SNNs causes zero percent drop in accuracy on CIFAR10, CIFAR100 and the ImageNet-like data sets Places365 and PASS. More generally our work shows that an arbitrary deep ReLU network can be replaced by an energy-efficient single-spike neural network without any loss of performance.
On the visual analytic intelligence of neural networks
Sep 28, 2022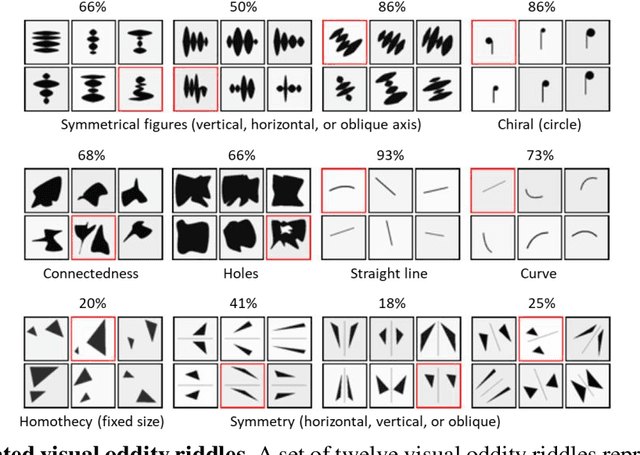
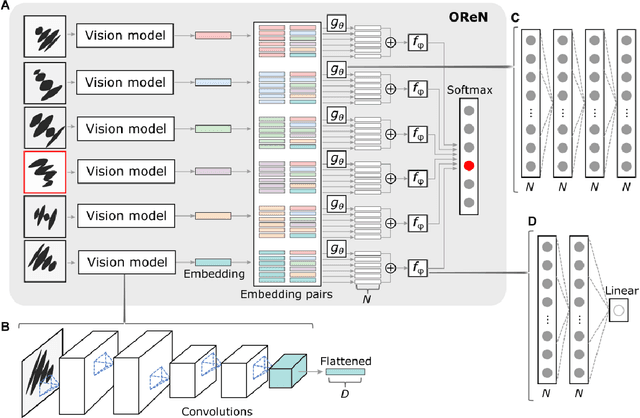
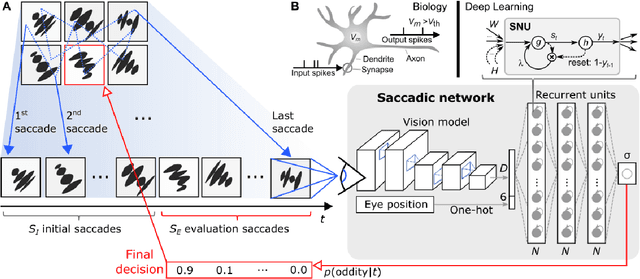
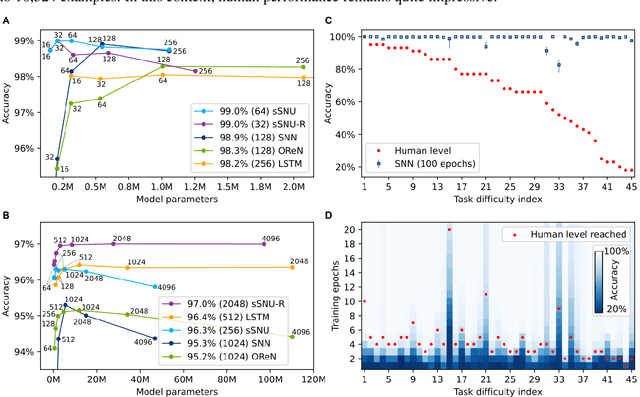
Visual oddity task was conceived as a universal ethnic-independent analytic intelligence test for humans. Advancements in artificial intelligence led to important breakthroughs, yet competing with humans on such analytic intelligence tasks remains challenging and typically resorts to non-biologically-plausible architectures. We present a biologically realistic system that receives inputs from synthetic eye movements - saccades, and processes them with neurons incorporating dynamics of neocortical neurons. We introduce a procedurally generated visual oddity dataset to train an architecture extending conventional relational networks and our proposed system. Both approaches surpass the human accuracy, and we uncover that both share the same essential underlying mechanism of reasoning. Finally, we show that the biologically inspired network achieves superior accuracy, learns faster and requires fewer parameters than the conventional network.
In-memory Realization of In-situ Few-shot Continual Learning with a Dynamically Evolving Explicit Memory
Jul 14, 2022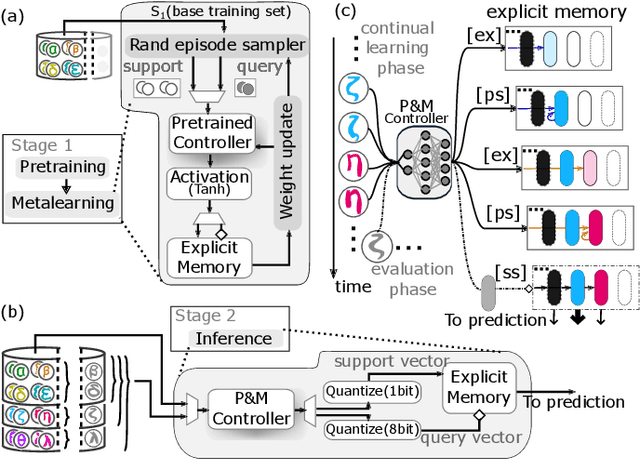
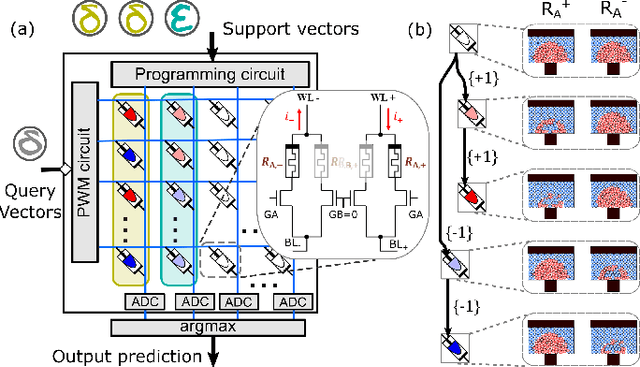
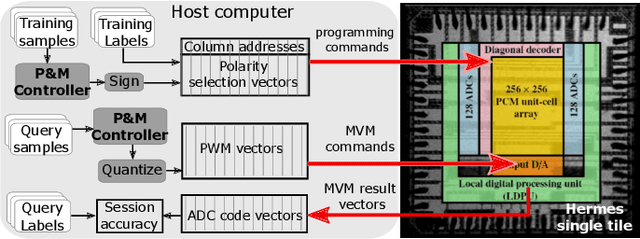
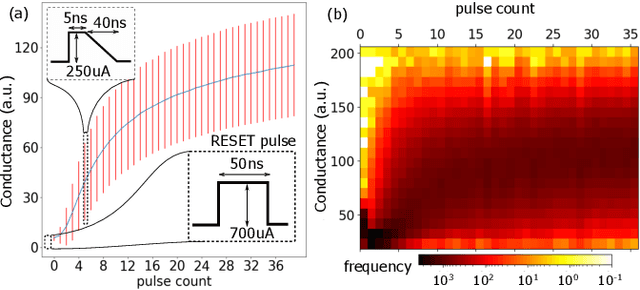
Continually learning new classes from a few training examples without forgetting previous old classes demands a flexible architecture with an inevitably growing portion of storage, in which new examples and classes can be incrementally stored and efficiently retrieved. One viable architectural solution is to tightly couple a stationary deep neural network to a dynamically evolving explicit memory (EM). As the centerpiece of this architecture, we propose an EM unit that leverages energy-efficient in-memory compute (IMC) cores during the course of continual learning operations. We demonstrate for the first time how the EM unit can physically superpose multiple training examples, expand to accommodate unseen classes, and perform similarity search during inference, using operations on an IMC core based on phase-change memory (PCM). Specifically, the physical superposition of a few encoded training examples is realized via in-situ progressive crystallization of PCM devices. The classification accuracy achieved on the IMC core remains within a range of 1.28%--2.5% compared to that of the state-of-the-art full-precision baseline software model on both the CIFAR-100 and miniImageNet datasets when continually learning 40 novel classes (from only five examples per class) on top of 60 old classes.
Constrained Few-shot Class-incremental Learning
Mar 30, 2022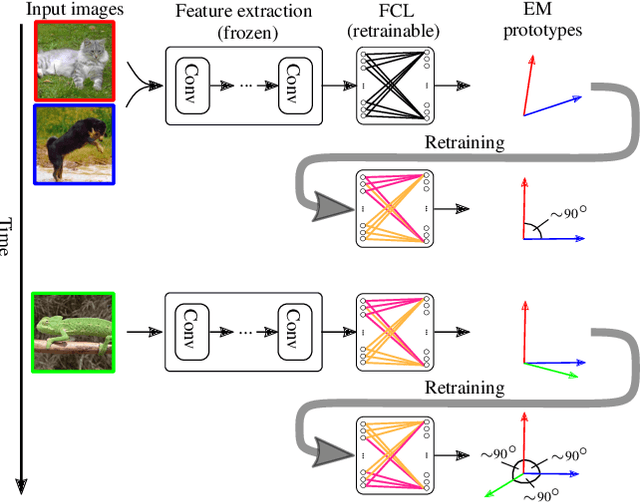
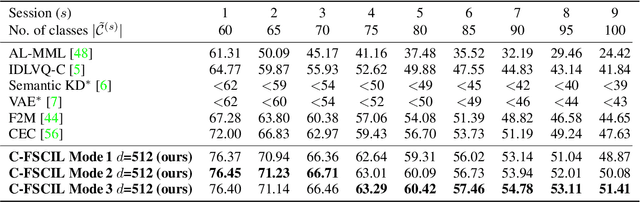
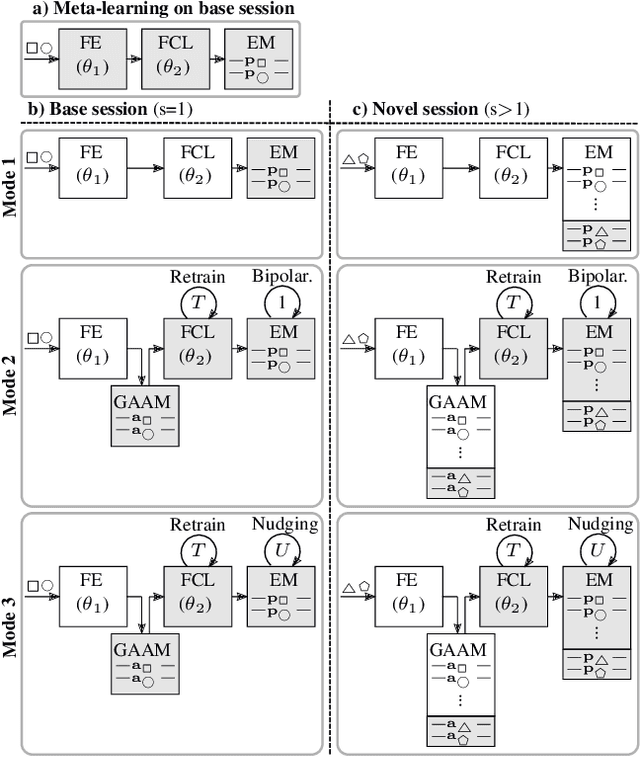
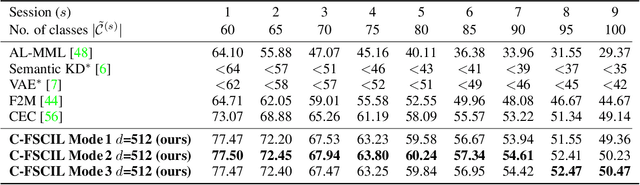
Continually learning new classes from fresh data without forgetting previous knowledge of old classes is a very challenging research problem. Moreover, it is imperative that such learning must respect certain memory and computational constraints such as (i) training samples are limited to only a few per class, (ii) the computational cost of learning a novel class remains constant, and (iii) the memory footprint of the model grows at most linearly with the number of classes observed. To meet the above constraints, we propose C-FSCIL, which is architecturally composed of a frozen meta-learned feature extractor, a trainable fixed-size fully connected layer, and a rewritable dynamically growing memory that stores as many vectors as the number of encountered classes. C-FSCIL provides three update modes that offer a trade-off between accuracy and compute-memory cost of learning novel classes. C-FSCIL exploits hyperdimensional embedding that allows to continually express many more classes than the fixed dimensions in the vector space, with minimal interference. The quality of class vector representations is further improved by aligning them quasi-orthogonally to each other by means of novel loss functions. Experiments on the CIFAR100, miniImageNet, and Omniglot datasets show that C-FSCIL outperforms the baselines with remarkable accuracy and compression. It also scales up to the largest problem size ever tried in this few-shot setting by learning 423 novel classes on top of 1200 base classes with less than 1.6% accuracy drop. Our code is available at https://github.com/IBM/constrained-FSCIL.
Robust High-dimensional Memory-augmented Neural Networks
Oct 05, 2020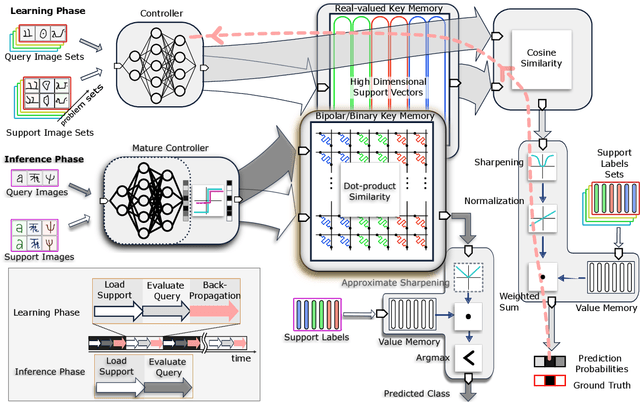
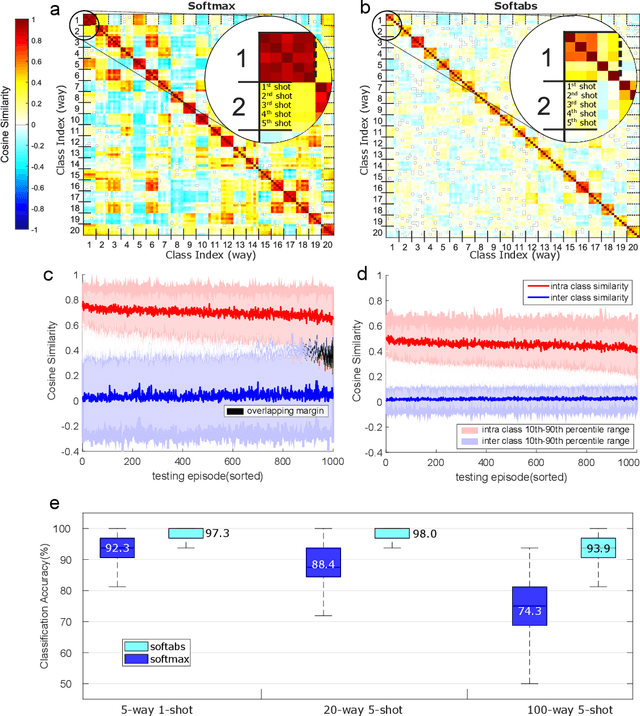
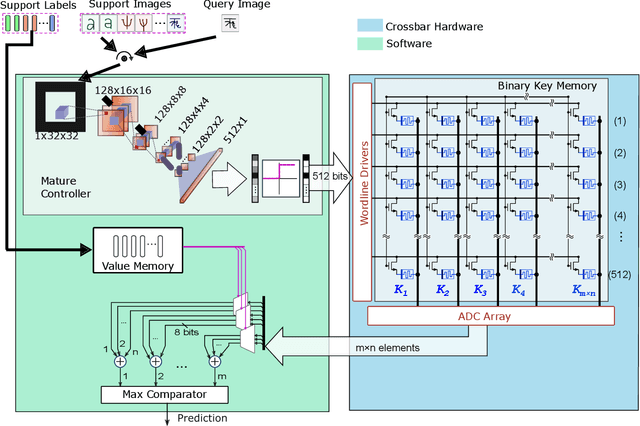
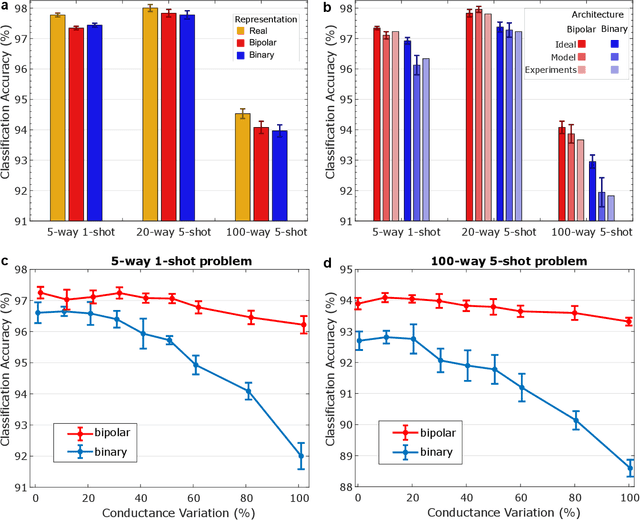
Traditional neural networks require enormous amounts of data to build their complex mappings during a slow training procedure that hinders their abilities for relearning and adapting to new data. Memory-augmented neural networks enhance neural networks with an explicit memory to overcome these issues. Access to this explicit memory, however, occurs via soft read and write operations involving every individual memory entry, resulting in a bottleneck when implemented using the conventional von Neumann computer architecture. To overcome this bottleneck, we propose a robust architecture that employs a computational memory unit as the explicit memory performing analog in-memory computation on high-dimensional vectors, while closely matching 32-bit software-equivalent accuracy. This is enabled by a content-based attention mechanism that represents unrelated items in the computational memory with uncorrelated high-dimensional vectors, whose real-valued components can be readily approximated by binary, or bipolar components. Experimental results demonstrate the efficacy of our approach on few-shot image classification tasks on the Omniglot dataset using more than 256,000 phase-change memory devices.
File Classification Based on Spiking Neural Networks
Apr 08, 2020
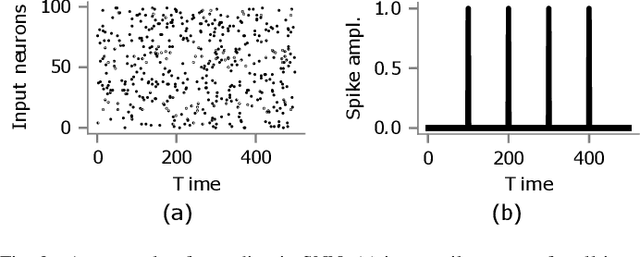


In this paper, we propose a system for file classification in large data sets based on spiking neural networks (SNNs). File information contained in key-value metadata pairs is mapped by a novel correlative temporal encoding scheme to spike patterns that are input to an SNN. The correlation between input spike patterns is determined by a file similarity measure. Unsupervised training of such networks using spike-timing-dependent plasticity (STDP) is addressed first. Then, supervised SNN training is considered by backpropagation of an error signal that is obtained by comparing the spike pattern at the output neurons with a target pattern representing the desired class. The classification accuracy is measured for various publicly available data sets with tens of thousands of elements, and compared with other learning algorithms, including logistic regression and support vector machines. Simulation results indicate that the proposed SNN-based system using memristive synapses may represent a valid alternative to classical machine learning algorithms for inference tasks, especially in environments with asynchronous ingest of input data and limited resources.
In-memory hyperdimensional computing
Jun 04, 2019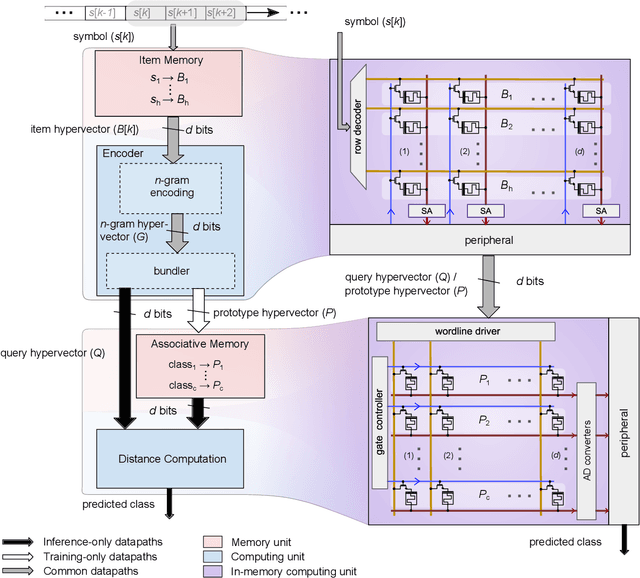
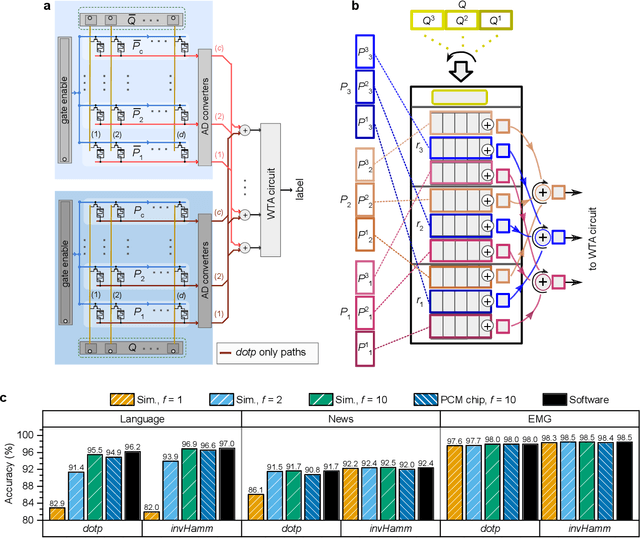
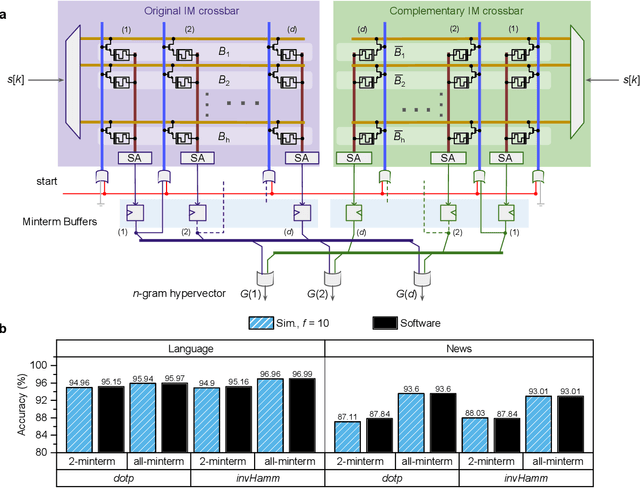
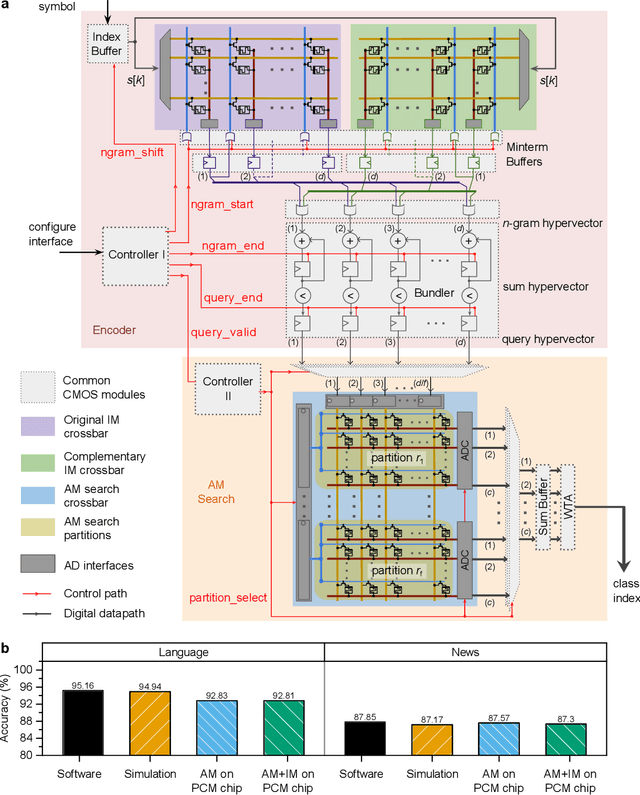
Hyperdimensional computing (HDC) is an emerging computing framework that takes inspiration from attributes of neuronal circuits such as hyperdimensionality, fully distributed holographic representation, and (pseudo)randomness. When employed for machine learning tasks such as learning and classification, HDC involves manipulation and comparison of large patterns within memory. Moreover, a key attribute of HDC is its robustness to the imperfections associated with the computational substrates on which it is implemented. It is therefore particularly amenable to emerging non-von Neumann paradigms such as in-memory computing, where the physical attributes of nanoscale memristive devices are exploited to perform computation in place. Here, we present a complete in-memory HDC system that achieves a near-optimum trade-off between design complexity and classification accuracy based on three prototypical HDC related learning tasks, namely, language classification, news classification, and hand gesture recognition from electromyography signals. Comparable accuracies to software implementations are demonstrated, experimentally, using 760,000 phase-change memory devices performing analog in-memory computing.