 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre training trajectories of deep single-spike and deep ReLU network equivalent?
Jun 14, 2023Communication by binary and sparse spikes is a key factor for the energy efficiency of biological brains. However, training deep spiking neural networks (SNNs) with backpropagation is harder than with artificial neural networks (ANNs), which is puzzling given that recent theoretical results provide exact mapping algorithms from ReLU to time-to-first-spike (TTFS) SNNs. Building upon these results, we analyze in theory and in simulation the learning dynamics of TTFS-SNNs. Our analysis highlights that even when an SNN can be mapped exactly to a ReLU network, it cannot always be robustly trained by gradient descent. The reason for that is the emergence of a specific instance of the vanishing-or-exploding gradient problem leading to a bias in the gradient descent trajectory in comparison with the equivalent ANN. After identifying this issue we derive a generic solution for the network initialization and SNN parameterization which guarantees that the SNN can be trained as robustly as its ANN counterpart. Our theoretical findings are illustrated in practice on image classification datasets. Our method achieves the same accuracy as deep ConvNets on CIFAR10 and enables fine-tuning on the much larger PLACES365 dataset without loss of accuracy compared to the ANN. We argue that the combined perspective of conversion and fine-tuning with robust gradient descent in SNN will be decisive to optimize SNNs for hardware implementations needing low latency and resilience to noise and quantization.
An Exact Mapping From ReLU Networks to Spiking Neural Networks
Dec 23, 2022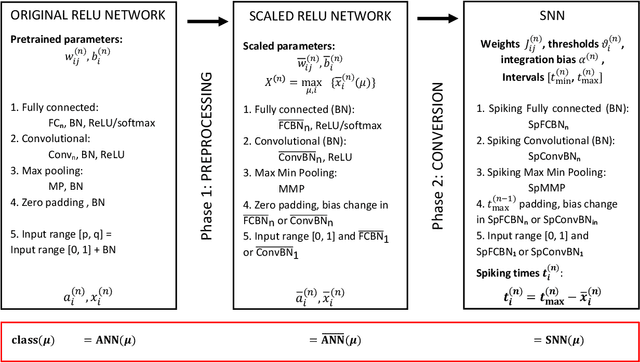
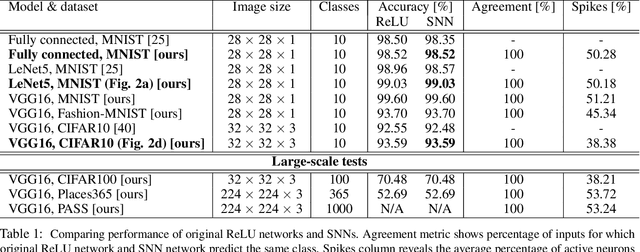
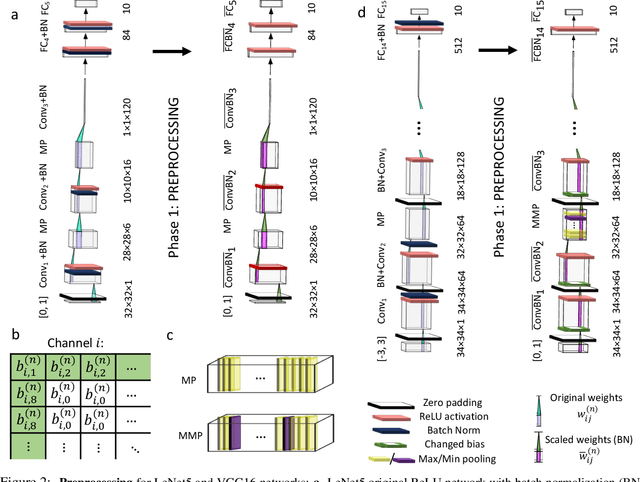
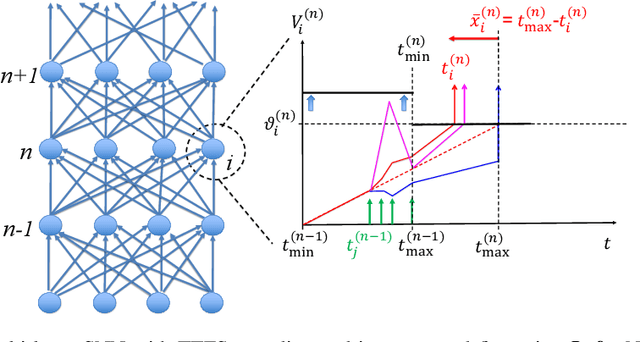
Deep spiking neural networks (SNNs) offer the promise of low-power artificial intelligence. However, training deep SNNs from scratch or converting deep artificial neural networks to SNNs without loss of performance has been a challenge. Here we propose an exact mapping from a network with Rectified Linear Units (ReLUs) to an SNN that fires exactly one spike per neuron. For our constructive proof, we assume that an arbitrary multi-layer ReLU network with or without convolutional layers, batch normalization and max pooling layers was trained to high performance on some training set. Furthermore, we assume that we have access to a representative example of input data used during training and to the exact parameters (weights and biases) of the trained ReLU network. The mapping from deep ReLU networks to SNNs causes zero percent drop in accuracy on CIFAR10, CIFAR100 and the ImageNet-like data sets Places365 and PASS. More generally our work shows that an arbitrary deep ReLU network can be replaced by an energy-efficient single-spike neural network without any loss of performance.
File Classification Based on Spiking Neural Networks
Apr 08, 2020


In this paper, we propose a system for file classification in large data sets based on spiking neural networks (SNNs). File information contained in key-value metadata pairs is mapped by a novel correlative temporal encoding scheme to spike patterns that are input to an SNN. The correlation between input spike patterns is determined by a file similarity measure. Unsupervised training of such networks using spike-timing-dependent plasticity (STDP) is addressed first. Then, supervised SNN training is considered by backpropagation of an error signal that is obtained by comparing the spike pattern at the output neurons with a target pattern representing the desired class. The classification accuracy is measured for various publicly available data sets with tens of thousands of elements, and compared with other learning algorithms, including logistic regression and support vector machines. Simulation results indicate that the proposed SNN-based system using memristive synapses may represent a valid alternative to classical machine learning algorithms for inference tasks, especially in environments with asynchronous ingest of input data and limited resources.