 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Neuromorphic Memristor closely Emulates Multiple Synaptic Mechanisms for Energy Efficient Neural Networks
Feb 26, 2024Biological neural networks do not only include long-term memory and weight multiplication capabilities, as commonly assumed in artificial neural networks, but also more complex functions such as short-term memory, short-term plasticity, and meta-plasticity - all collocated within each synapse. Here, we demonstrate memristive nano-devices based on SrTiO3 that inherently emulate all these synaptic functions. These memristors operate in a non-filamentary, low conductance regime, which enables stable and energy efficient operation. They can act as multi-functional hardware synapses in a class of bio-inspired deep neural networks (DNN) that make use of both long- and short-term synaptic dynamics and are capable of meta-learning or "learning-to-learn". The resulting bio-inspired DNN is then trained to play the video game Atari Pong, a complex reinforcement learning task in a dynamic environment. Our analysis shows that the energy consumption of the DNN with multi-functional memristive synapses decreases by about two orders of magnitude as compared to a pure GPU implementation. Based on this finding, we infer that memristive devices with a better emulation of the synaptic functionalities do not only broaden the applicability of neuromorphic computing, but could also improve the performance and energy costs of certain artificial intelligence applications.
Self-Supervised Learning Through Efference Copies
Oct 17, 2022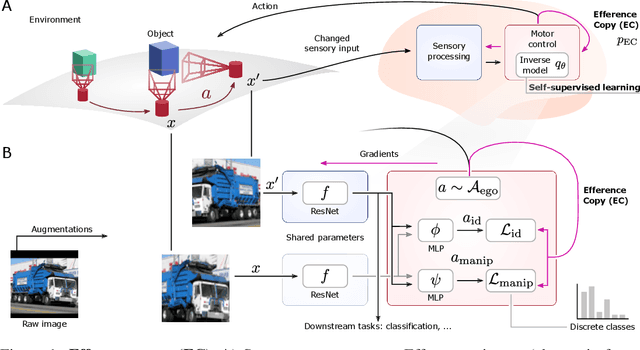
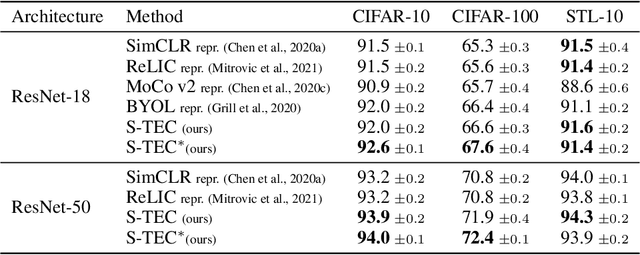
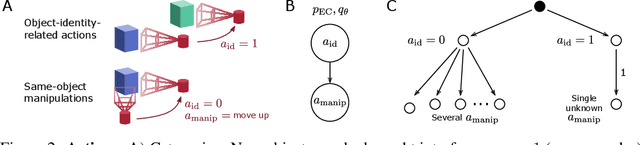

Self-supervised learning (SSL) methods aim to exploit the abundance of unlabelled data for machine learning (ML), however the underlying principles are often method-specific. An SSL framework derived from biological first principles of embodied learning could unify the various SSL methods, help elucidate learning in the brain, and possibly improve ML. SSL commonly transforms each training datapoint into a pair of views, uses the knowledge of this pairing as a positive (i.e. non-contrastive) self-supervisory sign, and potentially opposes it to unrelated, (i.e. contrastive) negative examples. Here, we show that this type of self-supervision is an incomplete implementation of a concept from neuroscience, the Efference Copy (EC). Specifically, the brain also transforms the environment through efference, i.e. motor commands, however it sends to itself an EC of the full commands, i.e. more than a mere SSL sign. In addition, its action representations are likely egocentric. From such a principled foundation we formally recover and extend SSL methods such as SimCLR, BYOL, and ReLIC under a common theoretical framework, i.e. Self-supervision Through Efference Copies (S-TEC). Empirically, S-TEC restructures meaningfully the within- and between-class representations. This manifests as improvement in recent strong SSL baselines in image classification, segmentation, object detection, and in audio. These results hypothesize a testable positive influence from the brain's motor outputs onto its sensory representations.
Hebbian Deep Learning Without Feedback
Sep 23, 2022
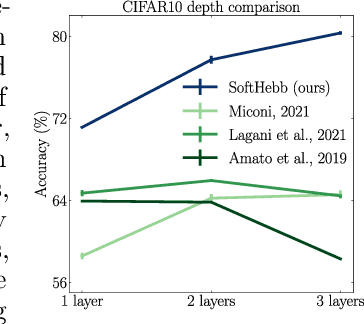


Recent approximations to backpropagation (BP) have mitigated many of BP's computational inefficiencies and incompatibilities with biology, but important limitations still remain. Moreover, the approximations significantly decrease accuracy in benchmarks, suggesting that an entirely different approach may be more fruitful. Here, grounded on recent theory for Hebbian learning in soft winner-take-all networks, we present multilayer SoftHebb, i.e. an algorithm that trains deep neural networks, without any feedback, target, or error signals. As a result, it achieves efficiency by avoiding weight transport, non-local plasticity, time-locking of layer updates, iterative equilibria, and (self-) supervisory or other feedback signals -- which were necessary in other approaches. Its increased efficiency and biological compatibility do not trade off accuracy compared to state-of-the-art bio-plausible learning, but rather improve it. With up to five hidden layers and an added linear classifier, accuracies on MNIST, CIFAR-10, STL-10, and ImageNet, respectively reach 99.4%, 80.3%, 76.2%, and 27.3%. In conclusion, SoftHebb shows with a radically different approach from BP that Deep Learning over few layers may be plausible in the brain and increases the accuracy of bio-plausible machine learning.
Short-Term Plasticity Neurons Learning to Learn and Forget
Jun 28, 2022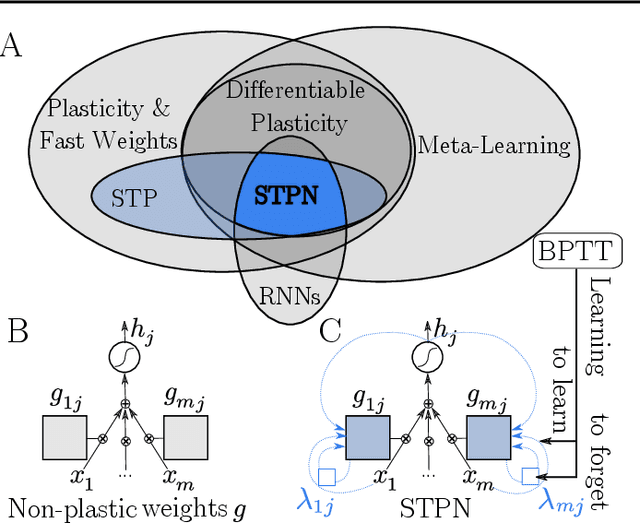

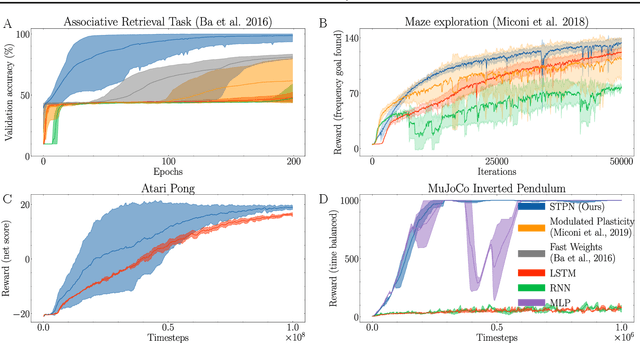

Short-term plasticity (STP) is a mechanism that stores decaying memories in synapses of the cerebral cortex. In computing practice, STP has been used, but mostly in the niche of spiking neurons, even though theory predicts that it is the optimal solution to certain dynamic tasks. Here we present a new type of recurrent neural unit, the STP Neuron (STPN), which indeed turns out strikingly powerful. Its key mechanism is that synapses have a state, propagated through time by a self-recurrent connection-within-the-synapse. This formulation enables training the plasticity with backpropagation through time, resulting in a form of learning to learn and forget in the short term. The STPN outperforms all tested alternatives, i.e. RNNs, LSTMs, other models with fast weights, and differentiable plasticity. We confirm this in both supervised and reinforcement learning (RL), and in tasks such as Associative Retrieval, Maze Exploration, Atari video games, and MuJoCo robotics. Moreover, we calculate that, in neuromorphic or biological circuits, the STPN minimizes energy consumption across models, as it depresses individual synapses dynamically. Based on these, biological STP may have been a strong evolutionary attractor that maximizes both efficiency and computational power. The STPN now brings these neuromorphic advantages also to a broad spectrum of machine learning practice. Code is available at https://github.com/NeuromorphicComputing/stpn
* Accepted at ICML 2022
Spike-inspired Rank Coding for Fast and Accurate Recurrent Neural Networks
Oct 06, 2021



Biological spiking neural networks (SNNs) can temporally encode information in their outputs, e.g. in the rank order in which neurons fire, whereas artificial neural networks (ANNs) conventionally do not. As a result, models of SNNs for neuromorphic computing are regarded as potentially more rapid and efficient than ANNs when dealing with temporal input. On the other hand, ANNs are simpler to train, and usually achieve superior performance. Here we show that temporal coding such as rank coding (RC) inspired by SNNs can also be applied to conventional ANNs such as LSTMs, and leads to computational savings and speedups. In our RC for ANNs, we apply backpropagation through time using the standard real-valued activations, but only from a strategically early time step of each sequential input example, decided by a threshold-crossing event. Learning then incorporates naturally also _when_ to produce an output, without other changes to the model or the algorithm. Both the forward and the backward training pass can be significantly shortened by skipping the remaining input sequence after that first event. RC-training also significantly reduces time-to-insight during inference, with a minimal decrease in accuracy. The desired speed-accuracy trade-off is tunable by varying the threshold or a regularization parameter that rewards output entropy. We demonstrate these in two toy problems of sequence classification, and in a temporally-encoded MNIST dataset where our RC model achieves 99.19% accuracy after the first input time-step, outperforming the state of the art in temporal coding with SNNs, as well as in spoken-word classification of Google Speech Commands, outperforming non-RC-trained early inference with LSTMs.
SoftHebb: Bayesian inference in unsupervised Hebbian soft winner-take-all networks
Jul 12, 2021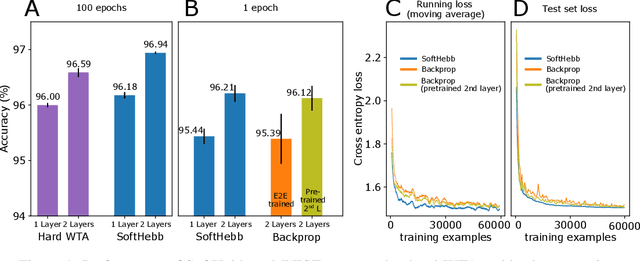
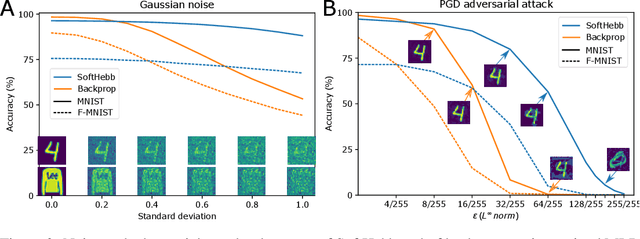
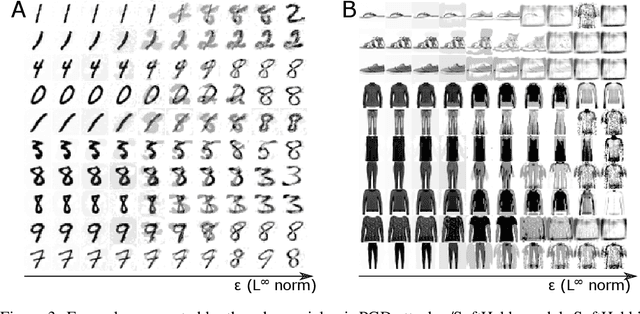
State-of-the-art artificial neural networks (ANNs) require labelled data or feedback between layers, are often biologically implausible, and are vulnerable to adversarial attacks that humans are not susceptible to. On the other hand, Hebbian learning in winner-take-all (WTA) networks, is unsupervised, feed-forward, and biologically plausible. However, an objective optimization theory for WTA networks has been missing, except under very limiting assumptions. Here we derive formally such a theory, based on biologically plausible but generic ANN elements. Through Hebbian learning, network parameters maintain a Bayesian generative model of the data. There is no supervisory loss function, but the network does minimize cross-entropy between its activations and the input distribution. The key is a "soft" WTA where there is no absolute "hard" winner neuron, and a specific type of Hebbian-like plasticity of weights and biases. We confirm our theory in practice, where, in handwritten digit (MNIST) recognition, our Hebbian algorithm, SoftHebb, minimizes cross-entropy without having access to it, and outperforms the more frequently used, hard-WTA-based method. Strikingly, it even outperforms supervised end-to-end backpropagation, under certain conditions. Specifically, in a two-layered network, SoftHebb outperforms backpropagation when the training dataset is only presented once, when the testing data is noisy, and under gradient-based adversarial attacks. Adversarial attacks that confuse SoftHebb are also confusing to the human eye. Finally, the model can generate interpolations of objects from its input distribution.
Short-term synaptic plasticity optimally models continuous environments
Sep 15, 2020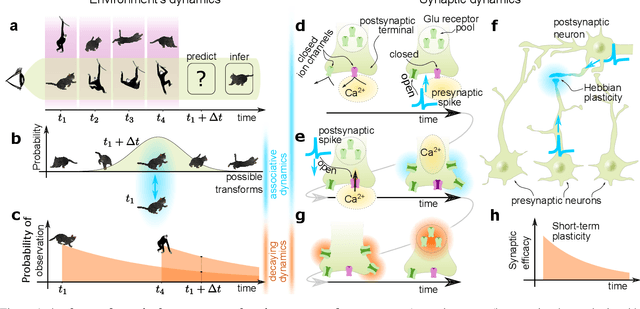
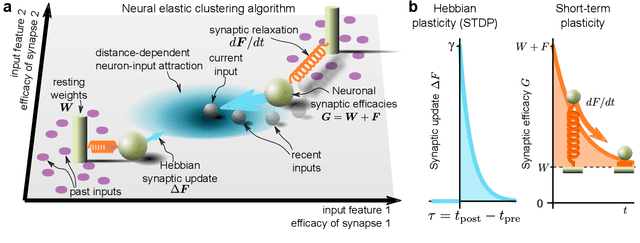
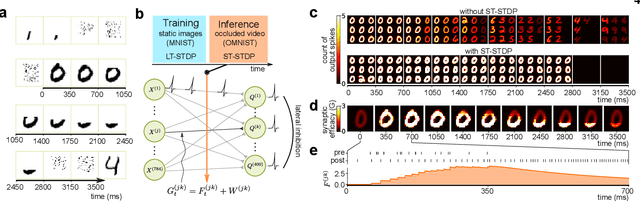
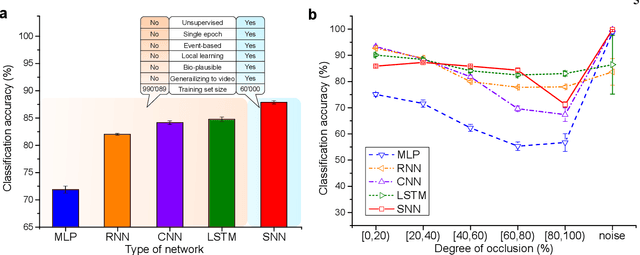
Biological neural networks operate with extraordinary energy efficiency, owing to properties such as spike-based communication and synaptic plasticity driven by local activity. When emulated in silico, such properties also enable highly energy-efficient machine learning and inference systems. However, it is unclear whether these mechanisms only trade off performance for efficiency or rather they are partly responsible for the superiority of biological intelligence. Here, we first address this theoretically, proving rigorously that indeed the optimal prediction and inference of randomly but continuously transforming environments, a common natural setting, relies on adaptivity through short-term spike-timing dependent plasticity, a hallmark of biological neural networks. Secondly, we assess this theoretical optimality via simulations and also demonstrate improved artificial intelligence (AI). For the first time, a largely biologically modelled spiking neural network (SNN) surpasses state-of-the-art artificial neural networks (ANNs) in all relevant aspects, in an example task of recognizing video frames transformed by moving occlusions. The SNN recognizes the frames more accurately, even if trained on few, still, and untransformed images, with unsupervised and synaptically-local learning, binary spikes, and a single layer of neurons - all in contrast to the deep-learning-trained ANNs. These results indicate that on-line adaptivity and spike-based computation may optimize natural intelligence for natural environments. Moreover, this expands the goal of exploiting biological neuro-synaptic properties for AI, from mere efficiency, to computational supremacy altogether.
File Classification Based on Spiking Neural Networks
Apr 08, 2020


In this paper, we propose a system for file classification in large data sets based on spiking neural networks (SNNs). File information contained in key-value metadata pairs is mapped by a novel correlative temporal encoding scheme to spike patterns that are input to an SNN. The correlation between input spike patterns is determined by a file similarity measure. Unsupervised training of such networks using spike-timing-dependent plasticity (STDP) is addressed first. Then, supervised SNN training is considered by backpropagation of an error signal that is obtained by comparing the spike pattern at the output neurons with a target pattern representing the desired class. The classification accuracy is measured for various publicly available data sets with tens of thousands of elements, and compared with other learning algorithms, including logistic regression and support vector machines. Simulation results indicate that the proposed SNN-based system using memristive synapses may represent a valid alternative to classical machine learning algorithms for inference tasks, especially in environments with asynchronous ingest of input data and limited resources.
Fatiguing STDP: Learning from Spike-Timing Codes in the Presence of Rate Codes
Jun 17, 2017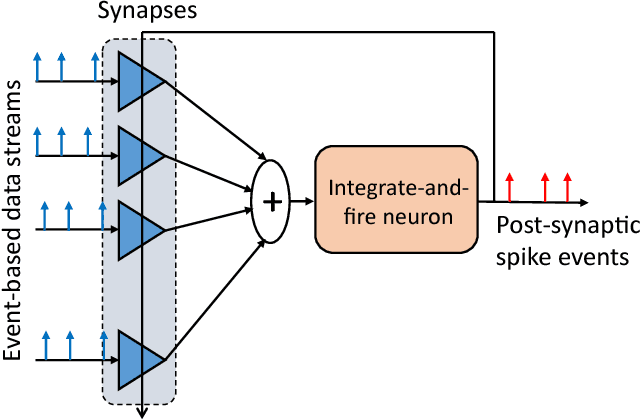
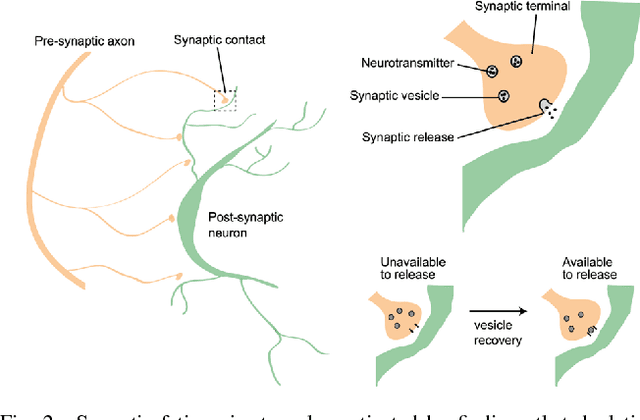
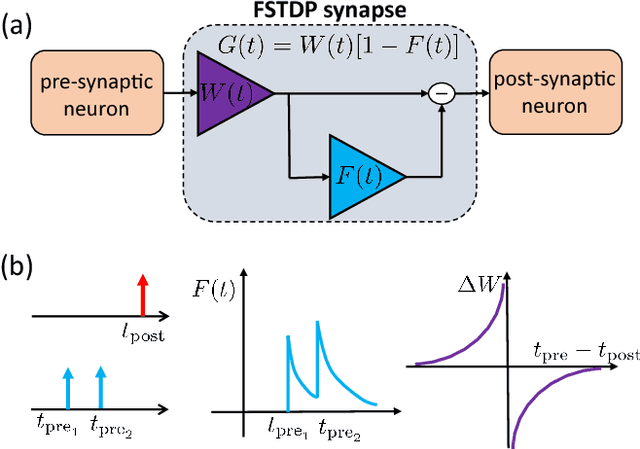
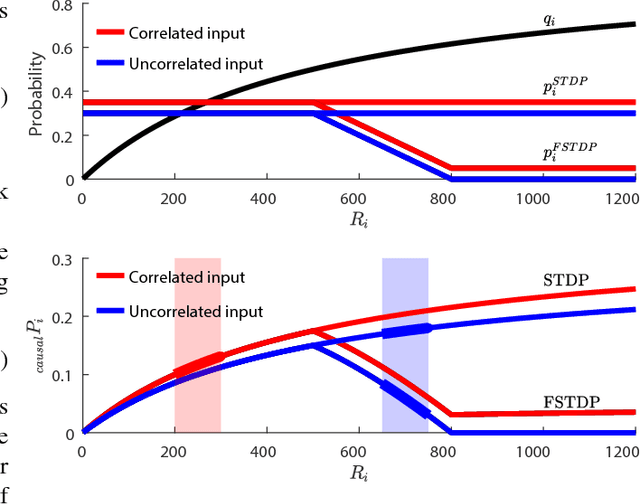
Spiking neural networks (SNNs) could play a key role in unsupervised machine learning applications, by virtue of strengths related to learning from the fine temporal structure of event-based signals. However, some spike-timing-related strengths of SNNs are hindered by the sensitivity of spike-timing-dependent plasticity (STDP) rules to input spike rates, as fine temporal correlations may be obstructed by coarser correlations between firing rates. In this article, we propose a spike-timing-dependent learning rule that allows a neuron to learn from the temporally-coded information despite the presence of rate codes. Our long-term plasticity rule makes use of short-term synaptic fatigue dynamics. We show analytically that, in contrast to conventional STDP rules, our fatiguing STDP (FSTDP) helps learn the temporal code, and we derive the necessary conditions to optimize the learning process. We showcase the effectiveness of FSTDP in learning spike-timing correlations among processes of different rates in synthetic data. Finally, we use FSTDP to detect correlations in real-world weather data from the United States in an experimental realization of the algorithm that uses a neuromorphic hardware platform comprising phase-change memristive devices. Taken together, our analyses and demonstrations suggest that FSTDP paves the way for the exploitation of the spike-based strengths of SNNs in real-world applications.