 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinker: A vision-language foundation model for embodied intelligence
Jan 29, 2026When large vision-language models are applied to the field of robotics, they encounter problems that are simple for humans yet error-prone for models. Such issues include confusion between third-person and first-person perspectives and a tendency to overlook information in video endings during temporal reasoning. To address these challenges, we propose Thinker, a large vision-language foundation model designed for embodied intelligence. We tackle the aforementioned issues from two perspectives. Firstly, we construct a large-scale dataset tailored for robotic perception and reasoning, encompassing ego-view videos, visual grounding, spatial understanding, and chain-of-thought data. Secondly, we introduce a simple yet effective approach that substantially enhances the model's capacity for video comprehension by jointly incorporating key frames and full video sequences as inputs. Our model achieves state-of-the-art results on two of the most commonly used benchmark datasets in the field of task planning.
Graph Reasoning Paradigm: Structured and Symbolic Reasoning with Topology-Aware Reinforcement Learning for Large Language Models
Jan 19, 2026Long Chain-of-Thought (LCoT), achieved by Reinforcement Learning with Verifiable Rewards (RLVR), has proven effective in enhancing the reasoning capabilities of Large Language Models (LLMs). However, reasoning in current LLMs is primarily generated as plain text, where performing semantic evaluation on such unstructured data creates a computational bottleneck during training. Despite RLVR-based optimization, existing methods still suffer from coarse-grained supervision, reward hacking, high training costs, and poor generalization. To address these issues, we propose the Graph Reasoning Paradigm (GRP), which realizes structured and symbolic reasoning, implemented via graph-structured representations with step-level cognitive labels. Building upon GRP, we further design Process-Aware Stratified Clipping Group Relative Policy Optimization (PASC-GRPO), which leverages structured evaluation to replace semantic evaluation, achieves process-aware verification through graph-structured outcome rewards, and mitigates reward hacking via stratified clipping advantage estimation. Experiments demonstrate significant improvements across mathematical reasoning and code generation tasks. Data, models, and code will be released later.
NeuroCLIP: Brain-Inspired Prompt Tuning for EEG-to-Image Multimodal Contrastive Learning
Nov 12, 2025Recent advances in brain-inspired artificial intelligence have sought to align neural signals with visual semantics using multimodal models such as CLIP. However, existing methods often treat CLIP as a static feature extractor, overlooking its adaptability to neural representations and the inherent physiological-symbolic gap in EEG-image alignment. To address these challenges, we present NeuroCLIP, a prompt tuning framework tailored for EEG-to-image contrastive learning. Our approach introduces three core innovations: (1) We design a dual-stream visual embedding pipeline that combines dynamic filtering and token-level fusion to generate instance-level adaptive prompts, which guide the adjustment of patch embedding tokens based on image content, thereby enabling fine-grained modulation of visual representations under neural constraints; (2) We are the first to introduce visual prompt tokens into EEG-image alignment, acting as global, modality-level prompts that work in conjunction with instance-level adjustments. These visual prompt tokens are inserted into the Transformer architecture to facilitate neural-aware adaptation and parameter optimization at a global level; (3) Inspired by neuroscientific principles of human visual encoding, we propose a refined contrastive loss that better model the semantic ambiguity and cross-modal noise present in EEG signals. On the THINGS-EEG2 dataset, NeuroCLIP achieves a Top-1 accuracy of 63.2% in zero-shot image retrieval, surpassing the previous best method by +12.3%, and demonstrates strong generalization under inter-subject conditions (+4.6% Top-1), highlighting the potential of physiology-aware prompt tuning for bridging brain signals and visual semantics.
Advancing Real-World Parking Slot Detection with Large-Scale Dataset and Semi-Supervised Baseline
Sep 16, 2025As automatic parking systems evolve, the accurate detection of parking slots has become increasingly critical. This study focuses on parking slot detection using surround-view cameras, which offer a comprehensive bird's-eye view of the parking environment. However, the current datasets are limited in scale, and the scenes they contain are seldom disrupted by real-world noise (e.g., light, occlusion, etc.). Moreover, manual data annotation is prone to errors and omissions due to the complexity of real-world conditions, significantly increasing the cost of annotating large-scale datasets. To address these issues, we first construct a large-scale parking slot detection dataset (named CRPS-D), which includes various lighting distributions, diverse weather conditions, and challenging parking slot variants. Compared with existing datasets, the proposed dataset boasts the largest data scale and consists of a higher density of parking slots, particularly featuring more slanted parking slots. Additionally, we develop a semi-supervised baseline for parking slot detection, termed SS-PSD, to further improve performance by exploiting unlabeled data. To our knowledge, this is the first semi-supervised approach in parking slot detection, which is built on the teacher-student model with confidence-guided mask consistency and adaptive feature perturbation. Experimental results demonstrate the superiority of SS-PSD over the existing state-of-the-art (SoTA) solutions on both the proposed dataset and the existing dataset. Particularly, the more unlabeled data there is, the more significant the gains brought by our semi-supervised scheme. The relevant source codes and the dataset have been made publicly available at https://github.com/zzh362/CRPS-D.
Beyond Wide-Angle Images: Unsupervised Video Portrait Correction via Spatiotemporal Diffusion Adaptation
Apr 01, 2025Wide-angle cameras, despite their popularity for content creation, suffer from distortion-induced facial stretching-especially at the edge of the lens-which degrades visual appeal. To address this issue, we propose an image portrait correction framework using diffusion models named ImagePD. It integrates the long-range awareness of transformer and multi-step denoising of diffusion models into a unified framework, achieving global structural robustness and local detail refinement. Besides, considering the high cost of obtaining video labels, we then repurpose ImagePD for unlabeled wide-angle videos (termed VideoPD), by spatiotemporal diffusion adaption with spatial consistency and temporal smoothness constraints. For the former, we encourage the denoised image to approximate pseudo labels following the wide-angle distortion distribution pattern, while for the latter, we derive rectification trajectories with backward optical flows and smooth them. Compared with ImagePD, VideoPD maintains high-quality facial corrections in space and mitigates the potential temporal shakes sequentially. Finally, to establish an evaluation benchmark and train the framework, we establish a video portrait dataset with a large diversity in people number, lighting conditions, and background. Experiments demonstrate that the proposed methods outperform existing solutions quantitatively and qualitatively, contributing to high-fidelity wide-angle videos with stable and natural portraits. The codes and dataset will be available.
Jasmine: Harnessing Diffusion Prior for Self-supervised Depth Estimation
Mar 20, 2025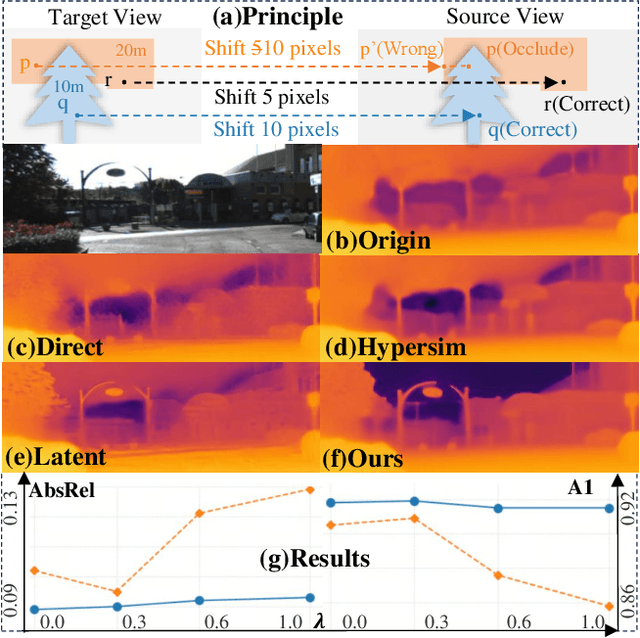
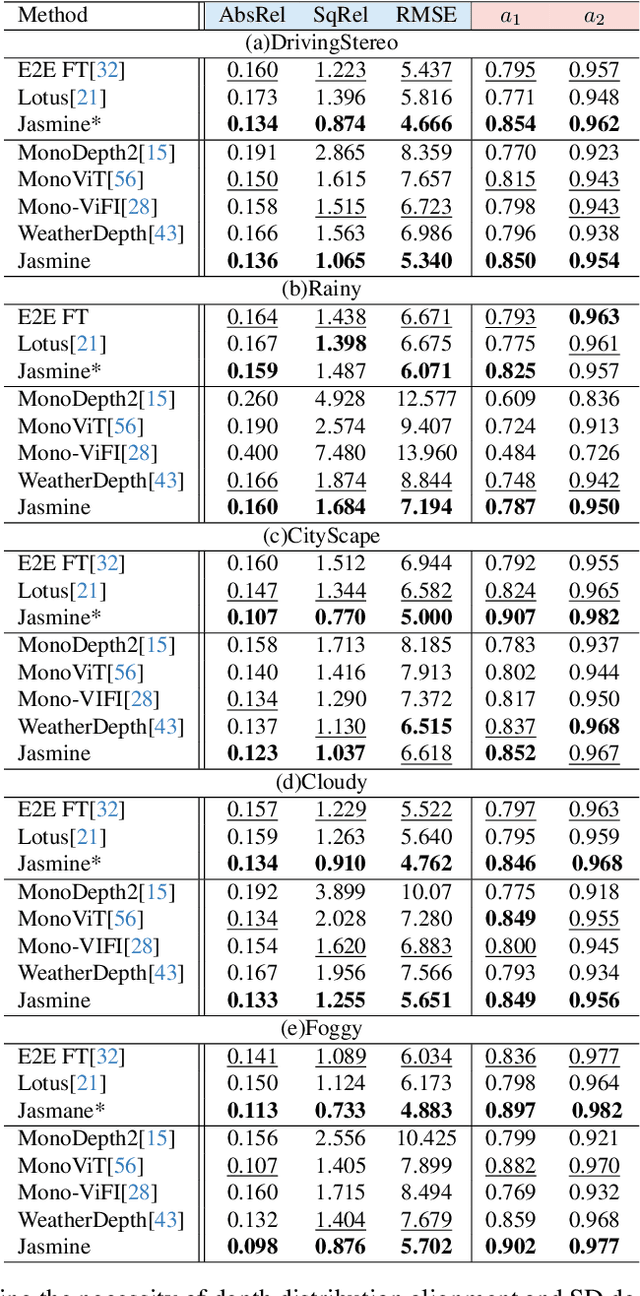
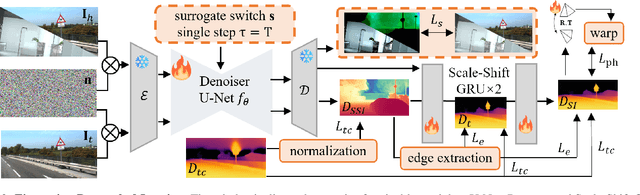
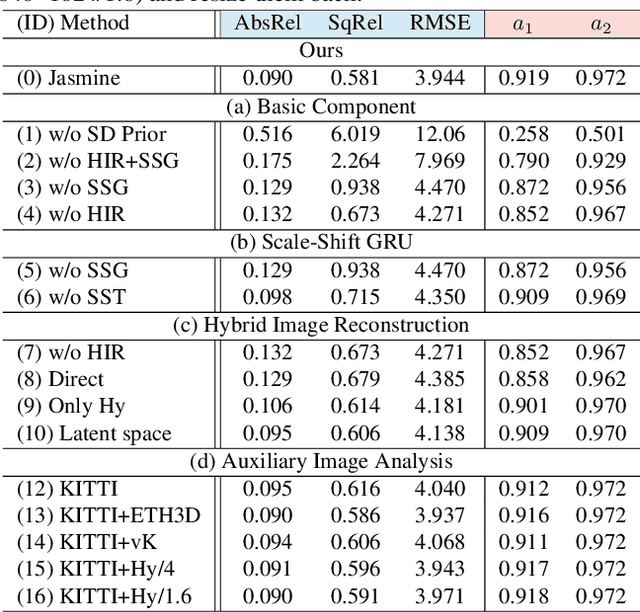
In this paper, we propose Jasmine, the first Stable Diffusion (SD)-based self-supervised framework for monocular depth estimation, which effectively harnesses SD's visual priors to enhance the sharpness and generalization of unsupervised prediction. Previous SD-based methods are all supervised since adapting diffusion models for dense prediction requires high-precision supervision. In contrast, self-supervised reprojection suffers from inherent challenges (e.g., occlusions, texture-less regions, illumination variance), and the predictions exhibit blurs and artifacts that severely compromise SD's latent priors. To resolve this, we construct a novel surrogate task of hybrid image reconstruction. Without any additional supervision, it preserves the detail priors of SD models by reconstructing the images themselves while preventing depth estimation from degradation. Furthermore, to address the inherent misalignment between SD's scale and shift invariant estimation and self-supervised scale-invariant depth estimation, we build the Scale-Shift GRU. It not only bridges this distribution gap but also isolates the fine-grained texture of SD output against the interference of reprojection loss. Extensive experiments demonstrate that Jasmine achieves SoTA performance on the KITTI benchmark and exhibits superior zero-shot generalization across multiple datasets.
Integrating Biological and Machine Intelligence: Attention Mechanisms in Brain-Computer Interfaces
Feb 26, 2025With the rapid advancement of deep learning, attention mechanisms have become indispensable in electroencephalography (EEG) signal analysis, significantly enhancing Brain-Computer Interface (BCI) applications. This paper presents a comprehensive review of traditional and Transformer-based attention mechanisms, their embedding strategies, and their applications in EEG-based BCI, with a particular emphasis on multimodal data fusion. By capturing EEG variations across time, frequency, and spatial channels, attention mechanisms improve feature extraction, representation learning, and model robustness. These methods can be broadly categorized into traditional attention mechanisms, which typically integrate with convolutional and recurrent networks, and Transformer-based multi-head self-attention, which excels in capturing long-range dependencies. Beyond single-modality analysis, attention mechanisms also enhance multimodal EEG applications, facilitating effective fusion between EEG and other physiological or sensory data. Finally, we discuss existing challenges and emerging trends in attention-based EEG modeling, highlighting future directions for advancing BCI technology. This review aims to provide valuable insights for researchers seeking to leverage attention mechanisms for improved EEG interpretation and application.
DRL4AOI: A DRL Framework for Semantic-aware AOI Segmentation in Location-Based Services
Dec 06, 2024



In Location-Based Services (LBS), such as food delivery, a fundamental task is segmenting Areas of Interest (AOIs), aiming at partitioning the urban geographical spaces into non-overlapping regions. Traditional AOI segmentation algorithms primarily rely on road networks to partition urban areas. While promising in modeling the geo-semantics, road network-based models overlooked the service-semantic goals (e.g., workload equality) in LBS service. In this paper, we point out that the AOI segmentation problem can be naturally formulated as a Markov Decision Process (MDP), which gradually chooses a nearby AOI for each grid in the current AOI's border. Based on the MDP, we present the first attempt to generalize Deep Reinforcement Learning (DRL) for AOI segmentation, leading to a novel DRL-based framework called DRL4AOI. The DRL4AOI framework introduces different service-semantic goals in a flexible way by treating them as rewards that guide the AOI generation. To evaluate the effectiveness of DRL4AOI, we develop and release an AOI segmentation system. We also present a representative implementation of DRL4AOI - TrajRL4AOI - for AOI segmentation in the logistics service. It introduces a Double Deep Q-learning Network (DDQN) to gradually optimize the AOI generation for two specific semantic goals: i) trajectory modularity, i.e., maximize tightness of the trajectory connections within an AOI and the sparsity of connections between AOIs, ii) matchness with the road network, i.e., maximizing the matchness between AOIs and the road network. Quantitative and qualitative experiments conducted on synthetic and real-world data demonstrate the effectiveness and superiority of our method. The code and system is publicly available at https://github.com/Kogler7/AoiOpt.
Emotion-Agent: Unsupervised Deep Reinforcement Learning with Distribution-Prototype Reward for Continuous Emotional EEG Analysis
Aug 22, 2024Continuous electroencephalography (EEG) signals are widely used in affective brain-computer interface (aBCI) applications. However, not all continuously collected EEG signals are relevant or meaningful to the task at hand (e.g., wondering thoughts). On the other hand, manually labeling the relevant parts is nearly impossible due to varying engagement patterns across different tasks and individuals. Therefore, effectively and efficiently identifying the important parts from continuous EEG recordings is crucial for downstream BCI tasks, as it directly impacts the accuracy and reliability of the results. In this paper, we propose a novel unsupervised deep reinforcement learning framework, called Emotion-Agent, to automatically identify relevant and informative emotional moments from continuous EEG signals. Specifically, Emotion-Agent involves unsupervised deep reinforcement learning combined with a heuristic algorithm. We first use the heuristic algorithm to perform an initial global search and form prototype representations of the EEG signals, which facilitates the efficient exploration of the signal space and identify potential regions of interest. Then, we design distribution-prototype reward functions to estimate the interactions between samples and prototypes, ensuring that the identified parts are both relevant and representative of the underlying emotional states. Emotion-Agent is trained using Proximal Policy Optimization (PPO) to achieve stable and efficient convergence. Our experiments compare the performance with and without Emotion-Agent. The results demonstrate that selecting relevant and informative emotional parts before inputting them into downstream tasks enhances the accuracy and reliability of aBCI applications.
Digging into contrastive learning for robust depth estimation with diffusion models
Apr 17, 2024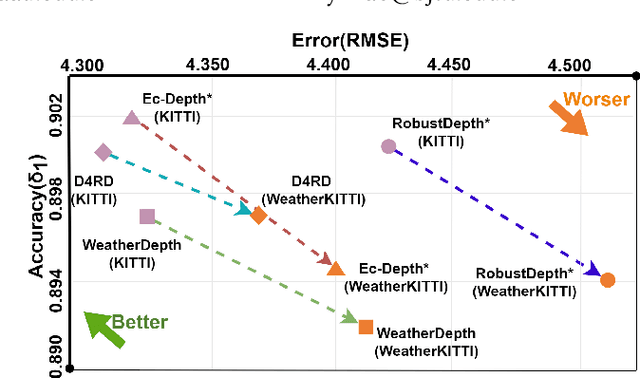
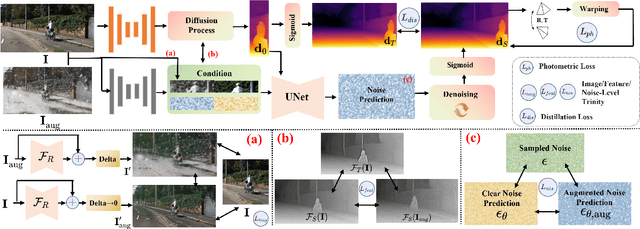
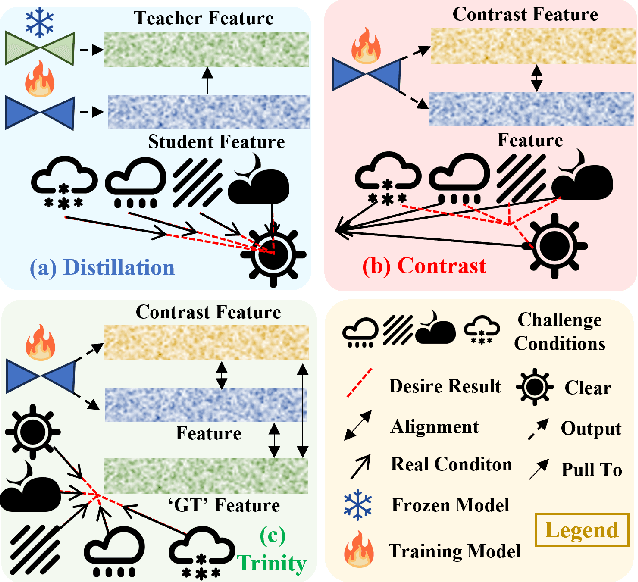

Recently, diffusion-based depth estimation methods have drawn widespread attention due to their elegant denoising patterns and promising performance. However, they are typically unreliable under adverse conditions prevalent in real-world scenarios, such as rainy, snowy, etc. In this paper, we propose a novel robust depth estimation method called D4RD, featuring a custom contrastive learning mode tailored for diffusion models to mitigate performance degradation in complex environments. Concretely, we integrate the strength of knowledge distillation into contrastive learning, building the `trinity' contrastive scheme. This scheme utilizes the sampled noise of the forward diffusion process as a natural reference, guiding the predicted noise in diverse scenes toward a more stable and precise optimum. Moreover, we extend noise-level trinity to encompass more generic feature and image levels, establishing a multi-level contrast to distribute the burden of robust perception across the overall network. Before addressing complex scenarios, we enhance the stability of the baseline diffusion model with three straightforward yet effective improvements, which facilitate convergence and remove depth outliers. Extensive experiments demonstrate that D4RD surpasses existing state-of-the-art solutions on synthetic corruption datasets and real-world weather conditions. The code for D4RD will be made available for further exploration and adoption.