 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADAG: Automatically Describing Attribution Graphs
Apr 08, 2026In language model interpretability research, \textbf{circuit tracing} aims to identify which internal features causally contributed to a particular output and how they affected each other, with the goal of explaining the computations underlying some behaviour. However, all prior circuit tracing work has relied on ad-hoc human interpretation of the role that each feature in the circuit plays, via manual inspection of data artifacts such as the dataset examples the component activates on. We introduce \textbf{ADAG}, an end-to-end pipeline for describing these attribution graphs which is fully automated. To achieve this, we introduce \textit{attribution profiles} which quantify the functional role of a feature via its input and output gradient effects. We then introduce a novel clustering algorithm for grouping features, and an LLM explainer--simulator setup which generates and scores natural-language explanations of the functional role of these feature groups. We run our system on known human-analysed circuit-tracing tasks and recover interpretable circuits, and further show ADAG can find steerable clusters which are responsible for a harmful advice jailbreak in Llama 3.1 8B Instruct.
Language Model Circuits Are Sparse in the Neuron Basis
Jan 30, 2026The high-level concepts that a neural network uses to perform computation need not be aligned to individual neurons (Smolensky, 1986). Language model interpretability research has thus turned to techniques such as \textit{sparse autoencoders} (SAEs) to decompose the neuron basis into more interpretable units of model computation, for tasks such as \textit{circuit tracing}. However, not all neuron-based representations are uninterpretable. For the first time, we empirically show that \textbf{MLP neurons are as sparse a feature basis as SAEs}. We use this finding to develop an end-to-end pipeline for circuit tracing on the MLP neuron basis, which locates causal circuitry on a variety of tasks using gradient-based attribution. On a standard subject-verb agreement benchmark (Marks et al., 2025), a circuit of $\approx 10^2$ MLP neurons is enough to control model behaviour. On the multi-hop city $\to$ state $\to$ capital task from Lindsey et al., 2025, we find a circuit in which small sets of neurons encode specific latent reasoning steps (e.g.~`map city to its state'), and can be steered to change the model's output. This work thus advances automated interpretability of language models without additional training costs.
LLMs Encode Harmfulness and Refusal Separately
Jul 16, 2025LLMs are trained to refuse harmful instructions, but do they truly understand harmfulness beyond just refusing? Prior work has shown that LLMs' refusal behaviors can be mediated by a one-dimensional subspace, i.e., a refusal direction. In this work, we identify a new dimension to analyze safety mechanisms in LLMs, i.e., harmfulness, which is encoded internally as a separate concept from refusal. There exists a harmfulness direction that is distinct from the refusal direction. As causal evidence, steering along the harmfulness direction can lead LLMs to interpret harmless instructions as harmful, but steering along the refusal direction tends to elicit refusal responses directly without reversing the model's judgment on harmfulness. Furthermore, using our identified harmfulness concept, we find that certain jailbreak methods work by reducing the refusal signals without reversing the model's internal belief of harmfulness. We also find that adversarially finetuning models to accept harmful instructions has minimal impact on the model's internal belief of harmfulness. These insights lead to a practical safety application: The model's latent harmfulness representation can serve as an intrinsic safeguard (Latent Guard) for detecting unsafe inputs and reducing over-refusals that is robust to finetuning attacks. For instance, our Latent Guard achieves performance comparable to or better than Llama Guard 3 8B, a dedicated finetuned safeguard model, across different jailbreak methods. Our findings suggest that LLMs' internal understanding of harmfulness is more robust than their refusal decision to diverse input instructions, offering a new perspective to study AI safety
Improved Representation Steering for Language Models
May 27, 2025Steering methods for language models (LMs) seek to provide fine-grained and interpretable control over model generations by variously changing model inputs, weights, or representations to adjust behavior. Recent work has shown that adjusting weights or representations is often less effective than steering by prompting, for instance when wanting to introduce or suppress a particular concept. We demonstrate how to improve representation steering via our new Reference-free Preference Steering (RePS), a bidirectional preference-optimization objective that jointly does concept steering and suppression. We train three parameterizations of RePS and evaluate them on AxBench, a large-scale model steering benchmark. On Gemma models with sizes ranging from 2B to 27B, RePS outperforms all existing steering methods trained with a language modeling objective and substantially narrows the gap with prompting -- while promoting interpretability and minimizing parameter count. In suppression, RePS matches the language-modeling objective on Gemma-2 and outperforms it on the larger Gemma-3 variants while remaining resilient to prompt-based jailbreaking attacks that defeat prompting. Overall, our results suggest that RePS provides an interpretable and robust alternative to prompting for both steering and suppression.
GIM: Improved Interpretability for Large Language Models
May 23, 2025Ensuring faithful interpretability in large language models is imperative for trustworthy and reliable AI. A key obstacle is self-repair, a phenomenon where networks compensate for reduced signal in one component by amplifying others, masking the true importance of the ablated component. While prior work attributes self-repair to layer normalization and back-up components that compensate for ablated components, we identify a novel form occurring within the attention mechanism, where softmax redistribution conceals the influence of important attention scores. This leads traditional ablation and gradient-based methods to underestimate the significance of all components contributing to these attention scores. We introduce Gradient Interaction Modifications (GIM), a technique that accounts for self-repair during backpropagation. Extensive experiments across multiple large language models (Gemma 2B/9B, LLAMA 1B/3B/8B, Qwen 1.5B/3B) and diverse tasks demonstrate that GIM significantly improves faithfulness over existing circuit identification and feature attribution methods. Our work is a significant step toward better understanding the inner mechanisms of LLMs, which is crucial for improving them and ensuring their safety. Our code is available at https://github.com/JoakimEdin/gim.
AxBench: Steering LLMs? Even Simple Baselines Outperform Sparse Autoencoders
Jan 29, 2025



Fine-grained steering of language model outputs is essential for safety and reliability. Prompting and finetuning are widely used to achieve these goals, but interpretability researchers have proposed a variety of representation-based techniques as well, including sparse autoencoders (SAEs), linear artificial tomography, supervised steering vectors, linear probes, and representation finetuning. At present, there is no benchmark for making direct comparisons between these proposals. Therefore, we introduce AxBench, a large-scale benchmark for steering and concept detection, and report experiments on Gemma-2-2B and 9B. For steering, we find that prompting outperforms all existing methods, followed by finetuning. For concept detection, representation-based methods such as difference-in-means, perform the best. On both evaluations, SAEs are not competitive. We introduce a novel weakly-supervised representational method (Rank-1 Representation Finetuning; ReFT-r1), which is competitive on both tasks while providing the interpretability advantages that prompting lacks. Along with AxBench, we train and publicly release SAE-scale feature dictionaries for ReFT-r1 and DiffMean.
Dancing in Chains: Reconciling Instruction Following and Faithfulness in Language Models
Jul 31, 2024Modern language models (LMs) need to follow human instructions while being faithful; yet, they often fail to achieve both. Here, we provide concrete evidence of a trade-off between instruction following (i.e., follow open-ended instructions) and faithfulness (i.e., ground responses in given context) when training LMs with these objectives. For instance, fine-tuning LLaMA-7B on instruction following datasets renders it less faithful. Conversely, instruction-tuned Vicuna-7B shows degraded performance at following instructions when further optimized on tasks that require contextual grounding. One common remedy is multi-task learning (MTL) with data mixing, yet it remains far from achieving a synergic outcome. We propose a simple yet effective method that relies on Rejection Sampling for Continued Self-instruction Tuning (ReSet), which significantly outperforms vanilla MTL. Surprisingly, we find that less is more, as training ReSet with high-quality, yet substantially smaller data (three-fold less) yields superior results. Our findings offer a better understanding of objective discrepancies in alignment training of LMs.
ReFT: Representation Finetuning for Language Models
Apr 08, 2024



Parameter-efficient fine-tuning (PEFT) methods seek to adapt large models via updates to a small number of weights. However, much prior interpretability work has shown that representations encode rich semantic information, suggesting that editing representations might be a more powerful alternative. Here, we pursue this hypothesis by developing a family of $\textbf{Representation Finetuning (ReFT)}$ methods. ReFT methods operate on a frozen base model and learn task-specific interventions on hidden representations. We define a strong instance of the ReFT family, Low-rank Linear Subspace ReFT (LoReFT). LoReFT is a drop-in replacement for existing PEFTs and learns interventions that are 10x-50x more parameter-efficient than prior state-of-the-art PEFTs. We showcase LoReFT on eight commonsense reasoning tasks, four arithmetic reasoning tasks, Alpaca-Eval v1.0, and GLUE. In all these evaluations, LoReFT delivers the best balance of efficiency and performance, and almost always outperforms state-of-the-art PEFTs. We release a generic ReFT training library publicly at https://github.com/stanfordnlp/pyreft.
Mapping the Increasing Use of LLMs in Scientific Papers
Apr 01, 2024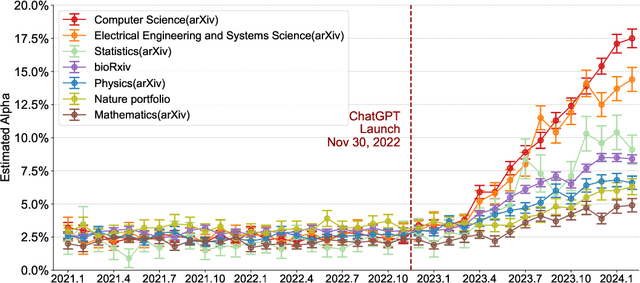
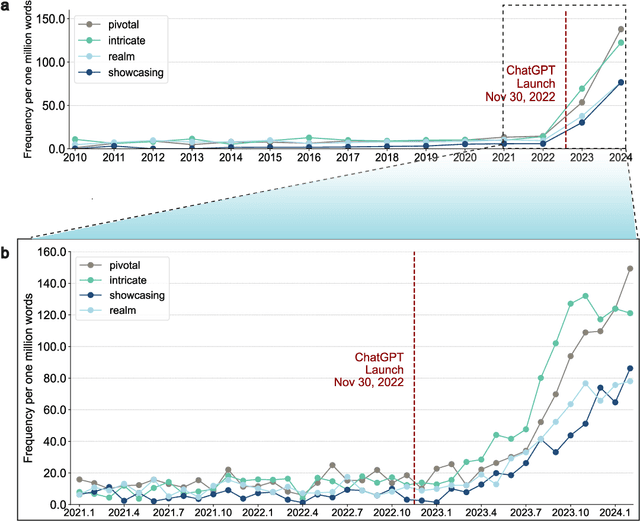
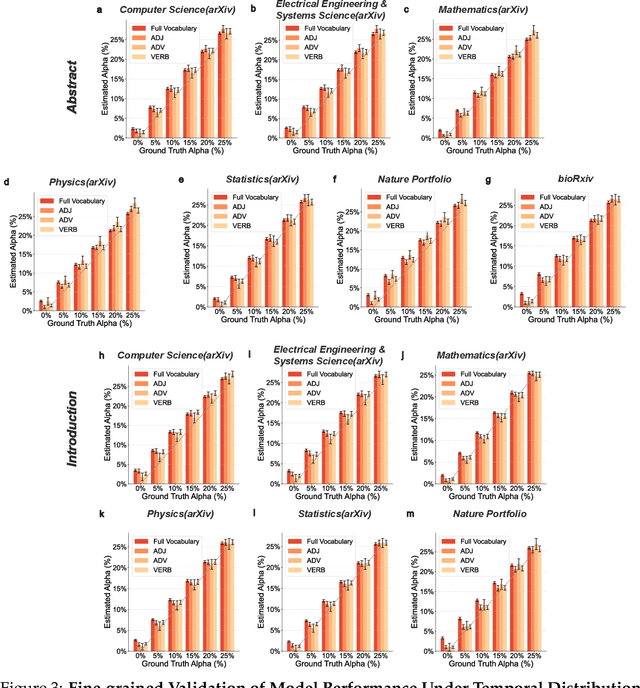
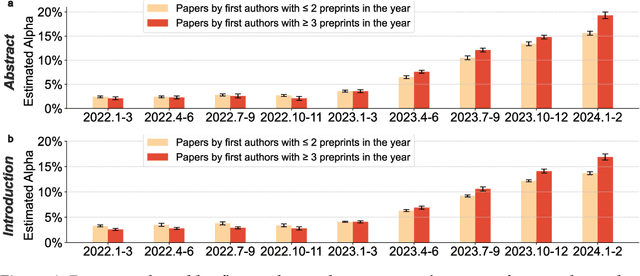
Scientific publishing lays the foundation of science by disseminating research findings, fostering collaboration, encouraging reproducibility, and ensuring that scientific knowledge is accessible, verifiable, and built upon over time. Recently, there has been immense speculation about how many people are using large language models (LLMs) like ChatGPT in their academic writing, and to what extent this tool might have an effect on global scientific practices. However, we lack a precise measure of the proportion of academic writing substantially modified or produced by LLMs. To address this gap, we conduct the first systematic, large-scale analysis across 950,965 papers published between January 2020 and February 2024 on the arXiv, bioRxiv, and Nature portfolio journals, using a population-level statistical framework to measure the prevalence of LLM-modified content over time. Our statistical estimation operates on the corpus level and is more robust than inference on individual instances. Our findings reveal a steady increase in LLM usage, with the largest and fastest growth observed in Computer Science papers (up to 17.5%). In comparison, Mathematics papers and the Nature portfolio showed the least LLM modification (up to 6.3%). Moreover, at an aggregate level, our analysis reveals that higher levels of LLM-modification are associated with papers whose first authors post preprints more frequently, papers in more crowded research areas, and papers of shorter lengths. Our findings suggests that LLMs are being broadly used in scientific writings.
pyvene: A Library for Understanding and Improving PyTorch Models via Interventions
Mar 12, 2024


Interventions on model-internal states are fundamental operations in many areas of AI, including model editing, steering, robustness, and interpretability. To facilitate such research, we introduce $\textbf{pyvene}$, an open-source Python library that supports customizable interventions on a range of different PyTorch modules. $\textbf{pyvene}$ supports complex intervention schemes with an intuitive configuration format, and its interventions can be static or include trainable parameters. We show how $\textbf{pyvene}$ provides a unified and extensible framework for performing interventions on neural models and sharing the intervened upon models with others. We illustrate the power of the library via interpretability analyses using causal abstraction and knowledge localization. We publish our library through Python Package Index (PyPI) and provide code, documentation, and tutorials at https://github.com/stanfordnlp/pyvene.