 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA global AI community requires language-diverse publishing
Aug 27, 2024In this provocation, we discuss the English dominance of the AI research community, arguing that the requirement for English language publishing upholds and reinforces broader regimes of extraction in AI. While large language models and machine translation have been celebrated as a way to break down barriers, we regard their use as a symptom of linguistic exclusion of scientists and potential readers. We propose alternative futures for a healthier publishing culture, organized around three themes: administering conferences in the languages of the country in which they are held, instructing peer reviewers not to adjudicate the language appropriateness of papers, and offering opportunities to publish and present in multiple languages. We welcome new translations of this piece. Please contact the authors if you would like to contribute one.
Mapping the Increasing Use of LLMs in Scientific Papers
Apr 01, 2024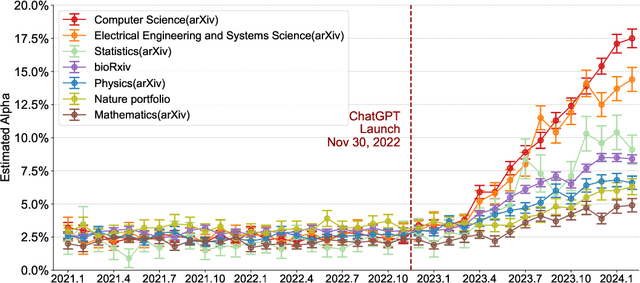
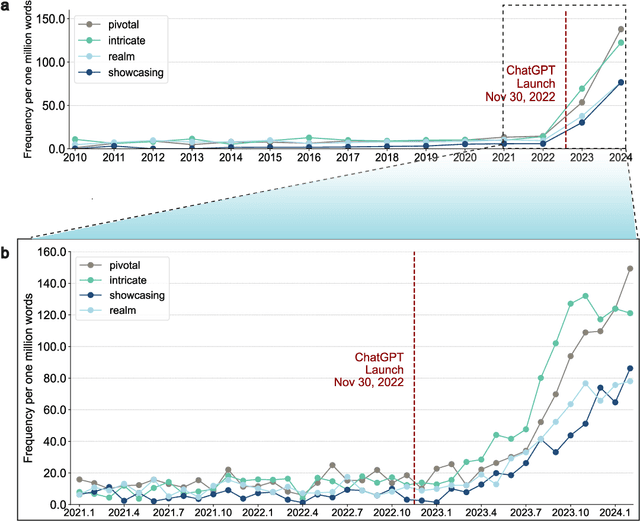
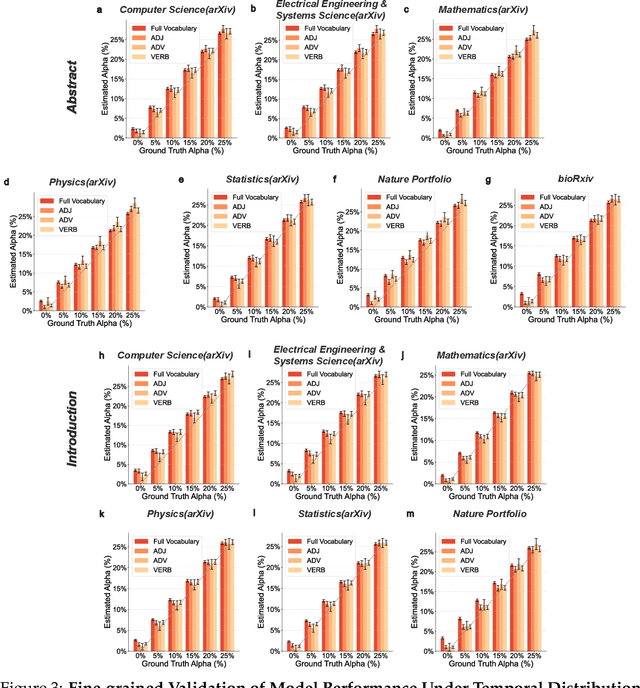
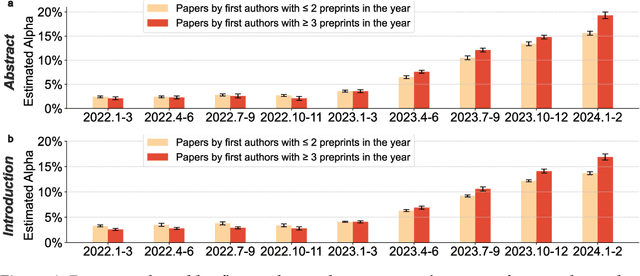
Scientific publishing lays the foundation of science by disseminating research findings, fostering collaboration, encouraging reproducibility, and ensuring that scientific knowledge is accessible, verifiable, and built upon over time. Recently, there has been immense speculation about how many people are using large language models (LLMs) like ChatGPT in their academic writing, and to what extent this tool might have an effect on global scientific practices. However, we lack a precise measure of the proportion of academic writing substantially modified or produced by LLMs. To address this gap, we conduct the first systematic, large-scale analysis across 950,965 papers published between January 2020 and February 2024 on the arXiv, bioRxiv, and Nature portfolio journals, using a population-level statistical framework to measure the prevalence of LLM-modified content over time. Our statistical estimation operates on the corpus level and is more robust than inference on individual instances. Our findings reveal a steady increase in LLM usage, with the largest and fastest growth observed in Computer Science papers (up to 17.5%). In comparison, Mathematics papers and the Nature portfolio showed the least LLM modification (up to 6.3%). Moreover, at an aggregate level, our analysis reveals that higher levels of LLM-modification are associated with papers whose first authors post preprints more frequently, papers in more crowded research areas, and papers of shorter lengths. Our findings suggests that LLMs are being broadly used in scientific writings.
Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews
Mar 11, 2024



We present an approach for estimating the fraction of text in a large corpus which is likely to be substantially modified or produced by a large language model (LLM). Our maximum likelihood model leverages expert-written and AI-generated reference texts to accurately and efficiently examine real-world LLM-use at the corpus level. We apply this approach to a case study of scientific peer review in AI conferences that took place after the release of ChatGPT: ICLR 2024, NeurIPS 2023, CoRL 2023 and EMNLP 2023. Our results suggest that between 6.5% and 16.9% of text submitted as peer reviews to these conferences could have been substantially modified by LLMs, i.e. beyond spell-checking or minor writing updates. The circumstances in which generated text occurs offer insight into user behavior: the estimated fraction of LLM-generated text is higher in reviews which report lower confidence, were submitted close to the deadline, and from reviewers who are less likely to respond to author rebuttals. We also observe corpus-level trends in generated text which may be too subtle to detect at the individual level, and discuss the implications of such trends on peer review. We call for future interdisciplinary work to examine how LLM use is changing our information and knowledge practices.
Pardon the Interruption: An Analysis of Gender and Turn-Taking in U.S. Supreme Court Oral Arguments
Sep 15, 2020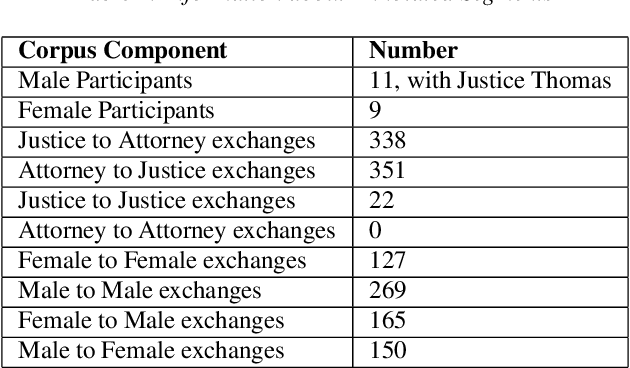
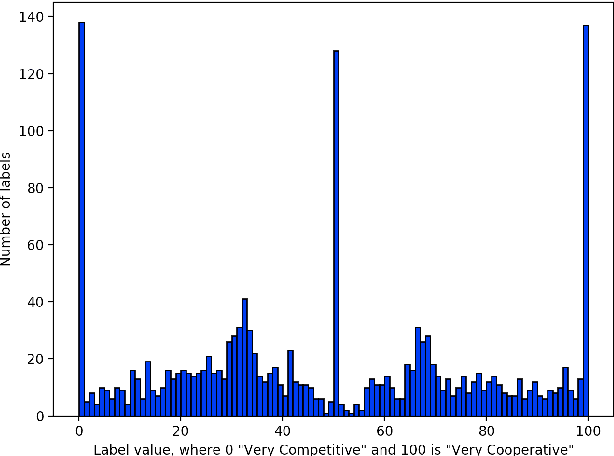
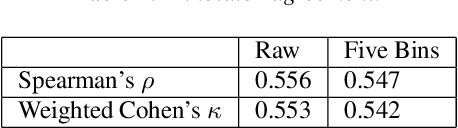
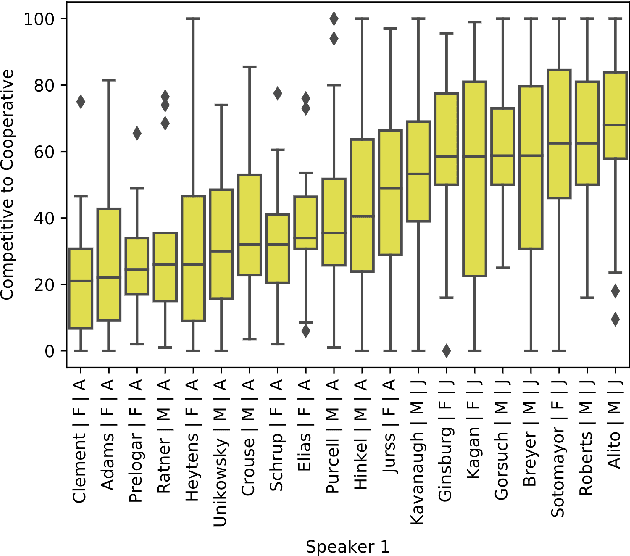
This study presents a corpus of turn changes between speakers in U.S. Supreme Court oral arguments. Each turn change is labeled on a spectrum of "cooperative" to "competitive" by a human annotator with legal experience in the United States. We analyze the relationship between speech features, the nature of exchanges, and the gender and legal role of the speakers. Finally, we demonstrate that the models can be used to predict the label of an exchange with moderate success. The automatic classification of the nature of exchanges indicates that future studies of turn-taking in oral arguments can rely on larger, unlabeled corpora.