 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Replication to Redesign: Exploring Pairwise Comparisons for LLM-Based Peer Review
Jun 12, 2025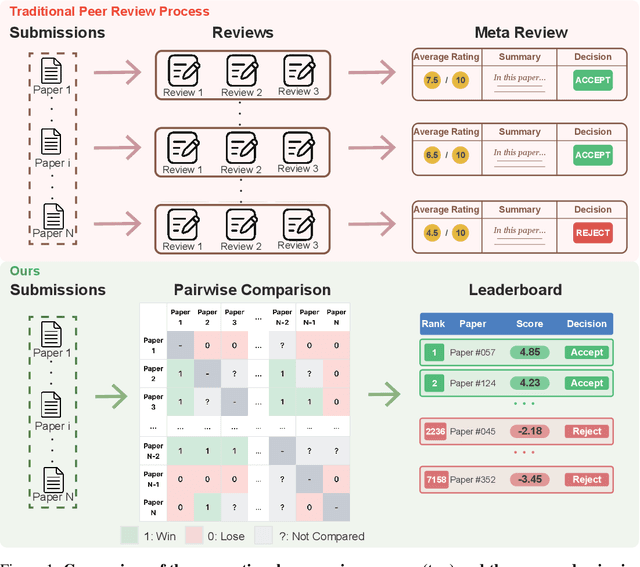
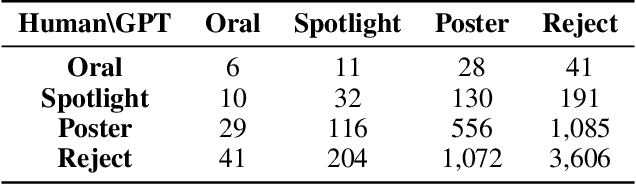
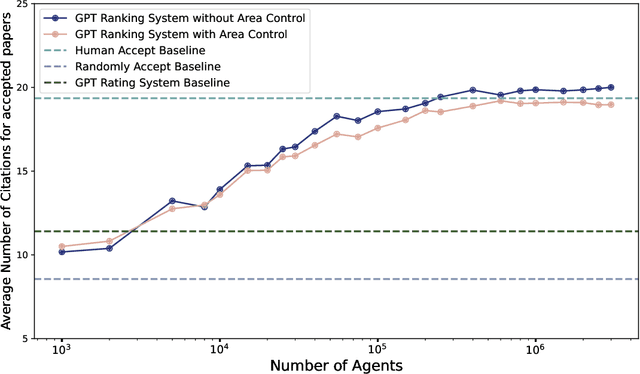
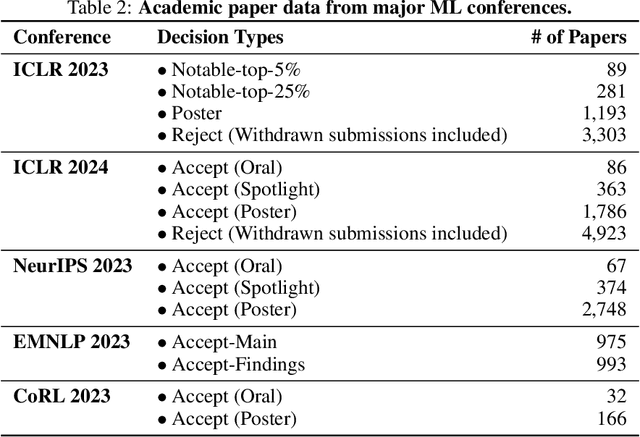
The advent of large language models (LLMs) offers unprecedented opportunities to reimagine peer review beyond the constraints of traditional workflows. Despite these opportunities, prior efforts have largely focused on replicating traditional review workflows with LLMs serving as direct substitutes for human reviewers, while limited attention has been given to exploring new paradigms that fundamentally rethink how LLMs can participate in the academic review process. In this paper, we introduce and explore a novel mechanism that employs LLM agents to perform pairwise comparisons among manuscripts instead of individual scoring. By aggregating outcomes from substantial pairwise evaluations, this approach enables a more accurate and robust measure of relative manuscript quality. Our experiments demonstrate that this comparative approach significantly outperforms traditional rating-based methods in identifying high-impact papers. However, our analysis also reveals emergent biases in the selection process, notably a reduced novelty in research topics and an increased institutional imbalance. These findings highlight both the transformative potential of rethinking peer review with LLMs and critical challenges that future systems must address to ensure equity and diversity.
A Theoretical Framework for Prompt Engineering: Approximating Smooth Functions with Transformer Prompts
Mar 26, 2025Prompt engineering has emerged as a powerful technique for guiding large language models (LLMs) toward desired responses, significantly enhancing their performance across diverse tasks. Beyond their role as static predictors, LLMs increasingly function as intelligent agents, capable of reasoning, decision-making, and adapting dynamically to complex environments. However, the theoretical underpinnings of prompt engineering remain largely unexplored. In this paper, we introduce a formal framework demonstrating that transformer models, when provided with carefully designed prompts, can act as a configurable computational system by emulating a ``virtual'' neural network during inference. Specifically, input prompts effectively translate into the corresponding network configuration, enabling LLMs to adjust their internal computations dynamically. Building on this construction, we establish an approximation theory for $\beta$-times differentiable functions, proving that transformers can approximate such functions with arbitrary precision when guided by appropriately structured prompts. Moreover, our framework provides theoretical justification for several empirically successful prompt engineering techniques, including the use of longer, structured prompts, filtering irrelevant information, enhancing prompt token diversity, and leveraging multi-agent interactions. By framing LLMs as adaptable agents rather than static models, our findings underscore their potential for autonomous reasoning and problem-solving, paving the way for more robust and theoretically grounded advancements in prompt engineering and AI agent design.
An Overview of Large Language Models for Statisticians
Feb 25, 2025



Large Language Models (LLMs) have emerged as transformative tools in artificial intelligence (AI), exhibiting remarkable capabilities across diverse tasks such as text generation, reasoning, and decision-making. While their success has primarily been driven by advances in computational power and deep learning architectures, emerging problems -- in areas such as uncertainty quantification, decision-making, causal inference, and distribution shift -- require a deeper engagement with the field of statistics. This paper explores potential areas where statisticians can make important contributions to the development of LLMs, particularly those that aim to engender trustworthiness and transparency for human users. Thus, we focus on issues such as uncertainty quantification, interpretability, fairness, privacy, watermarking and model adaptation. We also consider possible roles for LLMs in statistical analysis. By bridging AI and statistics, we aim to foster a deeper collaboration that advances both the theoretical foundations and practical applications of LLMs, ultimately shaping their role in addressing complex societal challenges.
Predictions as Surrogates: Revisiting Surrogate Outcomes in the Age of AI
Jan 16, 2025We establish a formal connection between the decades-old surrogate outcome model in biostatistics and economics and the emerging field of prediction-powered inference (PPI). The connection treats predictions from pre-trained models, prevalent in the age of AI, as cost-effective surrogates for expensive outcomes. Building on the surrogate outcomes literature, we develop recalibrated prediction-powered inference, a more efficient approach to statistical inference than existing PPI proposals. Our method departs from the existing proposals by using flexible machine learning techniques to learn the optimal ``imputed loss'' through a step we call recalibration. Importantly, the method always improves upon the estimator that relies solely on the data with available true outcomes, even when the optimal imputed loss is estimated imperfectly, and it achieves the smallest asymptotic variance among PPI estimators if the estimate is consistent. Computationally, our optimization objective is convex whenever the loss function that defines the target parameter is convex. We further analyze the benefits of recalibration, both theoretically and numerically, in several common scenarios where machine learning predictions systematically deviate from the outcome of interest. We demonstrate significant gains in effective sample size over existing PPI proposals via three applications leveraging state-of-the-art machine learning/AI models.
Scaling Laws for the Value of Individual Data Points in Machine Learning
May 30, 2024



Recent works have shown that machine learning models improve at a predictable rate with the total amount of training data, leading to scaling laws that describe the relationship between error and dataset size. These scaling laws can help design a model's training dataset, but they typically take an aggregate view of the data by only considering the dataset's size. We introduce a new perspective by investigating scaling behavior for the value of individual data points: we find that a data point's contribution to model's performance shrinks predictably with the size of the dataset in a log-linear manner. Interestingly, there is significant variability in the scaling exponent among different data points, indicating that certain points are more valuable in small datasets while others are relatively more useful as a part of large datasets. We provide learning theory to support our scaling law, and we observe empirically that it holds across diverse model classes. We further propose a maximum likelihood estimator and an amortized estimator to efficiently learn the individualized scaling behaviors from a small number of noisy observations per data point. Using our estimators, we provide insights into factors that influence the scaling behavior of different data points. Finally, we demonstrate applications of the individualized scaling laws to data valuation and data subset selection. Overall, our work represents a first step towards understanding and utilizing scaling properties for the value of individual data points.
Mapping the Increasing Use of LLMs in Scientific Papers
Apr 01, 2024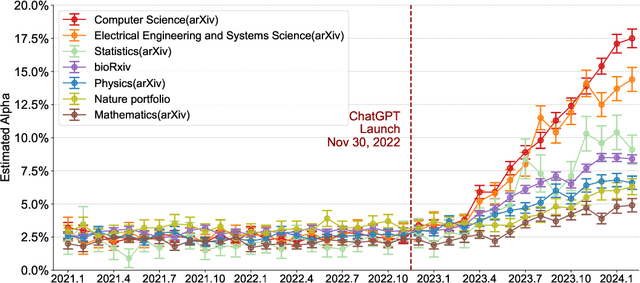
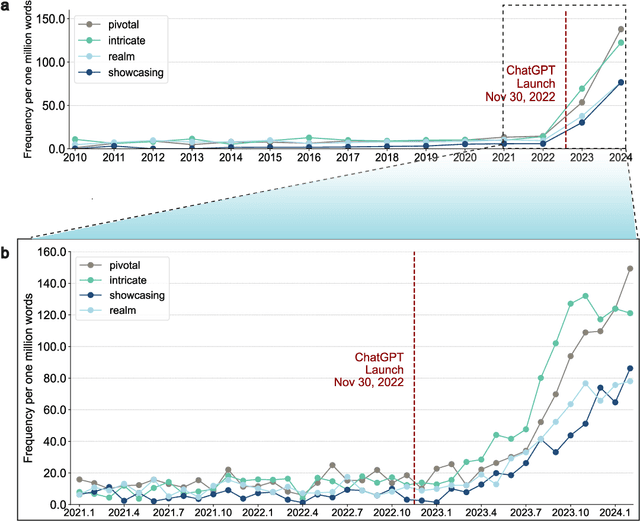
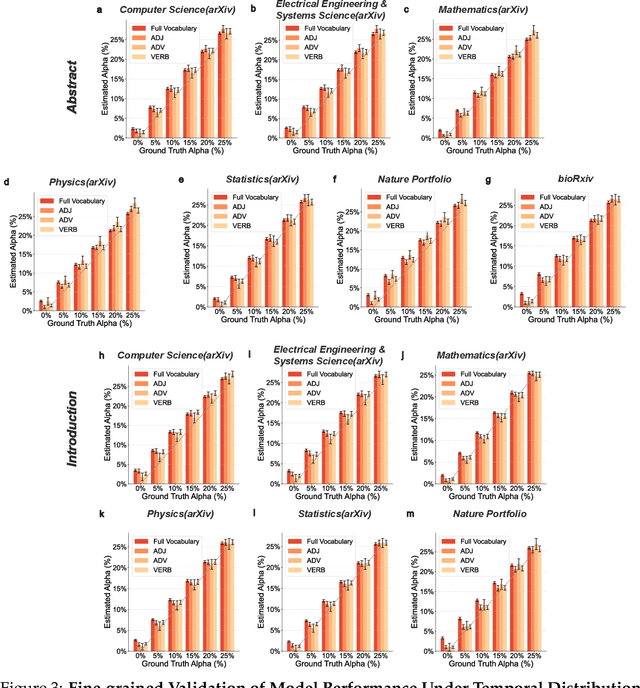
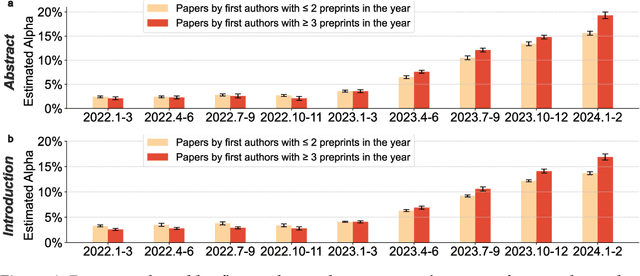
Scientific publishing lays the foundation of science by disseminating research findings, fostering collaboration, encouraging reproducibility, and ensuring that scientific knowledge is accessible, verifiable, and built upon over time. Recently, there has been immense speculation about how many people are using large language models (LLMs) like ChatGPT in their academic writing, and to what extent this tool might have an effect on global scientific practices. However, we lack a precise measure of the proportion of academic writing substantially modified or produced by LLMs. To address this gap, we conduct the first systematic, large-scale analysis across 950,965 papers published between January 2020 and February 2024 on the arXiv, bioRxiv, and Nature portfolio journals, using a population-level statistical framework to measure the prevalence of LLM-modified content over time. Our statistical estimation operates on the corpus level and is more robust than inference on individual instances. Our findings reveal a steady increase in LLM usage, with the largest and fastest growth observed in Computer Science papers (up to 17.5%). In comparison, Mathematics papers and the Nature portfolio showed the least LLM modification (up to 6.3%). Moreover, at an aggregate level, our analysis reveals that higher levels of LLM-modification are associated with papers whose first authors post preprints more frequently, papers in more crowded research areas, and papers of shorter lengths. Our findings suggests that LLMs are being broadly used in scientific writings.
Model-Agnostic Covariate-Assisted Inference on Partially Identified Causal Effects
Oct 12, 2023



Many causal estimands are only partially identifiable since they depend on the unobservable joint distribution between potential outcomes. Stratification on pretreatment covariates can yield sharper partial identification bounds; however, unless the covariates are discrete with relatively small support, this approach typically requires consistent estimation of the conditional distributions of the potential outcomes given the covariates. Thus, existing approaches may fail under model misspecification or if consistency assumptions are violated. In this study, we propose a unified and model-agnostic inferential approach for a wide class of partially identified estimands, based on duality theory for optimal transport problems. In randomized experiments, our approach can wrap around any estimates of the conditional distributions and provide uniformly valid inference, even if the initial estimates are arbitrarily inaccurate. Also, our approach is doubly robust in observational studies. Notably, this property allows analysts to use the multiplier bootstrap to select covariates and models without sacrificing validity even if the true model is not included. Furthermore, if the conditional distributions are estimated at semiparametric rates, our approach matches the performance of an oracle with perfect knowledge of the outcome model. Finally, we propose an efficient computational framework, enabling implementation on many practical problems in causal inference.
Understanding Multimodal Contrastive Learning and Incorporating Unpaired Data
Feb 23, 2023


Language-supervised vision models have recently attracted great attention in computer vision. A common approach to build such models is to use contrastive learning on paired data across the two modalities, as exemplified by Contrastive Language-Image Pre-Training (CLIP). In this paper, under linear representation settings, (i) we initiate the investigation of a general class of nonlinear loss functions for multimodal contrastive learning (MMCL) including CLIP loss and show its connection to singular value decomposition (SVD). Namely, we show that each step of loss minimization by gradient descent can be seen as performing SVD on a contrastive cross-covariance matrix. Based on this insight, (ii) we analyze the performance of MMCL. We quantitatively show that the feature learning ability of MMCL can be better than that of unimodal contrastive learning applied to each modality even under the presence of wrongly matched pairs. This characterizes the robustness of MMCL to noisy data. Furthermore, when we have access to additional unpaired data, (iii) we propose a new MMCL loss that incorporates additional unpaired datasets. We show that the algorithm can detect the ground-truth pairs and improve performance by fully exploiting unpaired datasets. The performance of the proposed algorithm was verified by numerical experiments.
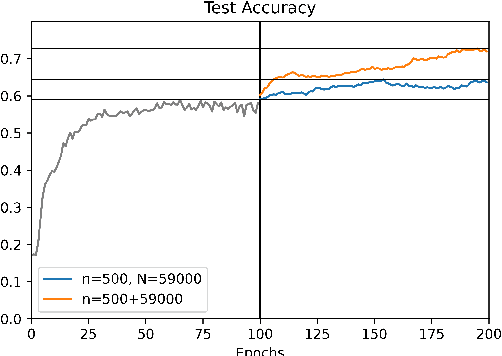
Importance Tempering: Group Robustness for Overparameterized Models
Sep 27, 2022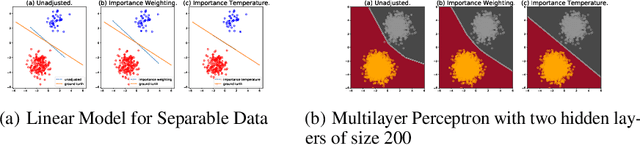

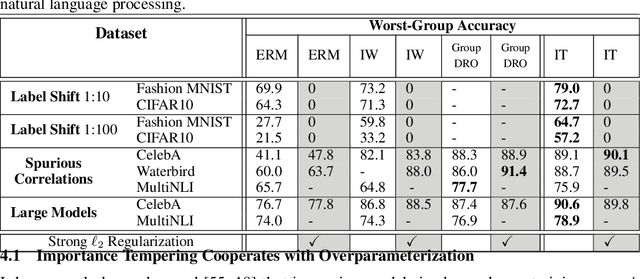

Although overparameterized models have shown their success on many machine learning tasks, the accuracy could drop on the testing distribution that is different from the training one. This accuracy drop still limits applying machine learning in the wild. At the same time, importance weighting, a traditional technique to handle distribution shifts, has been demonstrated to have less or even no effect on overparameterized models both empirically and theoretically. In this paper, we propose importance tempering to improve the decision boundary and achieve consistently better results for overparameterized models. Theoretically, we justify that the selection of group temperature can be different under label shift and spurious correlation setting. At the same time, we also prove that properly selected temperatures can extricate the minority collapse for imbalanced classification. Empirically, we achieve state-of-the-art results on worst group classification tasks using importance tempering.
An Unconstrained Layer-Peeled Perspective on Neural Collapse
Oct 06, 2021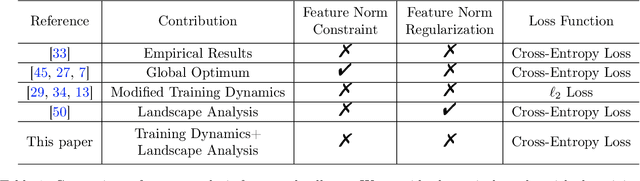
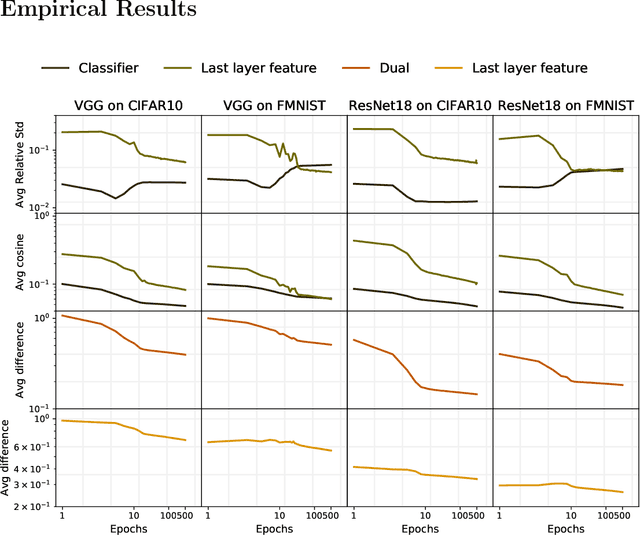
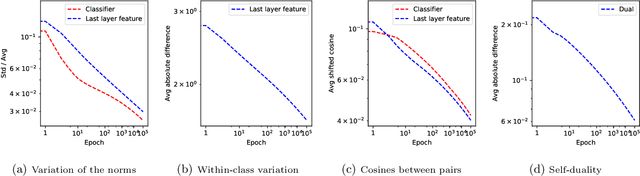
Neural collapse is a highly symmetric geometric pattern of neural networks that emerges during the terminal phase of training, with profound implications on the generalization performance and robustness of the trained networks. To understand how the last-layer features and classifiers exhibit this recently discovered implicit bias, in this paper, we introduce a surrogate model called the unconstrained layer-peeled model (ULPM). We prove that gradient flow on this model converges to critical points of a minimum-norm separation problem exhibiting neural collapse in its global minimizer. Moreover, we show that the ULPM with the cross-entropy loss has a benign global landscape for its loss function, which allows us to prove that all the critical points are strict saddle points except the global minimizers that exhibit the neural collapse phenomenon. Empirically, we show that our results also hold during the training of neural networks in real-world tasks when explicit regularization or weight decay is not used.