 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Reinforcement: When Reward Is Sparse, It's Better to Be Dense
Oct 08, 2025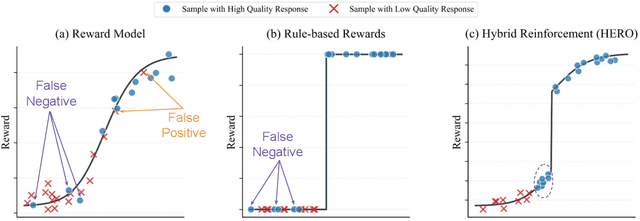
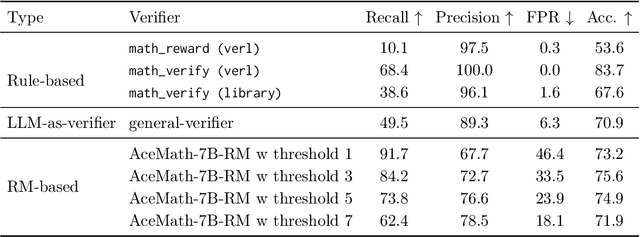
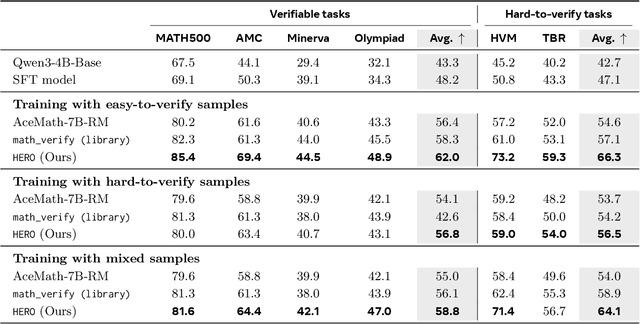
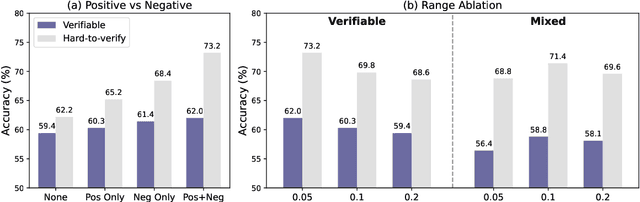
Post-training for reasoning of large language models (LLMs) increasingly relies on verifiable rewards: deterministic checkers that provide 0-1 correctness signals. While reliable, such binary feedback is brittle--many tasks admit partially correct or alternative answers that verifiers under-credit, and the resulting all-or-nothing supervision limits learning. Reward models offer richer, continuous feedback, which can serve as a complementary supervisory signal to verifiers. We introduce HERO (Hybrid Ensemble Reward Optimization), a reinforcement learning framework that integrates verifier signals with reward-model scores in a structured way. HERO employs stratified normalization to bound reward-model scores within verifier-defined groups, preserving correctness while refining quality distinctions, and variance-aware weighting to emphasize challenging prompts where dense signals matter most. Across diverse mathematical reasoning benchmarks, HERO consistently outperforms RM-only and verifier-only baselines, with strong gains on both verifiable and hard-to-verify tasks. Our results show that hybrid reward design retains the stability of verifiers while leveraging the nuance of reward models to advance reasoning.
Bridging Offline and Online Reinforcement Learning for LLMs
Jun 26, 2025We investigate the effectiveness of reinforcement learning methods for finetuning large language models when transitioning from offline to semi-online to fully online regimes for both verifiable and non-verifiable tasks. Our experiments cover training on verifiable math as well as non-verifiable instruction following with a set of benchmark evaluations for both. Across these settings, we extensively compare online and semi-online Direct Preference Optimization and Group Reward Policy Optimization objectives, and surprisingly find similar performance and convergence between these variants, which all strongly outperform offline methods. We provide a detailed analysis of the training dynamics and hyperparameter selection strategies to achieve optimal results. Finally, we show that multi-tasking with verifiable and non-verifiable rewards jointly yields improved performance across both task types.
An Overview of Large Language Models for Statisticians
Feb 25, 2025



Large Language Models (LLMs) have emerged as transformative tools in artificial intelligence (AI), exhibiting remarkable capabilities across diverse tasks such as text generation, reasoning, and decision-making. While their success has primarily been driven by advances in computational power and deep learning architectures, emerging problems -- in areas such as uncertainty quantification, decision-making, causal inference, and distribution shift -- require a deeper engagement with the field of statistics. This paper explores potential areas where statisticians can make important contributions to the development of LLMs, particularly those that aim to engender trustworthiness and transparency for human users. Thus, we focus on issues such as uncertainty quantification, interpretability, fairness, privacy, watermarking and model adaptation. We also consider possible roles for LLMs in statistical analysis. By bridging AI and statistics, we aim to foster a deeper collaboration that advances both the theoretical foundations and practical applications of LLMs, ultimately shaping their role in addressing complex societal challenges.
NaturalReasoning: Reasoning in the Wild with 2.8M Challenging Questions
Feb 18, 2025Scaling reasoning capabilities beyond traditional domains such as math and coding is hindered by the lack of diverse and high-quality questions. To overcome this limitation, we introduce a scalable approach for generating diverse and challenging reasoning questions, accompanied by reference answers. We present NaturalReasoning, a comprehensive dataset comprising 2.8 million questions that span multiple domains, including STEM fields (e.g., Physics, Computer Science), Economics, Social Sciences, and more. We demonstrate the utility of the questions in NaturalReasoning through knowledge distillation experiments which show that NaturalReasoning can effectively elicit and transfer reasoning capabilities from a strong teacher model. Furthermore, we demonstrate that NaturalReasoning is also effective for unsupervised self-training using external reward models or self-rewarding.