 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCulture Cartography: Mapping the Landscape of Cultural Knowledge
Oct 31, 2025To serve global users safely and productively, LLMs need culture-specific knowledge that might not be learned during pre-training. How do we find such knowledge that is (1) salient to in-group users, but (2) unknown to LLMs? The most common solutions are single-initiative: either researchers define challenging questions that users passively answer (traditional annotation), or users actively produce data that researchers structure as benchmarks (knowledge extraction). The process would benefit from mixed-initiative collaboration, where users guide the process to meaningfully reflect their cultures, and LLMs steer the process towards more challenging questions that meet the researcher's goals. We propose a mixed-initiative methodology called CultureCartography. Here, an LLM initializes annotation with questions for which it has low-confidence answers, making explicit both its prior knowledge and the gaps therein. This allows a human respondent to fill these gaps and steer the model towards salient topics through direct edits. We implement this methodology as a tool called CultureExplorer. Compared to a baseline where humans answer LLM-proposed questions, we find that CultureExplorer more effectively produces knowledge that leading models like DeepSeek R1 and GPT-4o are missing, even with web search. Fine-tuning on this data boosts the accuracy of Llama-3.1-8B by up to 19.2% on related culture benchmarks.
NaturalReasoning: Reasoning in the Wild with 2.8M Challenging Questions
Feb 18, 2025Scaling reasoning capabilities beyond traditional domains such as math and coding is hindered by the lack of diverse and high-quality questions. To overcome this limitation, we introduce a scalable approach for generating diverse and challenging reasoning questions, accompanied by reference answers. We present NaturalReasoning, a comprehensive dataset comprising 2.8 million questions that span multiple domains, including STEM fields (e.g., Physics, Computer Science), Economics, Social Sciences, and more. We demonstrate the utility of the questions in NaturalReasoning through knowledge distillation experiments which show that NaturalReasoning can effectively elicit and transfer reasoning capabilities from a strong teacher model. Furthermore, we demonstrate that NaturalReasoning is also effective for unsupervised self-training using external reward models or self-rewarding.
LLM Pretraining with Continuous Concepts
Feb 12, 2025



Next token prediction has been the standard training objective used in large language model pretraining. Representations are learned as a result of optimizing for token-level perplexity. We propose Continuous Concept Mixing (CoCoMix), a novel pretraining framework that combines discrete next token prediction with continuous concepts. Specifically, CoCoMix predicts continuous concepts learned from a pretrained sparse autoencoder and mixes them into the model's hidden state by interleaving with token hidden representations. Through experiments on multiple benchmarks, including language modeling and downstream reasoning tasks, we show that CoCoMix is more sample efficient and consistently outperforms standard next token prediction, knowledge distillation and inserting pause tokens. We find that combining both concept learning and interleaving in an end-to-end framework is critical to performance gains. Furthermore, CoCoMix enhances interpretability and steerability by allowing direct inspection and modification of the predicted concept, offering a transparent way to guide the model's internal reasoning process.
Explore Theory of Mind: Program-guided adversarial data generation for theory of mind reasoning
Dec 12, 2024



Do large language models (LLMs) have theory of mind? A plethora of papers and benchmarks have been introduced to evaluate if current models have been able to develop this key ability of social intelligence. However, all rely on limited datasets with simple patterns that can potentially lead to problematic blind spots in evaluation and an overestimation of model capabilities. We introduce ExploreToM, the first framework to allow large-scale generation of diverse and challenging theory of mind data for robust training and evaluation. Our approach leverages an A* search over a custom domain-specific language to produce complex story structures and novel, diverse, yet plausible scenarios to stress test the limits of LLMs. Our evaluation reveals that state-of-the-art LLMs, such as Llama-3.1-70B and GPT-4o, show accuracies as low as 0% and 9% on ExploreToM-generated data, highlighting the need for more robust theory of mind evaluation. As our generations are a conceptual superset of prior work, fine-tuning on our data yields a 27-point accuracy improvement on the classic ToMi benchmark (Le et al., 2019). ExploreToM also enables uncovering underlying skills and factors missing for models to show theory of mind, such as unreliable state tracking or data imbalances, which may contribute to models' poor performance on benchmarks.
Self-Consistency Preference Optimization
Nov 06, 2024



Self-alignment, whereby models learn to improve themselves without human annotation, is a rapidly growing research area. However, existing techniques often fail to improve complex reasoning tasks due to the difficulty of assigning correct rewards. An orthogonal approach that is known to improve correctness is self-consistency, a method applied at inference time based on multiple sampling in order to find the most consistent answer. In this work, we extend the self-consistency concept to help train models. We thus introduce self-consistency preference optimization (ScPO), which iteratively trains consistent answers to be preferred over inconsistent ones on unsupervised new problems. We show ScPO leads to large improvements over conventional reward model training on reasoning tasks such as GSM8K and MATH, closing the gap with supervised training with gold answers or preferences, and that combining ScPO with standard supervised learning improves results even further. On ZebraLogic, ScPO finetunes Llama-3 8B to be superior to Llama-3 70B, Gemma-2 27B, and Claude-3 Haiku.
Quantifying Adaptability in Pre-trained Language Models with 500 Tasks
Dec 06, 2021
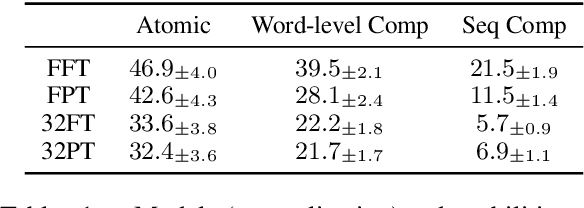


When a neural language model (LM) is adapted to perform a new task, what aspects of the task predict the eventual performance of the model? In NLP, systematic features of LM generalization to individual examples are well characterized, but systematic aspects of LM adaptability to new tasks are not nearly as well understood. We present a large-scale empirical study of the features and limits of LM adaptability using a new benchmark, TaskBench500, built from 500 procedurally generated sequence modeling tasks. These tasks combine core aspects of language processing, including lexical semantics, sequence processing, memorization, logical reasoning, and world knowledge. Using TaskBench500, we evaluate three facets of adaptability, finding that: (1) adaptation procedures differ dramatically in their ability to memorize small datasets; (2) within a subset of task types, adaptation procedures exhibit compositional adaptability to complex tasks; and (3) failure to match training label distributions is explained by mismatches in the intrinsic difficulty of predicting individual labels. Our experiments show that adaptability to new tasks, like generalization to new examples, can be systematically described and understood, and we conclude with a discussion of additional aspects of adaptability that could be studied using the new benchmark.